原文信息:
Eulerich, M., Sanatizadeh, A., Vakilzadeh, H., & Wood, D. A. (2024). Is it all hype? ChatGPT’s performance and disruptive potential in the accounting and auditing industries. Review of Accounting Studies, 29(3), 2318-2349.
01
研究背景
在生成式人工智能技术迅猛发展的推动下,ChatGPT等大语言模型在多个领域展现出强大的语言理解与推理能力。然而,在高度结构化、专业性极强的会计与审计行业,其真实能力仍存争议。会计工作不仅要求准确掌握财务规范与专业知识,更依赖于严密的逻辑判断和合规性推理。ChatGPT是否具备通过权威专业考试、胜任此类任务的能力,成为亟待实证验证的重要问题。
针对这一研究空白,发表在国际会计顶刊Review of Accounting Studies的论文《Is it all hype? ChatGPT’s performance and disruptive potential in the accounting and auditing industries》以注册会计师(CPA)、管理会计师(CMA)、内部审计师(CIA)和注册报税师(EA)四项代表性资格考试为测试场景,系统评估了GPT-3.5与GPT-4在原始与增强提示下的答题表现。通过标准化考试这一严肃设定,文章揭示了ChatGPT在财会专业场景中的胜任力边界与潜在颠覆性,并为未来会计教育与行业结构重塑提供了实证依据。
数据来源与实验设计
02
本研究以财会领域四项国际权威考试作为评估载体,系统测试了ChatGPT在专业场景下的真实表现。所选考试包括注册会计师、注册管理会计师、注册内部审计师和注册报税师,由美国相关官方机构统一命题,广泛用于衡量从业者在财务报告、内部控制、审计合规和税务规划等方面的专业水平。
研究团队共整理收集了760道历年考试样题,涵盖四类考试的主流题型与核心知识模块。为确保模型评估结果的可比性与可信度,所有题目均为英文原文输入,且去除图片、表格等不适合文本处理的部分。在测试阶段,研究分别采用GPT-3.5与GPT-4两种模型,并引入三种不同的提示策略:零样本(Zero-shot)、少样本(Few-shot)以及推理链与行动结合的ReAct提示,以全面考察模型在不同条件下的推理能力与稳定性。
每道题目的作答结果依据正确与否进行二元评分,最终通过平均答题准确率衡量模型性能。这一实验设计充分模拟了标准化考试的情境,为后续分析ChatGPT在财会任务中可能具备的“替代性”或“补充性”提供了坚实基础。
03
模型表现与结果分析
本研究首先评估了ChatGPT-3.5在四项权威财会考试各模块中的表现。如表2所示,该模型的答题准确率介于EA-P1(37.3%)和CIA-P3(68.0%)之间,全部低于相应考试的及格线,表明其在专业财会任务中尚未具备“独立应考”的能力。总体平均准确率为53.1%,进一步印证了模型当前能力的现实边界。此外,GPT-3.5在税务类题目上表现最差,而在审计类问题上相对更为稳健,这与以往文献结论一致。
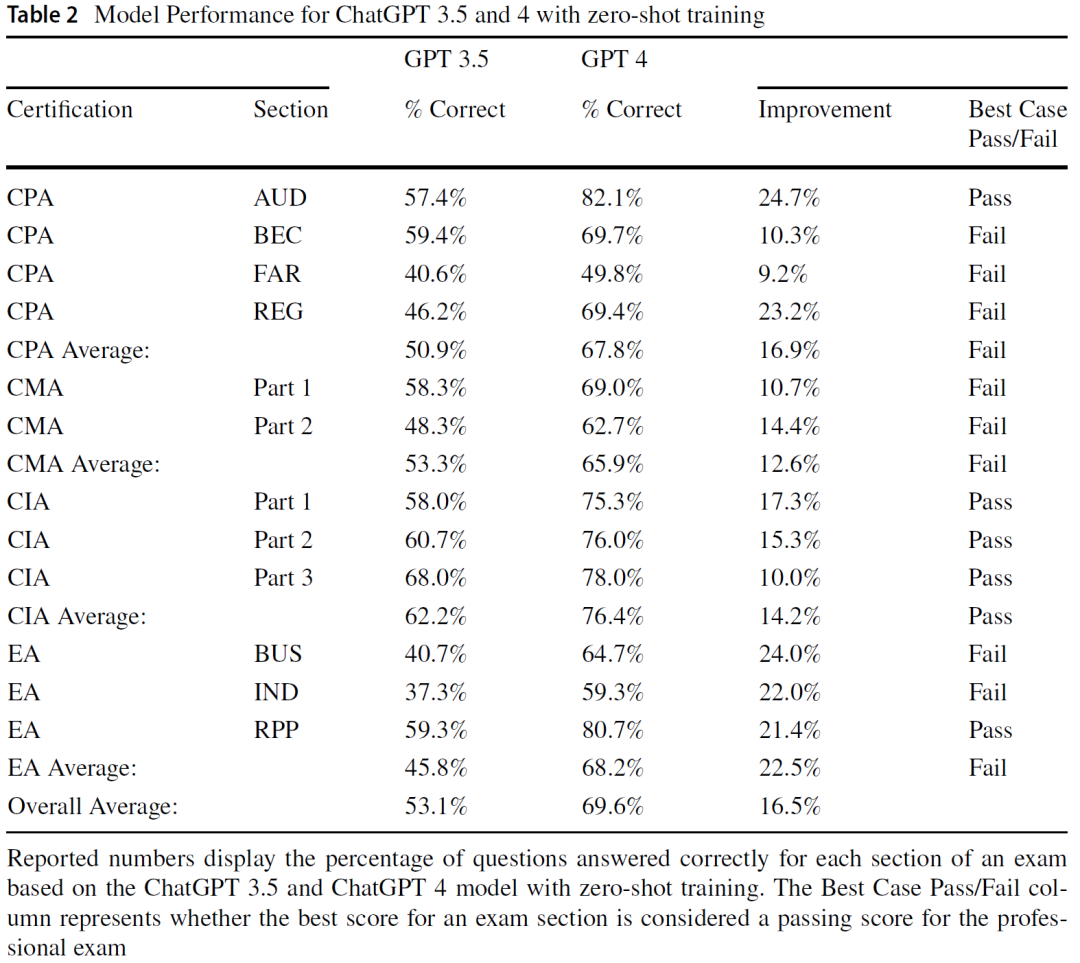
当模型更替为GPT-4后,其整体表现显著提升。表2展示了GPT-4在各考试模块中的正确率相较GPT-3.5提升幅度介于9.2%至24.7%之间,平均提升16.5%,已有5个子模块达到或超过通过标准,其中包括CIA考试的全部三个部分。尽管如此,GPT-4仍未完全通过CPA、CMA和EA等其余考试的所有模块。
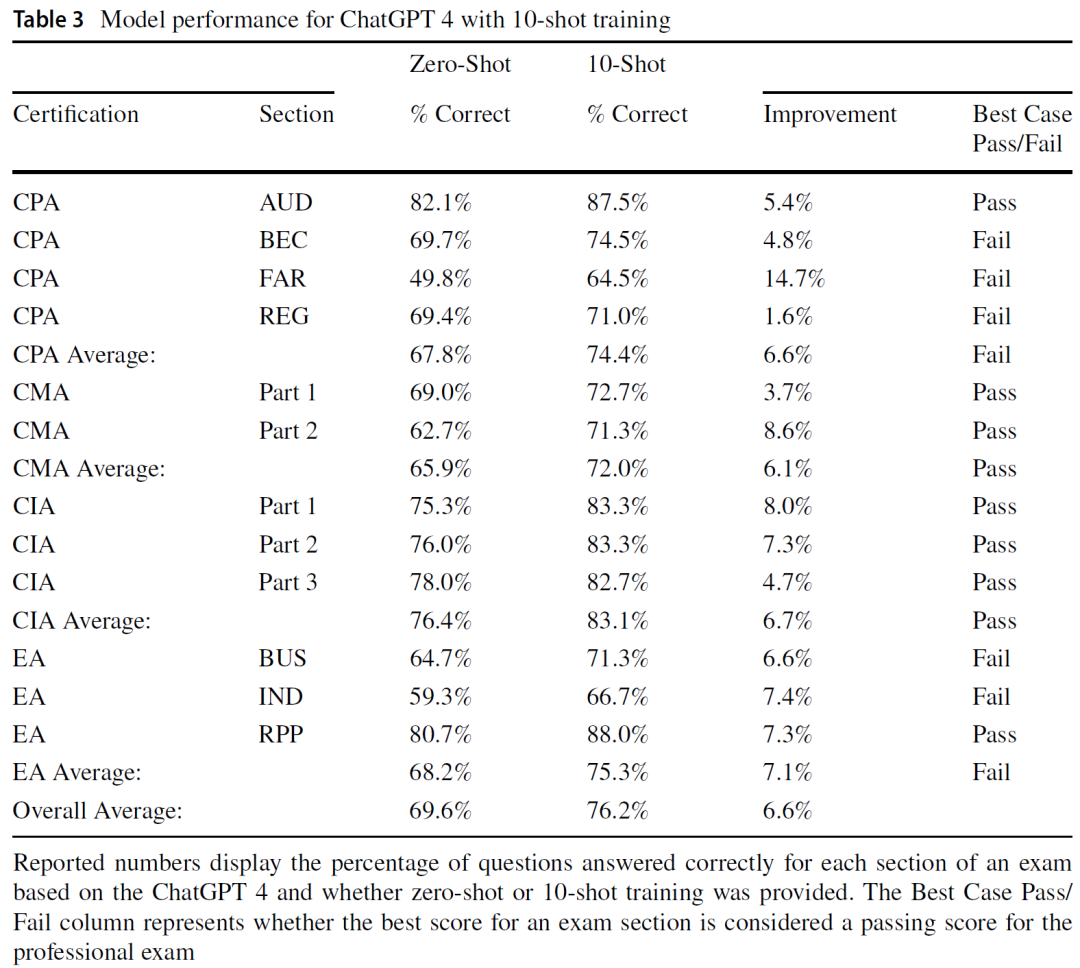
进一步引入提示工程策略后,模型性能得到持续优化。表3基于GPT-4模型,比较了Zero-Shot与10-Shot提示策略的差异。结果显示,通过引导输入十个范例,模型平均答题准确率提高了6.6%,使其在CMA两个模块中也达到通过标准,反映出少样本学习对模型泛化能力的正向促进。
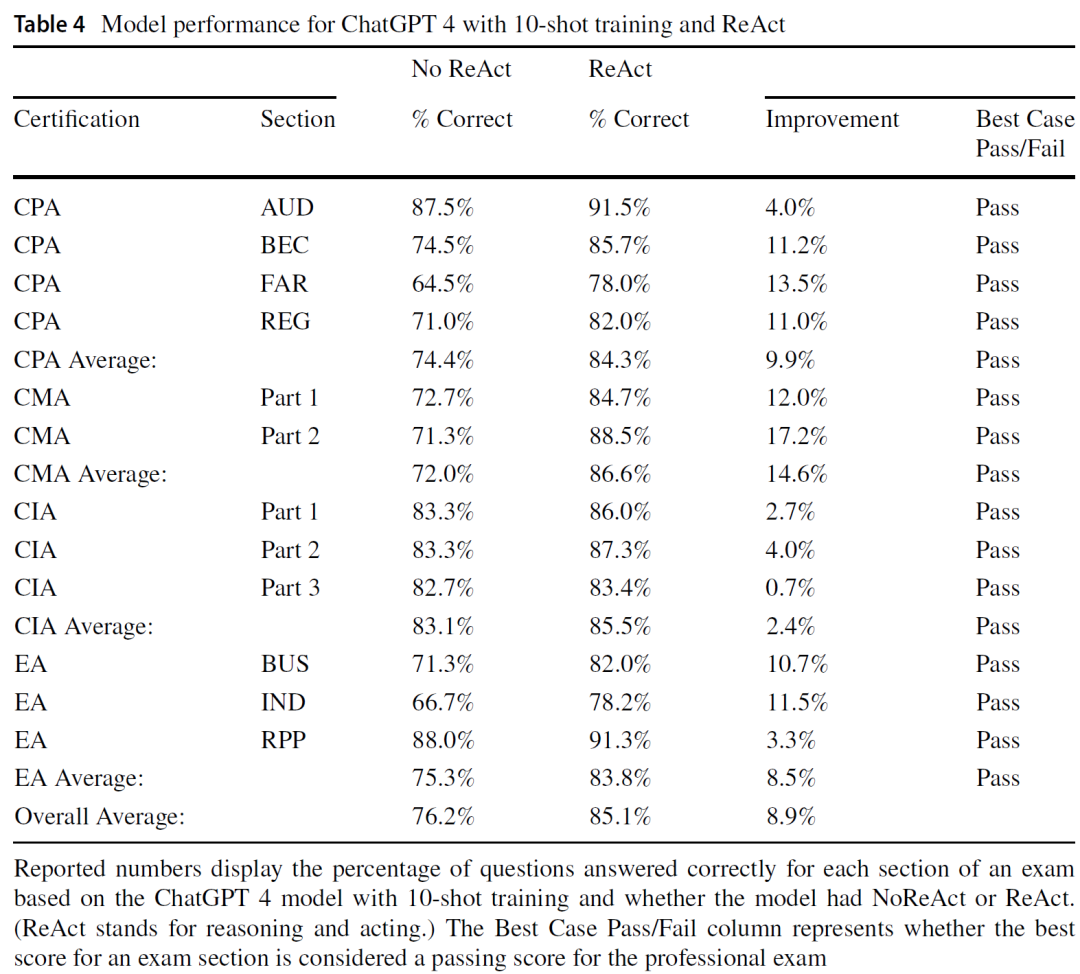
在此基础上,研究进一步引入ReAct提示方法,即结合推理链与动作执行能力,如表4所示。加入ReAct机制后,GPT-4的整体表现再次提升8.9%,显著超越通过线,首次实现所有考试模块的全线通过。分析指出,该策略对复杂计算类题目的提升最为显著,尤其是模型在配备“计算器”能力后,克服了此前在财务与税务计算方面的重大短板。
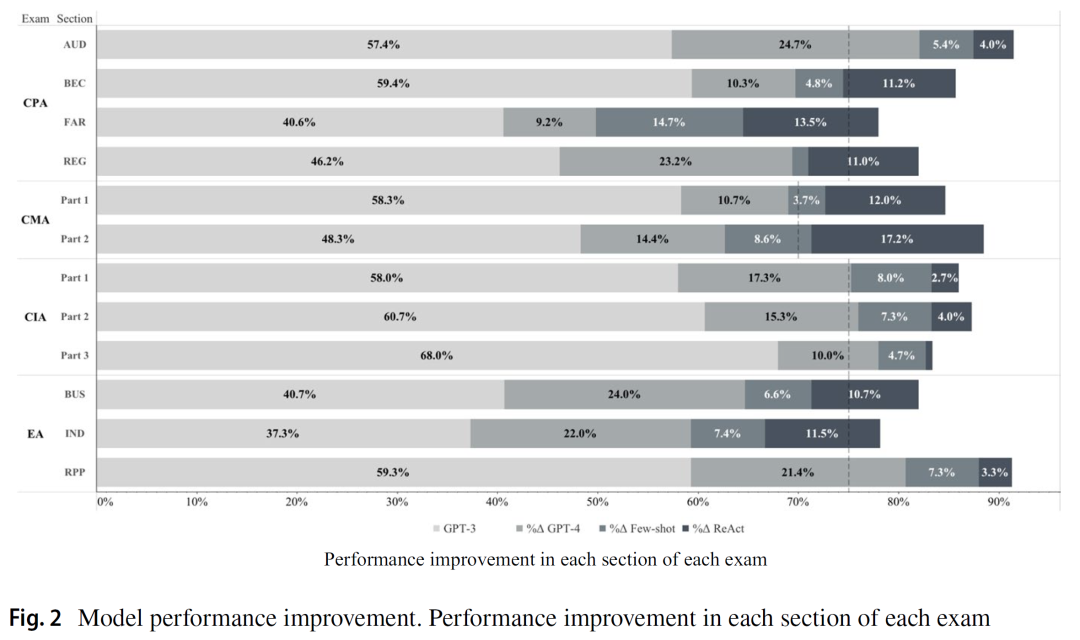
图2以可视化方式呈现了模型性能随不同策略叠加的提升轨迹。图中明确展示,从基础版本出发,随着模型版本升级、提示策略增强、能力扩展,答题准确率逐步跃升,最终使模型在所有考试中超过了既定的合格门槛。这一过程不仅展示了语言模型在财会专业任务中的潜在替代性,也为未来模型在实践中辅助决策提供了可信证据支撑。
ChatGPT对会计可能造成的颠覆
04
围绕ChatGPT对会计领域的潜在颠覆性影响展开,作者重点讨论其在教育与实务中的应用。生成式人工智能已广泛融入会计教育实践,从虚拟助教“TA-bot”到教材问答系统,显著提升了教学效率与交互质量,同时显著降低了成本。教师和学生利用ChatGPT编写教学案例、构建网页、生成图像与习题,不仅增强了教学内容的丰富性,也推动了教育内容生产方式的变革。此外,ChatGPT也正被探索用于论文写作、文献综述、定性分析等学术任务,为研究效率与质量带来显著提升。尽管AI辅助评分尚处于实验阶段,但其在教育评估和个性化反馈方面展现出潜力,未来有望实现大规模定制化学习。
在会计与商业实务中,生成式AI的应用已从基础文案撰写、邮件翻译等任务,扩展至审计、合规、薪资服务、文本分析等复杂工作。大型会计师事务所和金融机构,如PwC、EY与Bloomberg,已率先构建专用大模型与AI平台以支持合同分析、税务分类、薪酬管理与金融文本处理,显著提升业务效率与服务质量。然而,中小会计事务所因资源限制,在部署生成式AI方面仍面临门槛,可能加剧行业技术不平衡。尽管目前尚无直接证据表明AI取代了会计工作,但企业已在考虑减少人力,并将自动化节省的成本转向非审计服务,可能对行业盈利结构与职业路径产生深远影响。
尽管生成式AI在提升效率、降低成本与扩大服务边界方面表现出强大潜力,但其带来的挑战亦不容忽视,包括专业判断力退化、数据隐私与伦理合规风险、模型幻觉问题以及监管滞后等。文章强调,ChatGPT的影响并非“被高估”,反而可能“被低估”。在技术快速迭代、实际应用不断深入的背景下,会计教育与实务需积极转型,以适应人工智能驱动的新范式。
05
总结
在人工智能持续重塑商业与会计实践的浪潮中,生成式AI已具备完成高水平会计任务的潜力。研究表明,ChatGPT已能通过关键会计资格考试,其表现与多数人类会计师相当,首次动摇了人类在专业判断与执行力上的独占地位。这一突破促使我们重新思考“人机协作”的未来边界,激发了关于AI能否真正承担记账、报税、审计等核心职责的深层次讨论。未来研究应重点聚焦模型性能提升(如接入权威数据库)、决策透明性(如ReAct机制减少幻觉)及AI审计的治理框架构建。在肯定其技术潜力的同时,我们也必须直面当前的局限,例如对复杂认知任务的应对能力、实际操作场景的适用性,以及考题与现实工作的鸿沟。ChatGPT或许尚未完全接管会计实务,但它正以前所未有的速度,驱动整个行业走向深度变革的临界点。
推文作者:
吕志冲,西南交通大学管理科学与工程博士生,研究方向为人工智能与公司金融。
刘丹,西南交通大学管理科学与工程博士生,研究方向为人工智能与公司金融。
推文内容若存在错误与疏漏,欢迎邮箱批评指正!
Abstract
ChatGPT frequently appears in the media, with many predicting significant disruptions, especially in the fields of accounting and auditing. Yet research has demonstrated relatively poor performance of ChatGPT on student assessment questions. We extend this research to examine whether more recent ChatGPT models and capabilities can pass major accounting certification exams including the Certified Public Accountant (CPA), Certified Management Accountant (CMA), Certified Internal Auditor (CIA), and Enrolled Agent (EA) certification exams. We find that the ChatGPT 3.5 model cannot pass any exam (average score across all assessments of 53.1%). However, with additional enhancements, ChatGPT can pass all sections of each tested exam: moving to the ChatGPT 4 model improved scores by an average of 16.5%, providing 10-shot training improved scores an additional 6.6%, and allowing the model to use reasoning and acting (e.g., allow ChatGPT to use a calculator and other resources) improved scores an additional 8.9%. After all these improvements, ChatGPT passed all exams with an average score of 85.1%. This high performance indicates that ChatGPT has sufficient capabilities to disrupt the accounting and auditing industries, which we discuss in detail. This research provides practical insights for accounting professionals, investors, and stakeholders on how to adapt and mitigate the potential harms of this technology in accounting and auditing firms.
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}