
图片来源:chatGPT4.0
文献来源:
Ash, E., & Hansen, S. (2023). Text algorithms in economics. Annual Review of Economics, 15, 659-688.
导读
01
现在大规模语料库很多,报纸、广告可以在数天内就累积到数千万份,这种语料库的普及,推动了文本分析算法的发展。但现在,文本分析算法在经济学的使用还是一片“蓝海”,学界对于文本分析算法的使用缺乏共识和方法论框架,甚至没有一个共同的词汇来概括现在文本分析算法的使用。而且,现在文本分析算法在构建变量上的使用看似新鲜,实际上缺乏共同基准,使用不同的文本分析算法,完全可以得出不一样的因果推断。
经济学家和计算机科学家关于方法的概念是不同的,经济学界更需要的,是明确哪些经济学相关的语言任务适用于哪些文本分析算法,而不是盲目的引入算法本身。为此,我写了这期推送,主要介绍以下方面:(1)简略介绍各种文本分析算法的概念;(2)文本分析算法目前在经济学中的应用方向;(3)当前学者使用这些方法的局限性。本文所有的代码,都提供在中,感兴趣的学者可以直接调用。
02
经济学中的文本分析方法
2.1数据预处理
文本分析处理的数据,要不是来源于网页(Python的Beautiful Soup),要不就是从历史书PDF扫描的图像文件(Python的Layout Parser)。因此,提取和分割数据,是文本分析算法的关键。
大部分情况下,文本分析都是基于句子维度进行分析,即使是最新的【基于自注意力机制的神经网络模型】,也对输入文本长度有限制。因此,在应用文本分析算法前,大部分学者都会先将文本基于空格/标点符号分割,去除非字母字符,去除常用停用词,去除后缀等等(例如,Manning等人,2008;Grimmer & Stewart,2013;Denny & Spirling,2018;Gentzkow等人,2019a)。还有一些学者通过语法去处理文本数据,比如把walked和walking合并为单一词干walk,或者在字典中搜索语言根源来进行词形还原(Jurafsky & Martin,2020;Ash等人,2023)。2022年后,gpt3 api已经可以直接将纯文本分割成tokens而不改变文本,不会改变文本信息本身。对于文本数据的预处理,是文本数据库的第一步。
2.2 词袋模型
“词袋模型”是一种常用的文档表示方法。想象一下(如下图),如果我们把一个文档里的所有词汇都放进一个虚拟的“袋子”里,每个不同的词都有一个唯一的编号,就像是每个词的“身份证号”一样。然后,我们数一数每个词在文档中出现了多少次,这个次数就是这个词的“权重”。

比如,一个文档是这样的:“苹果 美味 苹果 新鲜”,那么我们可以给“苹果”、“美味”、“新鲜”分别一个编号,比如1, 2, 3。然后数一数,“苹果”出现了2次,“美味”和“新鲜”各出现1次。这样,我们就可以用一个数字列表来表示这个文档,比如[2, 1, 1],表示编号1的词出现2次,编号2和3的词各出现1次。
把所有文档都这样处理之后,我们就得到了一个大表格,表格的每一行代表一个文档,每一列代表一个词,而每个格子里的数字就是那个词在那个文档中的出现次数。
这种方法的特点是简单直观,但它也有两个主要的问题。其一,这个表格的列可能非常多,因为即使是小型的文档集合,也可能包含成千上万个不同的词。其二,大部分时候这个表格里的数字都是0,因为大部分词在大部分文档中都不会出现。
2.3 聚类
有时候我们并不关注文档使用了哪些具体的词汇,而是更关心这些词汇所反映的深层含义。例如,“投资者害怕价格上涨”和“市场参与者对通货膨胀感到焦虑”这两个句子没有共同的词汇,如果我们用词袋模型来表示,它们的词频向量会是完全不相关的。但实际上,这两句话表达的意思是一样的。
在处理这种情况时,我们可以用类似于经济学中的因子分析的方法,在自然语言处理(NLP)中对文档进行降维处理,把它们映射到一个更能反映意义的空间里。这个意义空间比原始的高维词汇空间能更好地体现文档间的相关性和差异性。
其中一种常见的降维技术是主成分分析(PCA)。将PCA应用于文档-词汇矩阵,就形成了一种叫做潜在语义分析(LSA)的方法,这是文本分析中最早使用的降维技术之一。在这种方法中,从文档中提取出的“主成分”或“主要内容”实际上是基于词汇共现模式发现的潜在主题,就像在高维经济数据集中用PCA提取出的主成分代表了更深层的结构一样。
LSA虽然容易实现,但它在统计学上的基础并不清晰,有时候很难解释结果。因此,概率潜在语义分析(pLSA;Hofmann 1999)被提出,其假设文档是由一些共同的因素或者“主题”构成的,每个主题都有一个单独的词汇分布。每个文档都由一个关于这些主题的分布来描述。pLSA把文档的维度从V(词汇量)降低到K(主题数),采用非负矩阵分解(NMF)的最大似然函数,把词频矩阵转换成词频率矩阵(即每个词的频率而非次数)。
但是,在高维参数空间中,尤其是数据稀疏的情况下,最大似然估计容易过拟合。为了解决这个问题,LDA应运而生。LDA在pLSA的基础上,使用狄利克雷分布作为先验分布,计算效率更高,更容易产生人类可解读的主题。
图1展示了基于联邦公开市场委员会(Hansen等人2018)会议记录的语料库估计的潜在狄利克雷分配(LDA)的输出结果。图1-a和图1-b的上图词云代表了两个主题-词汇分布,词汇越大,表示该主题中词汇的频率越大。图1-a和图1-b的底部时间序列图,表示每位FOMC成员i在每次会议t提到该主题的频率,图中展示了这些分布的最大值、中位数和最小值,效果类似于箱型图。
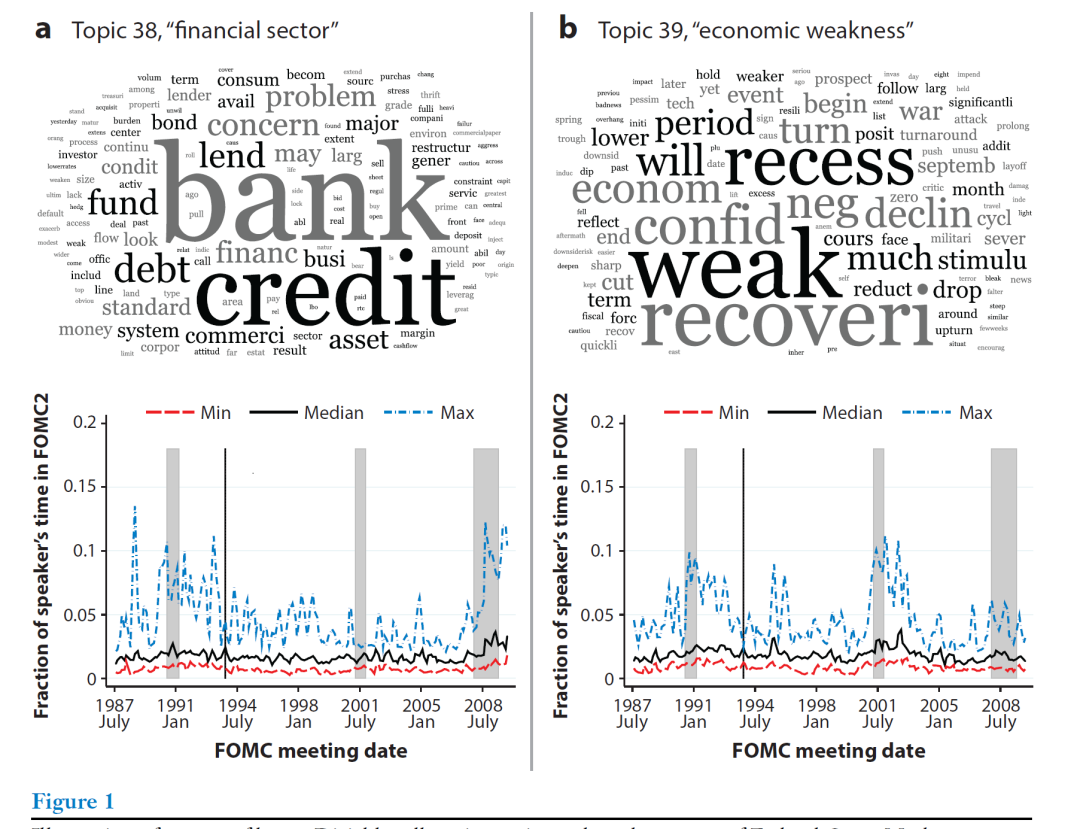
在处理大规模文本数据集时,降维聚类有助于减少数据的复杂性和维度,揭示文本数据中隐藏的主题和结构,为经济学家提供了强大的工具,是未来文本分析的重要方向。我在《怎么挖掘新闻文本预测经济?》详细介绍这种算法,可以直接跳转阅读。
2.4 Word Embedding
传统的词袋模型用一个向量xd来表示文档,这个向量不考虑词汇出现的具体位置,是基于全局词频的。但实际上,词汇的语义意义很大程度上是由它们在文本中的局部上下文决定的。虽然理论上我们可以通过统计n-gram(n个连续词组成的序列)来扩展词袋模型以捕捉局部上下文,但实际操作中,随着n的增加,特征空间V的大小会迅速增大,变得难以处理。更微妙的是,一个特定词的含义可能不仅取决于它的直接邻居词(离它最近的那个词),还取决于文本中更长范围内的局部依赖关系。
所以,现在NLP已经从文档-词汇计数的统计分析转向每个词汇与其他词汇的局部共现统计分析,这种方法叫Word Embedding。它利用这些局部上下文中的信息将词汇表示为相对低维且密集的向量,以低维的形式更精确地表示词汇的意义,压缩了整个语料库中高维稀疏的共现信息。
GloVe(全局向量)是一个比较常见的Word Embedding模型(Pennington等人,2014),用于构建能够编码词汇局部共现信息的词向量。简单来说,GloVe模型通过观察词汇在文本中是如何一起出现的,来学习每个词汇的意义。
在GloVe模型中,每个词的“上下文”被定义为它周围的一段长度为2L的词序列。比如,如果L是2,那么对于某个特定的词,它的上下文就包括它前后各两个词。GloVe模型中有一个关键的概念叫做词共现矩阵W,这个矩阵记录了每一对词在一定距离(L个词内)中共同出现的次数。通过调整窗口大小L,我们可以控制模型学习的词汇信息的类型,比如较短的窗口可能会学习到更多关于词汇的功能性或句法信息,而较长的窗口则可能学习到与主题相关的信息。一般情况下,L等于10。
在GloVe模型中,每个词都被表示为一个K维的向量。这些向量是通过一个优化过程来确定的,这个过程的目标是最小化词向量的点积和实际共现次数的对数之间的差的平方。直观上讲,如果两个词经常一起出现,它们的词向量的点积就会很大。GloVe的这个特性使得经常一起出现的词汇在向量空间中彼此靠近。
GloVe模型中还使用了一个称为加权函数f的东西,这个函数是非负的、递增的并且是凹的。这个函数的作用是调整不同共现频率的词对在模型中的重要性。
总的来说,GloVe模型通过分析词汇的局部共现信息,来学习词汇的含义,并将这些含义表示为密集的向量形式。这些向量可以用于各种自然语言处理任务,如解决类比问题等。
Word2Vec是另一种非常有影响力的Word Embedding模型,由Mikolov等人在2013年提出。Word2Vec的核心思想是把每个词及其上下文作为一个单独的预测问题,并通过学习解决这个问题。
在Word2Vec中,每个词汇不仅有一个词向量(表示该词本身),还有一个上下文向量(表示该词的上下文),这两种向量都是K维的。Word2Vec通过计算上下文向量和词向量的点积,来估计一个词在给定上下文中出现的概率。模型的目标是调整词向量和上下文向量,使得在整个语料库中,这种概率预测尽可能准确。
Word2Vec有两种变体:连续词袋模型(CBOW)和跳字模型(Skip-Gram)。在连续词袋模型(CBOW)中,模型通过上下文来预测当前词;在跳字模型(Skip-Gram)中,模型则是通过当前词来预测上下文。这两种模型都可以看作是一种一层神经网络,使用softmax激活函数。由于直接最大化这个模型是非常耗费计算资源的,Word2Vec采用了一些计算上的简化方法来近似似然最大化。
Word2Vec实际上是将一个无监督学习问题(在大型语料库中找到潜在的意义维度)转换为一个有监督学习问题。这种使用语言本身产生的预测目标,不依赖外部标签的方法,被称为自监督学习。
需要指出的是,在理想情况下,研究者会有足够大的语料库来估计特定于应用的定制嵌入,以捕捉特定领域的词义。但很多时候不会有这么大一个文本数据集,可能没有足够的信息来学习可靠的向量。在这种情况下,可以使用在大型辅助语料库上预先训练好的嵌入,并将它们迁移到新的应用中,这种策略被称为迁移学习。比如,先在通用英文文本(如维基百科)先把算法训练好,再用于自己的研究。但目前这种做法在经济学领域还相对少见,中文领域的,适用于经济学的语料库现在训练得太少了,训练更具经济学特性的语料库进行迁移学习可能会是未来重要的方向。
2.5 注意力机制(Embedding Sequences with Attention)
在日常生活中,当我们阅读或听别人讲话时,并不是对每个词都给予相同的关注。有些词更重要,会对我们理解句子的含义产生更大的影响。例如,如果有人说“我喜欢在冬天喝热巧克力”,“冬天”和“热巧克力”这些词对理解句子的含义很关键,而像“我”、“喜欢”这样的词就相对不那么重要。
在自然语言处理中,早期的模型,如Word2Vec和GloVe,当处理文本时,会给文本中的每个词赋予相同的重要性。但实际上,我们人类处理语言时,有些词在理解句子意义时更加重要,有些词则不重要。这就是注意力机制的核心思想:模型需要学会在处理文本时“关注”哪些词更重要。
用以下两句话举个例子:
作为领先公司,在[XXXX]行业,我们雇佣了高技能的软件工程师。
作为领先公司,在[XXXX]行业,我们雇佣了高技能的石油工程师。
在第一句话中,“软件工程师”暗示了[XXXX]可能是“信息技术”;而在第二句话中,“石油工程师”则暗示了[XXXX]可能是“能源”。注意力机制使模型能够理解哪些词(如“软件”和“石油”)对预测缺失的词([XXXX])更重要。
Transformer模型,例如BERT和GPT这些模型,采用了注意力机制来更好地处理语言。它们不仅仅考虑每个词本身,还考虑词与词之间的关系,以及它们在特定上下文中的重要性。这种方法使得这些模型在处理诸如文本摘要、问题回答等复杂的自然语言处理任务时表现更出色。
注意力机制使NLP模型能够像人类一样,更聪明地处理语言,通过识别并重点关注重要的词汇和上下文,以更准确地理解和生成文本。这使得Transformer模型提升了机器处理和理解自然语言的能力。
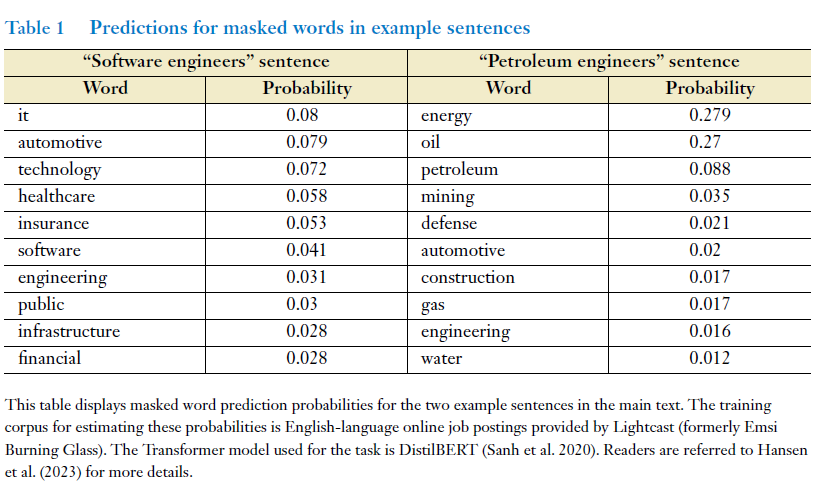
表1展示了一个特定的Transformer模型(Sanh等人,2020年)对两个示例句子中遮盖词的预测概率。尽管两个句子只在一个词上有所不同,这个词距离遮盖词还有几个其他词的距离,但模型产生的预测结果却大不相同,这显示出即使在上下文中的小变化也可能导致意义上的大不同。
在“软件工程师”的句子中,模型预测遮盖词“it”,“automotive”(汽车制造),和“technology”(技术)的概率分别为0.08、0.079和0.072。而在“石油工程师”的句子中,最可能的词是“energy”(能源)、"oil"(石油)和“petroleum”(石油),概率分别为0.279、0.27和0.088。这表明,模型学会了将特定的职业(如软件工程师)与特定的行业(如技术、汽车、卫生)联系起来。
但是,Transformer模型也存在缺点。这些大型模型的训练需要大量的硬件资源,通常只有大型组织才能负担得起,大多数研究人员都是下载已经训练好的模型,比如GPT模型就是比较著名的Transformer模型。
2.6 基于文本的有监督模型
所谓的“监督学习”是指我们有一堆文本,并且我们知道每个文本相关的某些信息,比如经济状况或政治倾向yd。我们的目标是建立一个模型,这个模型可以学会文本内容里的信息wd来预测yd。LASSO回归就是比较有名的监督算法,但对于文本分析任务来说,这种方法没有考虑到文本数据中词与词之间的强依赖性,太简单了。
这个时候就要用更复杂的模型,去处理词之间复杂的非线性关系和相互作用,比如随机森林和梯度提升算法。但是经济学的文本数据量一般都不大,而且文本分析算法对数据的质量要求很高,所以在选择模型时,又需要根据数据量对使用的模型进行取舍,一般的做法是:先使用预训练模型(比如基于Transformer的模型),对其进行微调,以适应特定的监督学习任务。
ChatGPT没有出来之前,Transformer用于处理短文本,梯度下降算法用于处理长文本。现在,经过增强的GPT-4,已经可以很好地处理长文本了。
文本分析方法目前在经济学中的应用
03
经济学家对算法的结构本身并不感兴趣,用算法的目的,在于解决特定的问题,所以我接下来举了四个例子,看现在的经济学怎么运用文本分析算法的。
3.1方向一:测量文本间的相似性
无论使用哪种方法,计算文档相似性的第一步都是将文档转换为向量形式(最常见的做法,就是2.2提到的词袋模型),用余弦相似性来比较两个向量的标准距离度量。余弦相似性不仅可以用于两两文档之间的比较,还可以用于将相关文档聚集成簇。大家比较熟悉的k-means算法,就是使用余弦相似性的聚类方法。k-means聚类的优点,在于其适用于几乎所有文本文件。
文本相似性测量比较出名的工作,是Hoberg和Phillips(2016)在Journal of Political Economics上的文章,他们通过SEC公布的企业主营业务进行文本相似性分析,将企业按照主营业务和产品描述的相似性,重新划分行业,定义了一个全新的行业划分方法。
除此之外,Hoberg和Phillips(2016)用它来构建行业类别。Cagé等人(2020)使用在线新闻文章和社交媒体帖子之间的距离,将内容分组到共同主题中。Kelly等人(2021b)使用美国专利申请文件之间的相似性来分析技术的新颖性和影响力。Biasi和Ma(2022)测量学院课程大纲和学术期刊文章之间的相似性,作为大学课程内容和最新研究之间的差距的代理变量。
相似性度量的关键在于怎么将文本数据转换成数字,除了k-means算法,还有词频-逆文档频率(TF-IDF)加权,潜在语义分析(LSA),线性判别分析(LDA),词嵌入(word embeddings)等。比如,Iaria等人(2018年)使用LSA来量化科学研究议程之间的重叠程度。Hansen等人(2018年)应用LDA,衡量政策制定者在透明度增加后的群体行为。Hansen等人(2021年)就使用词嵌入(word embeddings),比较执行管理人员的工作描述与ONET(一个关于美国职业信息的数据库)任务描述之间的相似性,来检测工作描述中技能的存在。Kogan等人(2019年)通过比较ONET任务描述和专利文本的相似性,来衡量职业暴露于技术的程度。
3.2方向二:概念挖掘
概念挖掘是文本分析在经济学应用的几乎最重要的方向,没有之一。目前,比较出名的概念包括:经济政策不确定性(EPU;Baker等人,2016年)、劳动力市场中的技能需求(Deming & Kahn,2018年)、经济情绪(Shapiro等人,2022年)和技术采用(Bloom等人,2021年)。
具体来说,主要有以下几个方向:
(1)在大量的文本数据中查找特定的单词、短语或者结构。比如,Hassan等人(2019)的道德价值术语字典。Loughran和Mcdonald(2011)的金融情绪词典。Ash等人(2020c)从劳工合同中提取表示义务或权限的动词。Fetzer(2020)句法分析方法来检测和衡量印度新闻文章语料库中的冲突事件。
(2)主题建模。比如,Boukus和Rosenberg(2006年)使用LSA,Hansen和McMahon(2016年)使用LDA来分析中央银行文件,研究特定主题与市场动向的相关性。用LDA分析报纸来预测经济,解释经济现象的论文现在也很多(Mueller和Rauh,2018年;Larsen和Thorsrud,2019年;Thorsrud,2020年;Bybee等人,2021年)。需要注意的是,主题建模是一种无监督算法,如果讨论的问题本身需要先验知识,这个算法是不一定适用的。
(3)结合人工智能和人类判断识别和度量概念。对于一些需要先验知识的文本分析,作者先选定一组初始的种子词,然后使用词嵌入技术扩充词集,接着计算词向量之间的余弦相似性,人工选择哪些词包含在扩展的术语集中。这个方法,最近用的很多(Hanley和Hoberg,2019年;Atalay等人,2020年;Davis等人,2020年;Li等人,2021年;Soto,2021年)。比如Gennaro和Ash(2022年)的情感性和理性术语集。Truffa和Wong(2022年)使用该算法生成与“妇女”和“女性”相关的额外术语,来检测与性别有关的学术文章。Hansen等人(2023年)比较了几种监督学习模型,用于预测“远程工作”这一文本的效果。现在,TopicGPT已经替代人工选择这一步,让整个算法变成全自动的()。
(4)连续语义相似度度量。Ash等人(2020a)计算了个别法官的文本与经济学相关短语词典的嵌入表示之间的相似度,并发现参加过经济学培训的法官在使用经济学语言上得分更高。Gennaro和Ash(2022年)为情感和理性词典生成嵌入维度,根据政治演讲与这些词典向量的相对距离沿情感指数进行缩放,研究了美国国会议员在演讲中使用情绪化修辞的情况。
3.3 方向三:理解和量化概念之间的关系
这个方向考虑的是概念间的关系,例如:对经济条件的积极或消极情感(Apel & Blix Grimaldi,2014),政治风险暴露(Hassan等人,2019年),以及性别与职业和家庭的关系(Ash等人,2020b)。
有几个比较典型的例子:Ash等人(2020b)通过考察法官所撰写的意见书中“男性-女性”和“职业-家庭”维度之间的相关性,测量美国上诉法院法官的性别态度。Ash等人(2023年)分析美国议员在国会演讲中,“行动者”和“行动目标”之间的关系,揭示美国议员的世界观叙事和政治观点宣传套路。
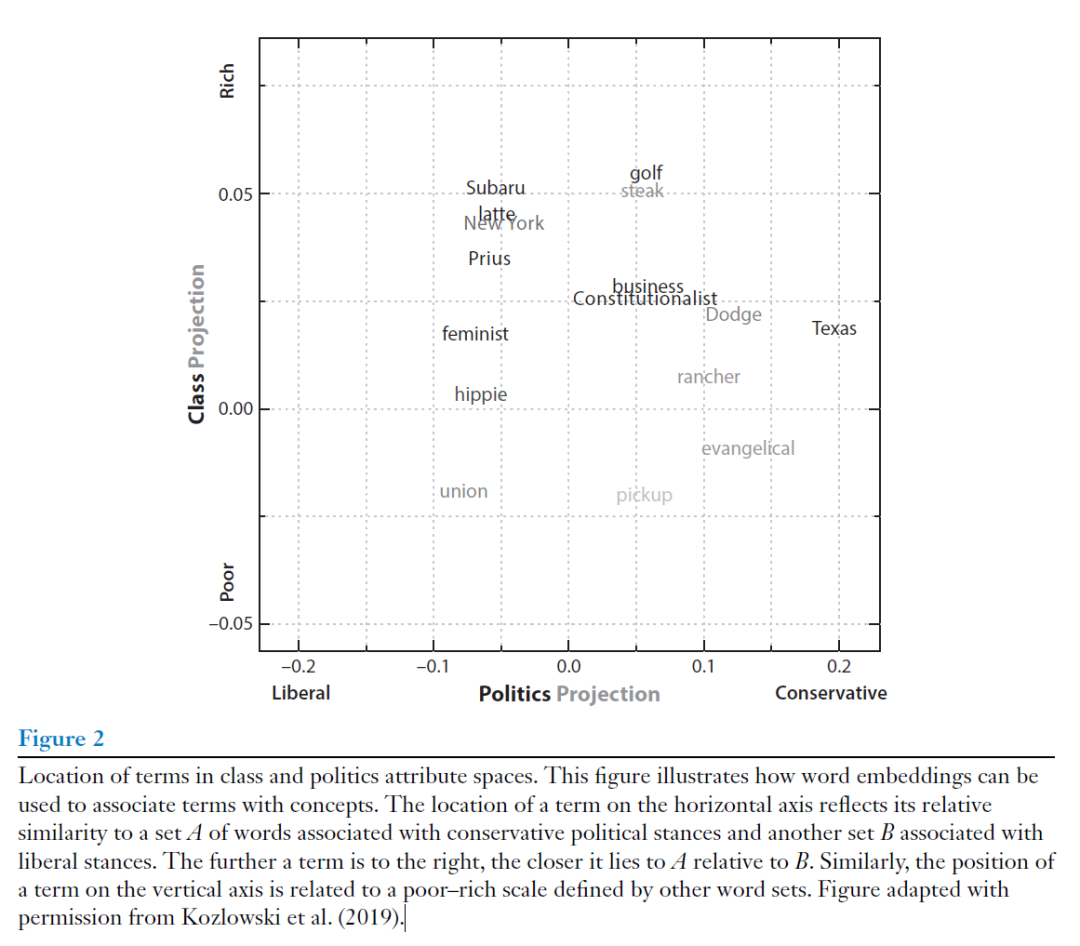
图2可以帮助我们更好地理解这个方向的研究。图2中,水平轴表示政治倾向,单词越偏向图表的右侧,表示它与保守派立场的关联越密切。反之,越偏左则与自由派立场的关联越密切。;垂直轴表示社会经济阶层,单词越往上,表示它与“富”相关联的程度越高;越往下,表示它与“穷”相关联的程度越高。比如:“golf”(高尔夫)和“steak”(牛排)位于右上方,暗示它们与保守的政治倾向和较富裕的阶层有关。而“union”(工会)和“hippie”(嬉皮士)这样的术语位于左下方,暗示它们与自由派政治倾向和较贫穷的阶层有关。
3.4 方向四:文本数据与传统数据的结合
比如:Bana(2022)从招聘帖的文本去预测工资,改变不同的语言输入,来进行工资预测。Ke等人(2019)和Davis等人(2020)分别使用新闻文章和监管文件的文本,来预测股票回报。
04
存在的问题和挑战
遍历上面四个方向,你可以发现,其实文本分析算法现在最主要的应用就是概念挖掘,或者说,就是用来作为计量回归的上游,进行变量构建。这就涉及到一个问题:不同文本分析方法做出来的结果是一致的?
为了回答这个问题,作者使用美国2019年的4033家公司的年度报告,将上文提到的所有文本分析方法都复现一遍,计算不同方法之间结果的差别。
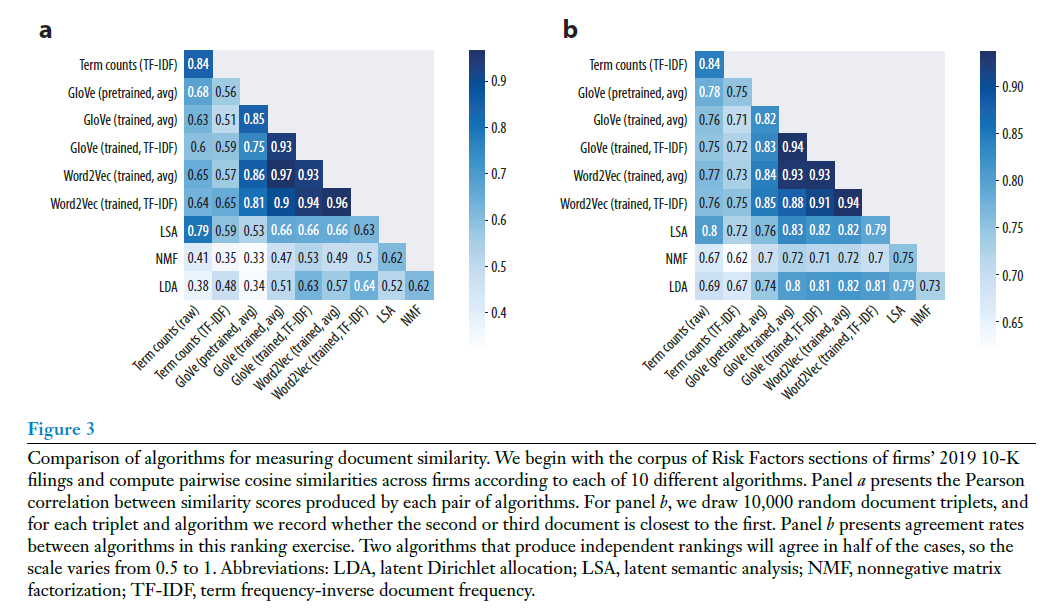
图3展示了公司年报之间的文本余弦相似度,可以看到,不同方法之间的相似性度量存在高度一致性。图3a中的平均皮尔逊相关性是0.64,而图3b的平均一致性率是0.78。随机抽取了50,000对公司,并再次使用每种方法计算余弦相似度,结论是一致的。
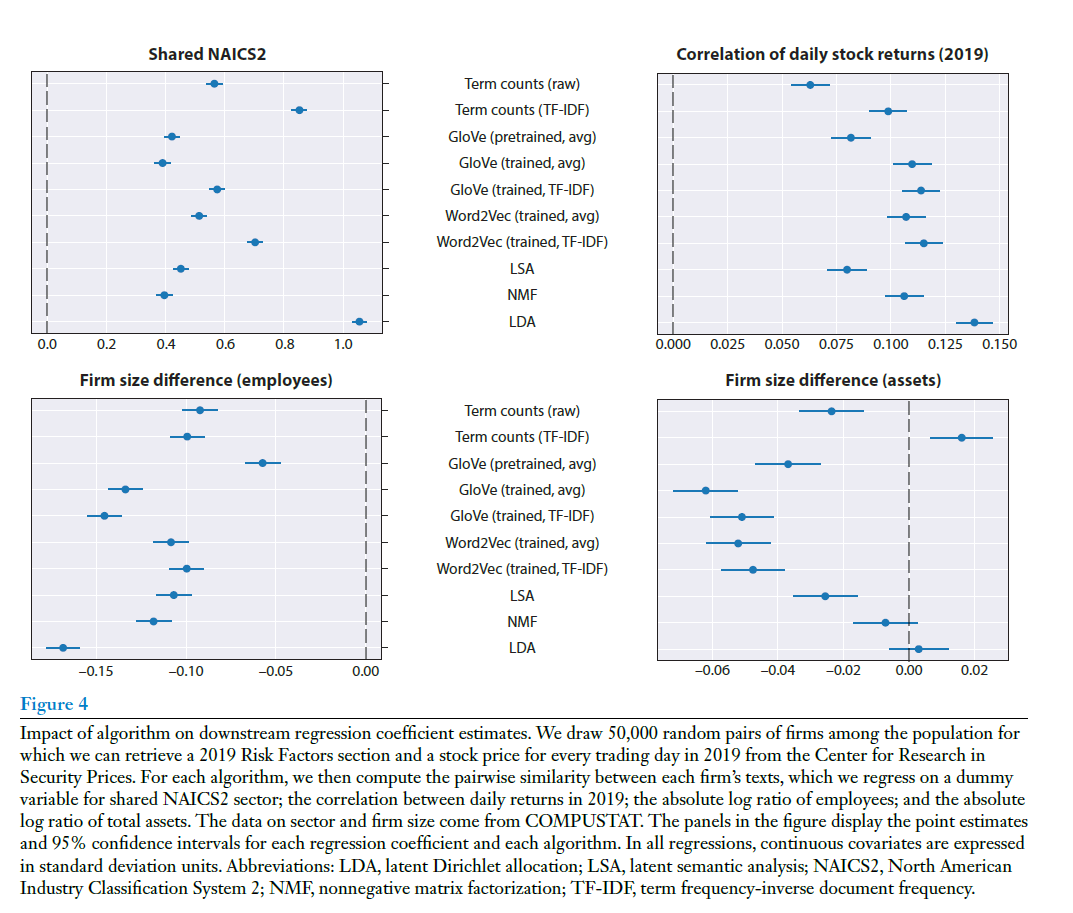
但是,图4展示了不同算法对下游回归系数估计的影响。图中的四个面板分别显示了以下内容:共享NAICS2展示了文本相似度与公司是否属于相同NAICS2部门之间关系的回归系数估计及其置信区间。公司规模差异(员工数)展示了文本相似度与公司员工数大小差异之间关系的回归系数估计及其置信区间。日股票回报的相关性展示了文本相似度与公司2019年日股票回报相关性之间关系的回归系数估计及其置信区间。公司规模差异(总资产)展示了文本相似度与公司总资产大小差异之间关系的回归系数估计及其置信区间。结果表明,不同的文本分析算法(包括词袋模型、各种词嵌入模型、LSA、NMF和LDA)在关联文本相似度与经济指标之间关系的研究中会产生不同的结果。不同方法对于哪个协变量与文本相似性也各不相同。这告诉我们:文本分析算法的选择对于下游的因果推断并非无关紧要,相反,文本分析方法的不同,会导致后续计量回归的结果完全不同。
另外,可解释性是阻碍文本分析算法应用的关键问题。经济学家为什么那么关心算法的可解释性,这是因为:
(1)过拟合。这是所有深度学习方法在经济学上应用的通病。文本特征空间是高维度数据,很容易产生伪相关。
(2)无法解释未来。深度学习算法最重要的应用领域就是预测,但是经济数据更容易受到噪音和结构性中断的影响。如果未来发生的事情改变了数据的分布特征,这个方法立刻就没用了,比如通过2020年的报纸文章预测经济衰退的算法,可能会因为2022年经济下滑的新特征而失效。
(3)黑箱机制。OpenAI已经快变成CloseAI了,截止本文成稿,OpenAI并未公布GPT-4的内部运行原理,这给GPT等Transformer技术在经济学上的应用带来了不确定性。如果GPT对文本数据的标注,每次结果都不一致,这个方法就完全无法运用于经济学研究。
结论与展望
05
文本分析算法的出现,展示了新的经济学研究可能性。使用文本分析算法,我们可以将文本转换成向量,降低文本向量的维度,利用文本信息进行回归、相似性分析、主题建模等等。比如,Bandiera等人(2020)使用LDA衡量CEO的领导风格(Draca和Schwarz,2018)。Ruiz等人(2020)使用与词嵌入相关的模型来捕捉商品的潜在特征。Ash等人(2021)和Adukia等人(2023)使用报纸上个人的图像来描绘视觉偏见。文本分析算法扩展了经济学家在非结构化数据上的应用。
未来,文本分析算法在经济学的应用,大概率有以下方向:(1)建立一个基准,衡量不同模型在不同经济学任务的应用边界,使得后续研究者可以用相同的算法,复现一样的结果。(2)探索文本分析在因果推断领域的应用。(3)现有的文本分析几乎只用于构建变量,但其实文本分析可以在文本结构(比如,文本的语法复杂度、词语之间的关系)等方向发挥更大作用。(4)大语言模型的应用,比如数据标注。
Abstract
This article provides an overview of the methods used for algorithmic text analysis in economics, with a focus on three key contributions. First, we introduce methods for representing documents as high-dimensional count vectors over vocabulary terms, for representing words as vectors, and for representing word sequences as embedding vectors. Second, we define four core empirical tasks that encompass most text-as-data research in economics and enumerate the various approaches that have been taken so far to accomplish these tasks. Finally, we flag limitations in the current literature, with a focus on the challenge of validating algorithmic output.
推文作者:林泽腾,香港科技大学数据科学学域研究生,南方科技大学访问研究生。研究兴趣:大语言模型推理算法和计算社会科学。本文的重点在于介绍现在已有的文本分析算法应用,略过了许多数学推理和方法逻辑,如有错误,请通过邮箱联系。
个人邮箱:
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}