文章来源:Kang, Y., Leng, X., Liao, Y., & Zheng, S. (2024). Information disclosure, spillovers, and knowledge accumulation. China Economic Review, 102135.
01
引言
2016年,《中国工业经济》杂志开始在官网公布论文的数据与代码,开国内经济学界数据公开之先河。近期,四位来自中国大陆的学者借助双重差分和文本分析方法对《中国工业经济》的数据公开政策进行了系统性研究,结果发现:数据公开之后,《中国工业经济》论文的下载量和引用量双双上涨;且引用它们的论文与被引论文之间的相似度显著提高,说明数据公开有利于产生新知识。此外,研究还发现,数据公开的好处主要由层次略低的期刊发表者所享有,表明数据公开不仅可以促进知识传播与扩大,还有利于促进学术界的平等化。
政策背景
02
《中国工业经济》由中国社科院工业经济研究所主办,是中国产业经济、企业管理领域的核心刊物,被视为中国的五大刊(Top5)之一。自2016年11月开始,除个别涉密数据外,《中国工业经济》要求在该期刊发表的实证论文都需要提供相应数据和代码。
《中国工业经济》的数据公开政策具有以下三个优点:一、研究内容、作者群体和读者群斗都主要集中在中国大陆,可以消除研究话题、文章背景、作者背景等因素的干扰。二、与爱思唯尔、斯普林格等盈利性出版机构不同的是,《中国工业经济》的主管单位属于非盈利机构,以其作为研究对象可以避免期刊追求多个目标所带来的内生性问题。三、在文章的样本期内(2010-2021年),仅有《中国工业经济》一本期刊公布了数据和代码,这一事实使得作者便于引入DID方法。
03
研究设计
文章的数据主要来自于中国知网。在回归分析中,作者用到了两组不同结构的数据:一是论文数据。作者从知网上收集了2010-2021年间发表于包括《中国工业经济》在内的12本期刊上的所有文章,并记录了这些文章的标题、作者、摘要、发表日期、引用数、下载数等信息,共计13814篇文章。
二是论文对数据。基于前述处理得到的文章数据,作者进一步根据每篇文章的引用-被引关系构建了一份论文对数据,并计算了两篇论文之间的相似度用于后续的机制分析,共计得到577493对论文组合。
针对第一组数据,作者构建了如下识别模型:
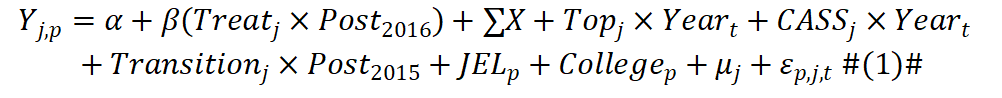
其中,Y为被解释变量,包括论文下载量和引用量,Treat为处理组变量,表示期刊是否为《中国工业经济》,Post为时间变量,2016年及之后赋值为1。其余为控制变量与固定效应。
针对第二组数据,作者则使用如下识别模型:
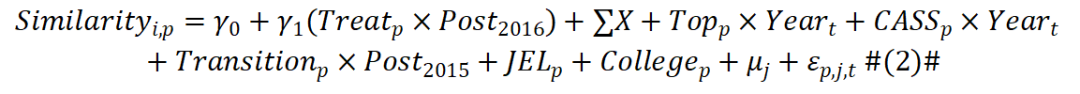
其中,Similarity为两篇论文之间的相似度,Treat为处理组变量,表示被引论文是否发表于《中国工业经济》,Post为时间变量,2016年及之后赋值为1。其余为控制变量与固定效应。
基准回归
04
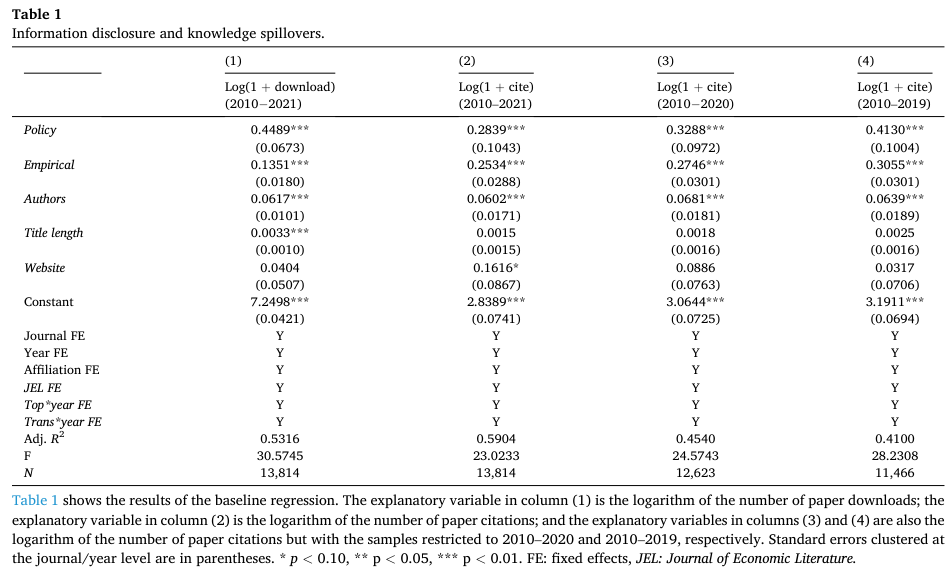
下表汇报了模型(1)的估计结果,第一列的被解释变量为下载量,第二至四列为引用量,可以发现,数据公开可以显著增加论文的下载量与引用量,平均而言,下载量增加了57%,而引用量则增加了33%。
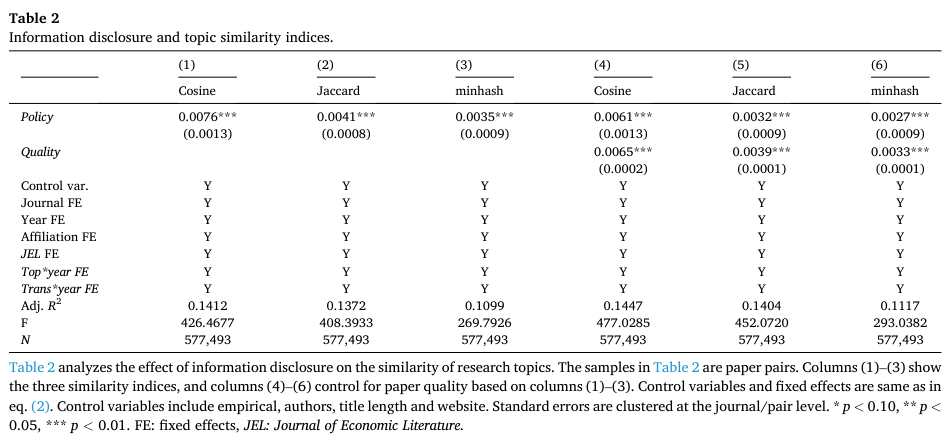
下表汇报了模型(2),即论文对数据的估计结果,第一至三列结果显示,使用不同的相似度衡量指标后,所得结果都显示数据公开可以显著提升引用论文与被引论文之间的相似度。且这一结果在控制论文指标之后,依然保持不变。
上述结果显示,数据公开在促进知识的流动与传播的同时,也产生了新的知识。
稳健性检验
05
随后,作者使用事件分析法进行平行趋势假设检验。结果如下图所示,左图为下载量,右图为引用量。在数据公开政策实施前,处理组与控制组之间的趋势不存在显著差异,政策实施之后,两者开始出现显著分化,符合平行趋势假设。
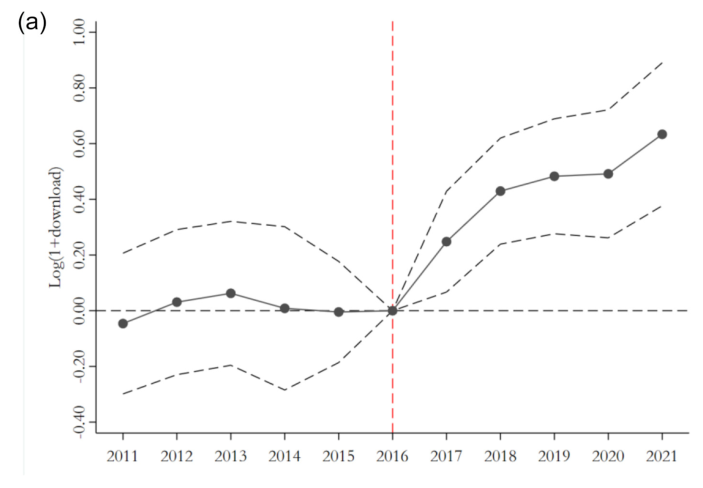
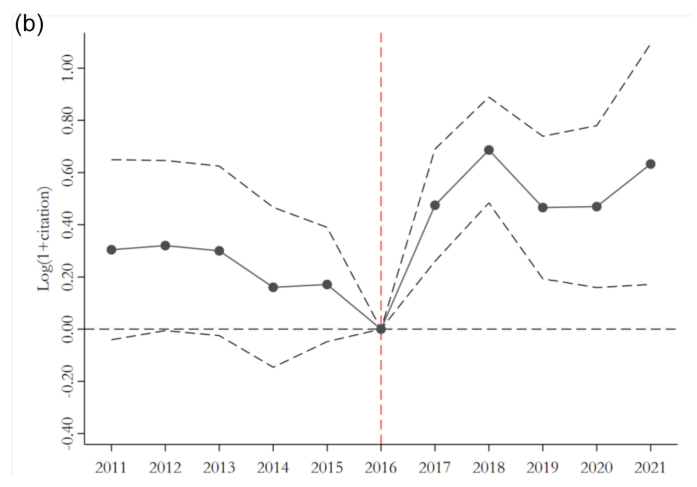
作者还汇报了相似度的平行趋势检验结果。如下图所示,发现同样满足平行趋势假设。
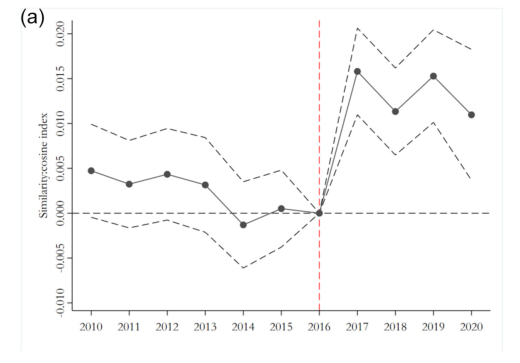
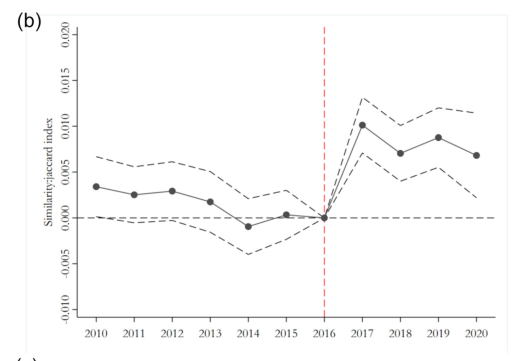
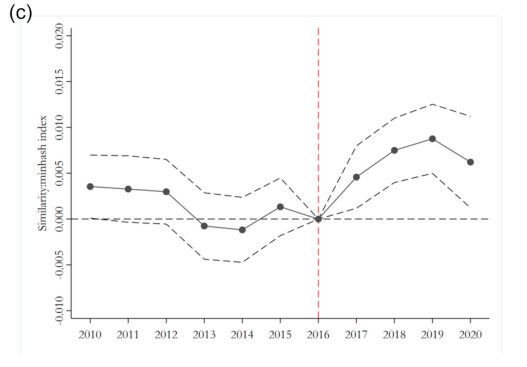
06
机制分析
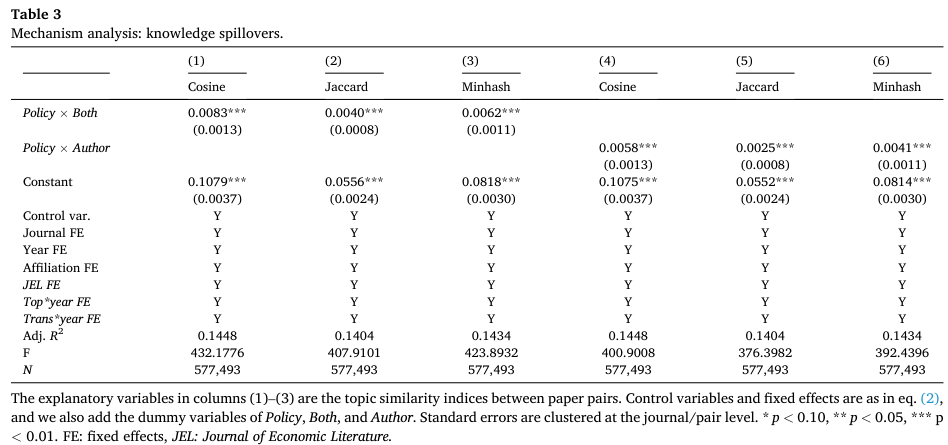
部分实证论文出于保密限制,仅公布了代码,而未公布数据。如果知识溢出的机制存在,那么这部分论文的溢出效应会较弱。作者据此构建了代表文章是否完整公布数据和代码的虚拟变量,并引入三重差分模型进行分析。下表的第一至三列结果显示,若文章完整公布了数据和代码,则引用论文与被引论文之间的相似度更高。
作者数量也可能与论文传播有关,因此作者根据作者数量是否高于中位数构建了一个虚拟变量,并同样引入三重差分模型。结果如下表第四至六列所示,拥有更多作者数量的文章具有更大的影响力,表现在论文对之间具有更高的相似度。
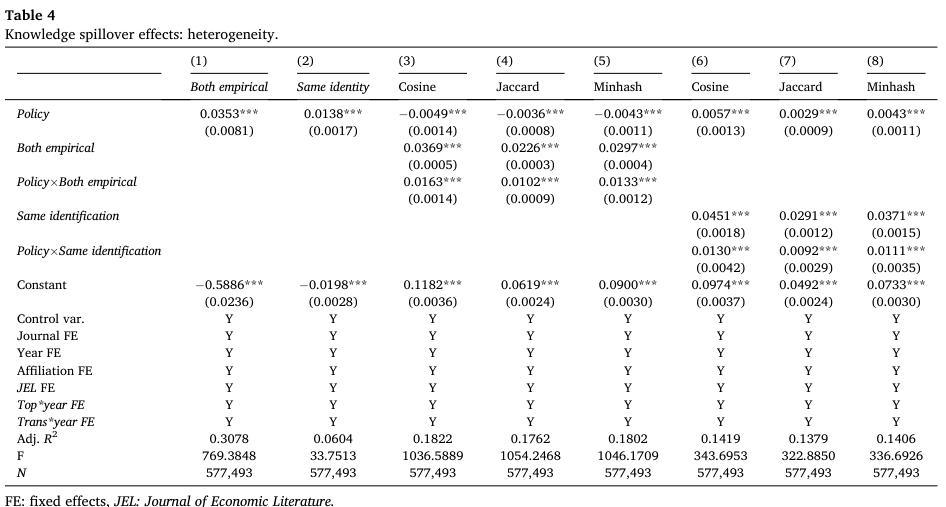
随后,作者还提供了更加直接的证据以支持知识溢出这一机制。下表第一、二列的解释变量分别为论文对是否都为实证论文,和是否使用了相同的识别策略。结果显示,数据公开之后,论文对都为实证论文和使用相同实证方法的概率显著提高。
第三至八列的结果则发现,若两篇论文都为实证论文或使用相同实证方法时,其相似度也显著更高。这一结果进一步证实了知识溢出效应的存在。
进一步分析
07
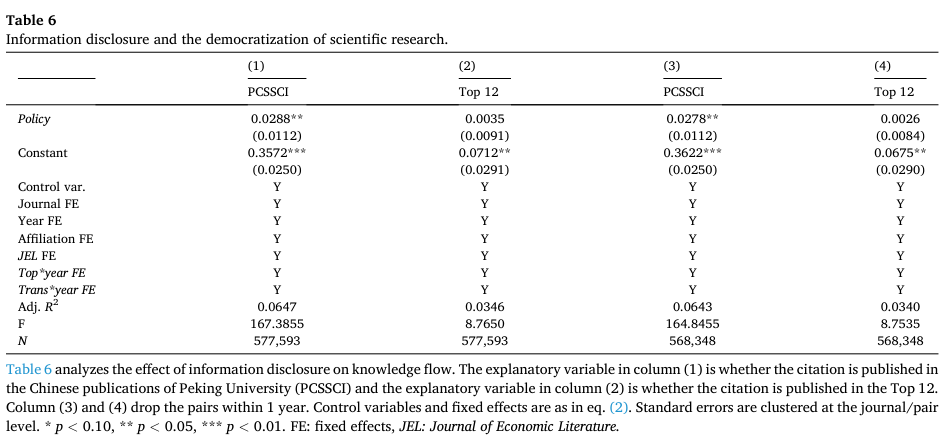
最后,作者还进一步分析了数据公开对后学者发表质量的影响。如下图所示,第一列结果发现,数据公开之后,引用《中国工业经济》的论文更可能被北大核心(PCSSCI)上的期刊所引用,但对是否被顶尖刊物(Top12)所引用则不显著,说明数据公开也增加了低排名刊物的引用量。考虑到多数低排名刊物发表者的作者背景,这显示出数据公开在推动学术平等中的重要意义。
08
结论
近年来,学术期刊的数据公开似乎成了一种趋势。作者使用《中国工业经济》的数据公开政策作为一项准实验,分析了数据公开的实际效果。结果发现,数据公开不仅促进了现有知识的传播与新知识的产生,且相较于优势群体,弱势群体能够更好的享受到数据公开带来的益处,进而促进学术界的平等化。
Abstract
In 2016, the China Industrial Economics (CIE) journal made a decision to publish the data and codes of relevant papers. We conducted an analysis to examine the causal effects between information disclosure and knowledge accumulation based on this policy change. The results showed a significant increase in both downloads and citations of CIE papers after implementing this policy. Furthermore, we observed that there was a notable increase in similarity between CIE papers and those that cited them, indicating that information disclosure contributes to generating new knowledge.Additionally, our findings revealed that the knowledge spillover effects of CIE papers were primarily driven by increased citations from second-tier journals. This suggests that information disclosure facilitates the dissemination and diffusion of existing knowledge, providing valuable learning opportunities for scientists who have limited access to resources.These findings highlight how information disclosure supports publication and knowledge production processes while promoting greater democratization of science within scientific communities.
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}