
图片来源:ChatGPT-Plus-DALL.E
生成图片的Prompt指令:A wide banner image for a WeChat article cover, focusing on the theme “Extracting Text Information from Business News for Economic Prediction.”
本期解读论文:Bybee, Leland and Kelly, Bryan T. and Manela, Asaf and Xiu, Dacheng. (2023)."Business News and Business Cycles" Journal of Finance. forthcoming
Link: http://dx.doi.org/10.2139/ssrn.3446225.
导读
我遍历了香樟2023年以来,所有提到“文本分析”的推文。 我发现,在本推文之前,像《军事投资与产业集群的崛起:来自洋务运动的证据》介绍了作者使用文本分析,挖掘曾国藩的信件中,哪些政治家与他交换了信息。《金融发展的法律起源——来自上海租界的证据》中,文本分析用于挖掘英租界的常用关键词。《央地交流与政策执行力:来自政策文件大数据的证据》中,文本分析用于提取政策文件中的文件号,以匹配央地文件。《海盗无国界:网络攻击在供应链上的传播》使用文本分析,主要是为了提取“Petya”、“NotPetya”和“cyber”等关键词以比对受到网络攻击的公司。
这些文章里,文本分析的作用约等于“关键词提取”,使用文本分析的前提是预设关键词。但如何科学的把其他相似的关键词也加入到分析中,防止损失文本信息,是目前的推文没有涉及的。如何在不预设任何关键词的前提下更好的挖掘新闻文本,发挥这种高质量数据的研究价值呢?这是我分享这篇论文的动机。
01
引言
经济是一个复杂的系统,确定当前经济的状况(现在是通货膨胀还是通货紧缩?)、预测经济的演变(股市未来能突破3000点吗?)都是非常艰难的任务。一般来说,我们认为,商业新闻/经济新闻的新闻文本是媒体部门是对经济事件的感知,是新闻消费者的需求偏好和新闻生产者的生产惯性之间平衡的结果(Mullainathan和Shleifer, 2005)。商业新闻文本是当前经济问题的一面镜子。金融波动可能是新闻驱动的,因为某个主题的新闻也喜欢聚集性出现(Engle等人,1990),记者学习一个新主题是需要固定成本的,更希望未来的一段时间,可以更有性价比的发挥这个新主题的金钱价值(Boydstun,2013)。这都会导致新闻驱动金融市场波动。
怎么更好的挖掘这里面的信息,对商业新闻消费者、商业新闻生产者都非常重要。可是怎么挖掘商业新闻文本里的信息?这篇论文,提出了这样一种方法,从数据驱动出发,挖掘文本本身信息,在不预测任何关键词的情况下,找出新闻文本中的主题分布。具体来说,作者把1984年到2017年的《华尔街日报》经济新闻全文中的文本提取出可以解释的180个主题,并计算随时间分布的每个主题的新闻关注度(占总新闻的百分比),分析这些主题关注度对于宏观经济的影响。
作者发现:商业新闻可以分解成不同主题,这种分解可以直接由Lasso模型驱动。比如,对于《华尔街日报》,180个主题是最合适的。新闻里的主题有长期主题、季度性主题和偶然主题。长期主题,比如,“石油钻探”主题和“石油市场”主题明显与原油价格波动有关。新闻也有一些季节性主题,比如“联邦储备”主题和“健康保险”主题。还有一些偶然主题,比如“恐怖主义”主题和“自然灾害”主题。
新闻关注度能够解释一部分经济活动。比如:新闻能解释25%的股市波动。58%的杠杆收购(LBO)交易与“收购”新闻主题和“控股权”新闻主题有关。当然,这些相关不一定是因果。新闻关注度能够更好的预测未来经济,作者提出了Group-Lasso VAR方法,来更好的选择最佳的预测经济的新闻主题。读者还可以直接找出当期最影响经济的某篇文章,仔细阅读,以确定《华尔街日报》在叙事检索带来的经济影响。
本质上,本文只是一个案例研究。但是本文的研究开创了一个新领域,即,怎么使用微观领域的主题建模以及文本分析技术,解释宏观经济动态。要知道,实证经济最早是于2017年开始使用主题建模技术(Hansen等人,2017年)。此前,除了Larsen和Thorsrud(2019)和Thorsrud(2020)使用LDA技术分析挪威新闻用于预测经济,其他研究者更多使用理论驱动的文本分析而非数据驱动,比如Chahrour等人(2021)研究报纸覆盖程度对于宏观经济活动的影响。Baker等人(2016)等人计算关键词次数来建立经济政策不确定性指数。
本文将微观文本分析和宏观经济分析进行结合,提供了一种新的预测工具。本文的魅力在于,规范了主题建模在金融学中的标准用法,给出了一整套解决方案,比如:(1)多少个主题的聚类是最合适的?(2)怎么度量特定主题文章的经济冲击;(3)使用VAR度量经济冲击时,选择多少个主题是合适的?(4)怎么找到影响经济冲击的特定文章。等等。
怎么使用LDA进行主题建模
02
2.1 LDA主题建模的原理
本文使用潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)进行文本分析,LDA 是一种用于处理和分析文本数据的统计模型,它能够从大量的文本数据中提取出主题,并将文本简化为一个易于理解和分析的格式。
本文中,作者对历史上所有《华尔街日报》的文本进行建模,得到一个W矩阵,这个W矩阵是T x V矩阵,T表示T篇不同文章,V表示V个独特词汇,Wt,v就是第v个词汇在文章t中出现的次数。Wt,v服从多项式分布,具体如下所示:
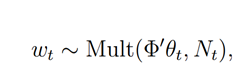
公式中,Nt 是文章 t 中的总词项数,控制多项式分布的规模。Φ是一个概率向量,Φ = [ϕ1, ..., ϕK]′,表示文章 t 中,各个主题的关注度,或者说,θt 捕获了文章对这些因子的暴露程度。
由于最大似然估计在大多数文本计算上不现实。作者使用贝叶斯方法,并采用Xiao和Stibor(2010)提出的折叠吉布斯抽样器进行估计。
LDA通过创建一个主题的概率分布模型,使得每个文章被视为这些主题的混合,从而提供了一种解读和理解文本数据的方式。这个方法通过使用高级统计技术(贝叶斯方法和吉布斯抽样)来处理和估计文本数据中的复杂结构,使得我们能够从大量的文本中提取有意义的信息,例如确定新闻文章中的主要主题和趋势。通过对文本进行主题建模,LDA 能够揭示文档集合中的隐含主题结构,从而为分析文本提供了一个强大的工具。这对于经济新闻分析尤其有用,因为它能够揭示出隐藏在大量新闻报道中的经济趋势和模式。
2.2 LDA主题建模的数据来源
本文成文于2019年9月,使用的数据集是1984年1月至2017年6月间《华尔街日报》(WSJ) 发布的所有文章,这是当时可以从道琼斯历史新闻档案中购买的全文最长记录。在此之前,还没有论文对《华尔街日报》的完整文本进行分析,比如,Manela和Moreira(2017)对《华尔街日报》的摘要进行了分析。Baker等人(2016)用预定义关键词分析了《华尔街日报》的出现次数。
为了更好的进行分析,本文对数据进行了以下处理:(1)去除了1984年以前的数据,因为之前的数据只有摘要,没有全文。(2)只分析34年来没有断更过的三个核心板块(“第一版块”、“市场”和“金融与投资”)的文章全文。(3)提出新闻标签里(如体育、休闲和艺术)和经济新闻没关系的文章。最终,获得763,887篇文章和18,432个词汇。
2.3 LDA聚类成多少个主题合适?
LDA本身是一个无监督的机器学习技术,研究者要告诉模型,文本要聚合到多少个主题,那么对于研究者,文本应该选择聚合到多少个主题合适呢?图1的左图绘制了34年来,本文数据集里,每个月累积的文章数(Articles)和词汇数(Terms)。图1的右图绘制了不同主题数量(K值)的模型评估的拟合程度。图里,使用了两个指标来衡量模型是否过拟合:交叉验证的平均对数似然数和贝叶斯因子。可以看到,在聚类的时候,主题不宜过多,也不宜过少。本文中,K =180是一个比较合理的选择。
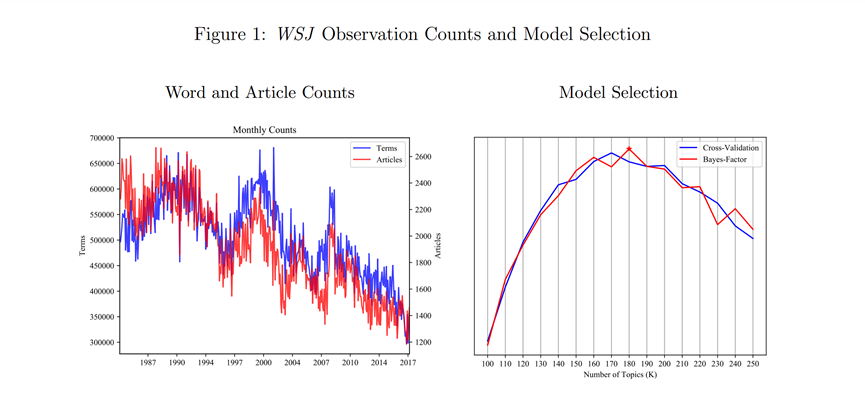
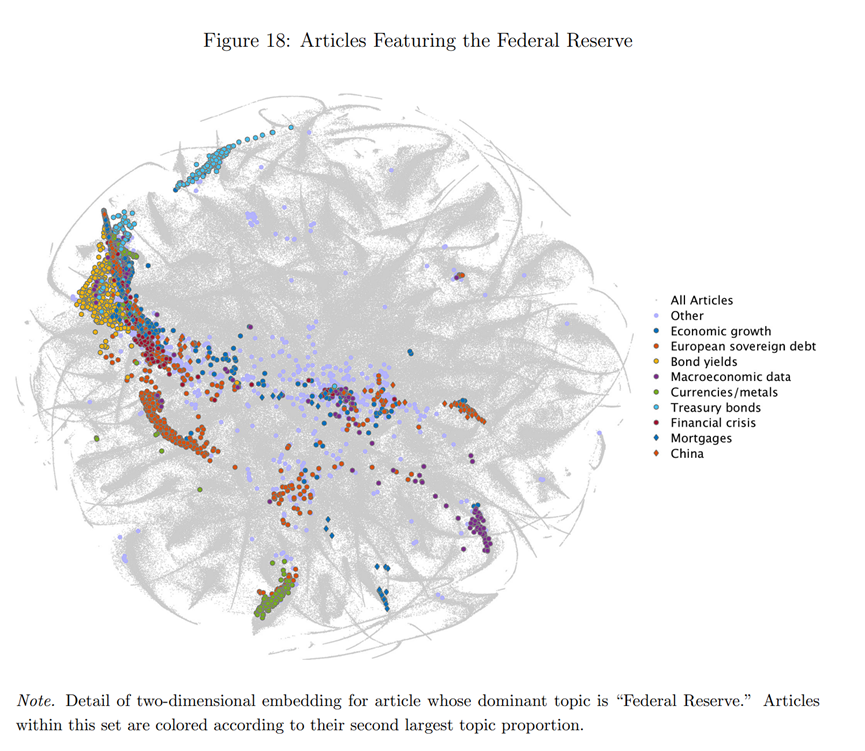
图18 展示了一个案例,解释K=180的LDA主题建模如何解释《华尔街日报》的新闻文本。图18中,灰色的点表示所有第一主题是“联邦储备”的文章。其他颜色的点,表示该文章的第二大主题,可以看到,关于联邦储备的文章也倾向于与“经济增长”、“欧洲主权债务”、“债券收益率”、“宏观经济数据”、“国债”、“金融危机”、“抵押贷款”和“中国”主题相关。
2.4 LDA主题建模时,怎么避免超前偏差?
在主题建模的时候,会出现一个问题:超前偏差。LDA建模的超前偏差比较难理解,这里以主成分分析为例,主成分分析是以全样本的聚类为基准的,那如果我们用主成分分析出来的因子去预测样本中的股价,因子本身就受到了未来信息的影响,那么,这种预测是不可靠的。因此,本文使用了Hoffman等人(2010)提出的online LDA模型(简称:oLDA)来进行主题建模,与滚动窗口建模不同的是,oLDA是对基于从时间段 1 到 t 的数据进行建模,不仅保证主题建模不受t+1时刻信息的影响,又考虑了全样本的信息。
感兴趣的读者可以直接调用gensim Python包来进行主题建模。
03
《华尔街日报》的新闻文本结构
3.1 《华尔街日报》包括哪些主题和关键词
在进行主题建模的时候,怎么把经常重复出现的无效词(如“价格”和“公司”)筛选出来?本文采用的方法是调整权重,具体来说,对于每个给定主题k的词汇概率向量ϕk,作者对其除以出现频率fv,以降低过于频繁的异常词(如“制药”或“铁矿石”)的概率。
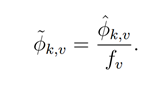
表7展示了K-180的LDA估计后的主题,由于这些主题没有标签,作者又手动地给每个主题分配了一个标签。这和我们常见的“百度指数”不同,“百度指数”等产品只是统计了某个关键词在新闻搜索中的次数,作者则从全样本的角度总结主题词的变化,不仅进行了高频词的聚类,又统计了这些高频词的时间序列变化。既防止了某些关键词没有被统计到主题中,又利用了该主题在文中的所有信息。比如,表7的第1行:奖金、基本工资、总薪酬、薪酬套餐、薪酬包、薪酬委员会、限制性股票、泰科、高管薪酬,这一系列词汇,对应的是“高管薪酬”这个标签。文中还展示K=50的LDA建模结果,结果显示,当主题太少了,LDA会混合很多不同的主题在同一个主题中,具体见原文,这里不予赘述。
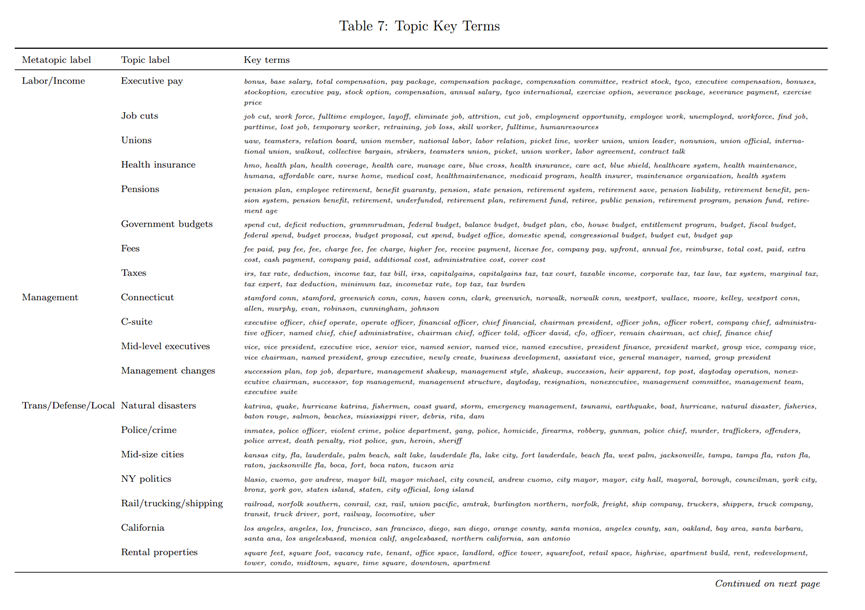
除此之外,这样纯数据驱动的主题建模,本身不受到建模者的主观影响。主题词里,既包括了一些无倾向的主题,比如“航空公司”、“联邦储备”和“中国”。也包括了负面主题,如“恐怖主义”、“自然灾害”和“衰退”。这些都是新闻本身对事件的符号性或者方向性评价。
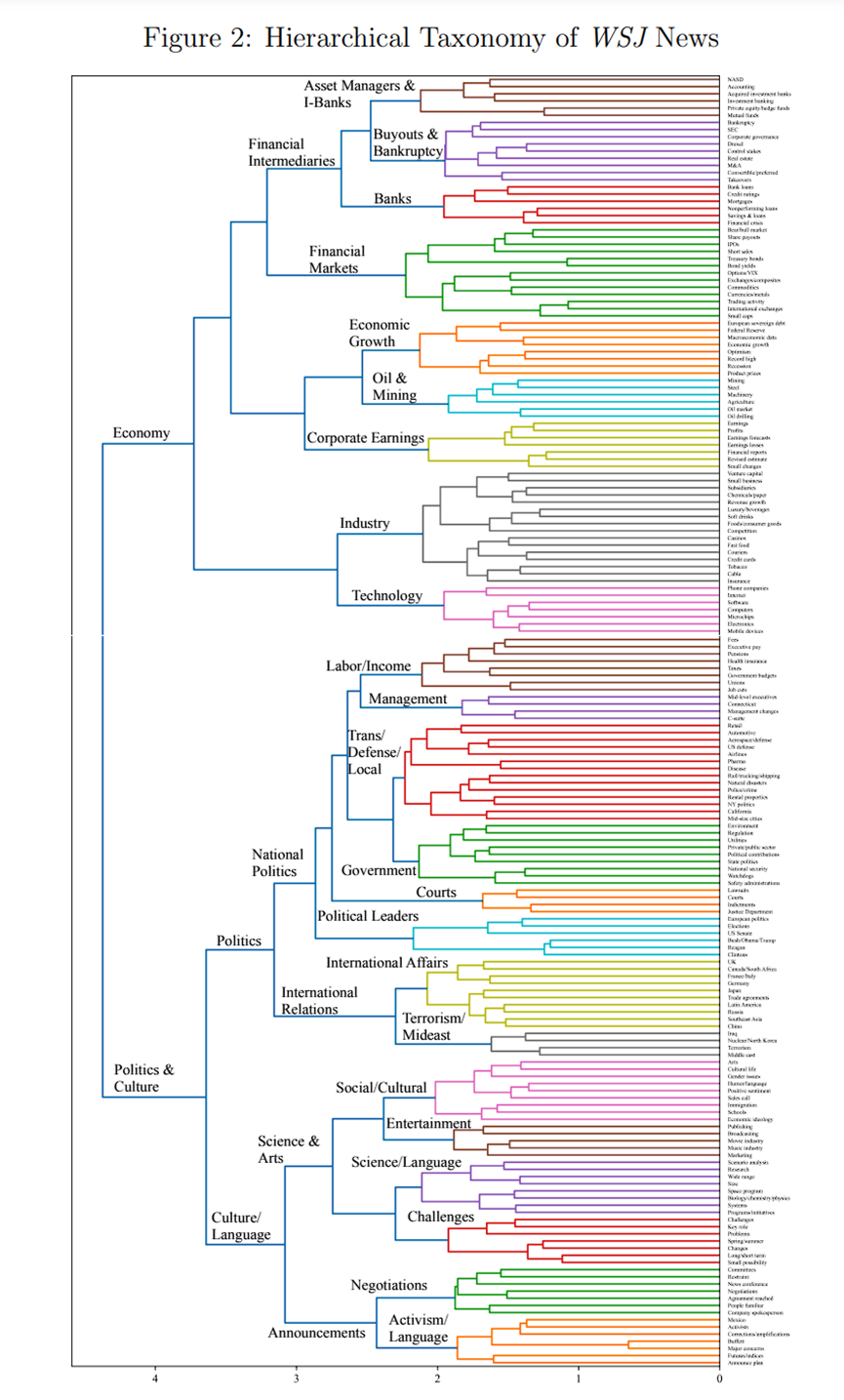
作者还使用我们熟悉的层次结构树状图来检查LDA主题建模结果(Quinn等人,2010)。从图2我们可以看到,180个主题被分为两大类:经济,政治和文化。而在“经济”中,主题分为“金融中介”、“经济增长”和“行业”等。“政治和文化”被分为“国际关系”、“国家政治”和“科学与艺术”等。
3.2 怎么量化《华尔街日报》新闻文本中的主题关注度
只是简单的建模主题和提取关键词并不足以进行经济分析。还需要将这些主题聚合成月度数据,并整理出《华尔街日报》在过去34年来,每个月的每个主题的新闻关注度水平。图3展示了六个代表性主题的时间序列变化情况,图中,黑线代表该主题的关注度,关注度=该主题本月数量/该月《华尔街日报》新闻总产量;蓝线代表主题下每个关键词在主题中的权重。下面我们逐图分析:
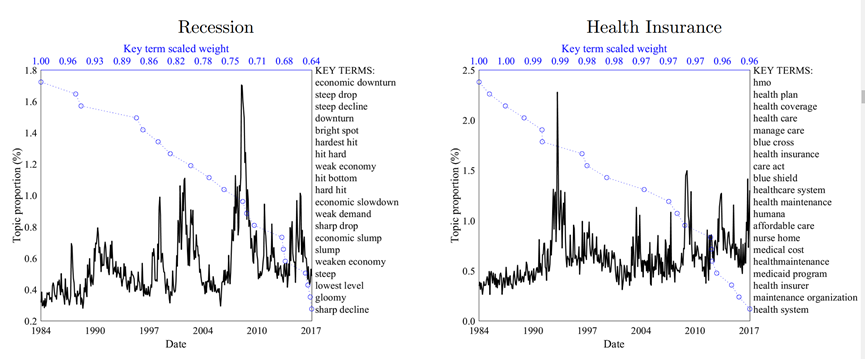
先看“衰退”和“健康保险”两个主题,我们可以发现,有些新闻是长期被关注的,“衰退”在这34年间,反复出现,在2008年金融危机达到巅峰。而“健康保险”则是在在1993年9月克林顿总统向国会发表演讲时(克林顿医疗计划提案)达到顶峰,在2008-2010年的奥巴马医改提案通过,以及2016年总统选举期间讨论废除奥巴马医改时出现两波小高潮。
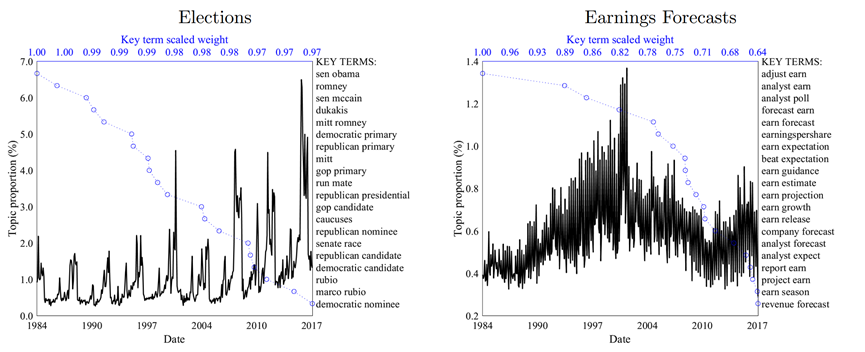
再看“选举”和“盈利预测”这两个主题,这两个新闻主题是季节性的。每四年,选举主题就会有一次规律性高峰。每季度,“盈利预测”也有规律性的高峰。
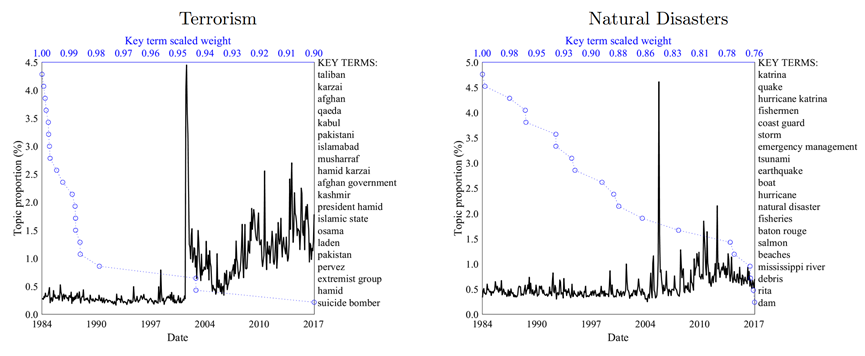
“恐怖主义”和“自然灾害”则是两个新兴主题,大部分时候,他们都很少被提及,但911事件时,“恐怖主义”主题急剧上升,从此保持高位。2005年8月,卡特里娜飓风席卷美国,关于“自然灾害”的新闻关注度急剧上升,之后虽然关于气候变化的新闻关注增加(Engle等,2019),但趋势基本回落。
新闻关注度和宏观经济活动
04
到此,上述方法已经足够社会科学其他领域的学者使用了。但对于金融学,简单的文本挖掘并不够,还需要将挖掘出来的文本信息匹配到宏观经济数据中。
Lasso回归(Least Absolute Shrinkage and Selection Operator)是一种用于回归分析的技术,由于本文的不同主题新闻关注度,变量之间高度相关,直接进行OLS回归会过度拟合。所以我们需要从潜在的变量序列中选出重要的主题,即,对被解释变量最有影响力的新闻主题。Lasso回归不仅估计系数,还通过将某些系数缩减为零来选择变量。这种选择性意味着模型的最终形式是基于数据自身进行选择的,而非预先确定。
Lasso模型可以在Python中的scikit-learn库直接调用。在解释模型结果的时候,我们要注意,模型结果的P值是模型选择后计算的,而且模型的回归系数被缩放,在解释模型结果时,回归系数表示的是当预测变量变化一个标准差时,因变量预期的变化量。
本文中,作者输入180个主题,并选择固定的最显著的5个主题。值得注意的是,一般来说,Lasso模型需要交叉验证,选择最佳的主题数,以确保预测误差最小。但作者在文中没有这么做,他们的解释是,确保结果的清晰解释性,确保回归的统一性和可比性。我的理解是,作者是为了推广这种方法,如果我们自己使用,特别被解释变量只有一个是,最好还是要交叉验证到最佳的主题数。
接下来是新闻关注度和经济变量的四个例子,在表格中,作者不仅给出了回归系数和P值,也给出新闻关注度和被解释变量的时间序列图,以便我们更直观的分析:
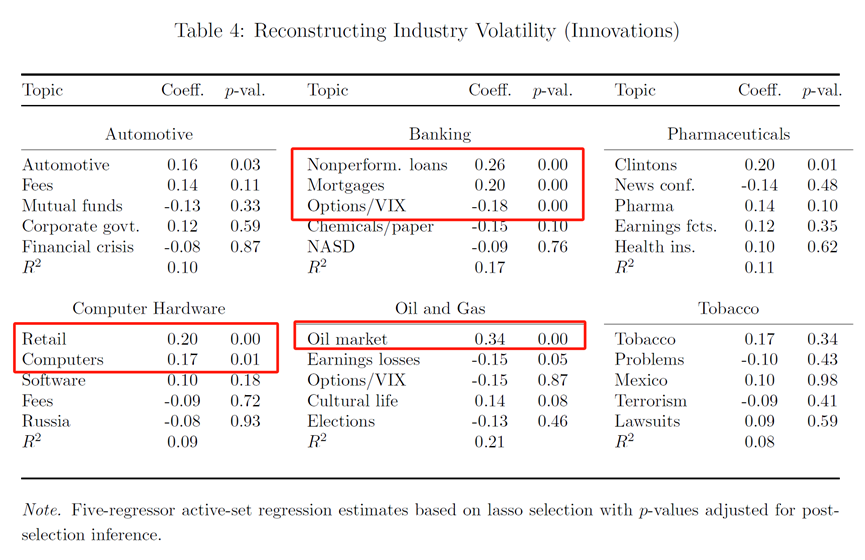
第一个例子是宏观经济,作者选了四个被解释变量代表宏观经济,分别是工业生产增长率、就业增长率、股票市场回报率(市值加权的美国股市指数的回报率)和股市波动性。回归的结果分别在表1的左上、右上、左下、右下,接下来我们逐图分析。
左上图是工业生产的对数增长率进行Lasso回归的结果。可以看到,“衰退”主题和“石油市场”与工业生产的对数增长率显著负相关。“衰退”的新闻关注度每增加一个标准差,工业生产增长下降0.38个标准差。
右上图中,被解释变量是非农就业率,与其显著相关的新闻主题有“衰退”、“铁路/卡车/航运”,虽然“伊拉克”和“克林顿”这些新闻主题也显著,但系数较小。“衰退”主题的新闻关注度每上升一个标准差,非农业就业率的变化率会下降0.61个标准差。
左下图中,为了保证回报率的序列不相关,作者将回报率进行了AR(1)处理。可以看到,“衰退”主题的新闻关注度每下降1个标准差,回报率的AR(1)增长0.35个标准差。“问题”也解释了0.19个标准差的下降,“问题”是一个负面主题,包括问题面临,最大的问题,大问题,事态恶化这些关键词。右下图的市场波动性(每月市场回报率的标准差)也是相同的结论。而且,这四个回归中,R2都超过25%,模型整体显著度很高。
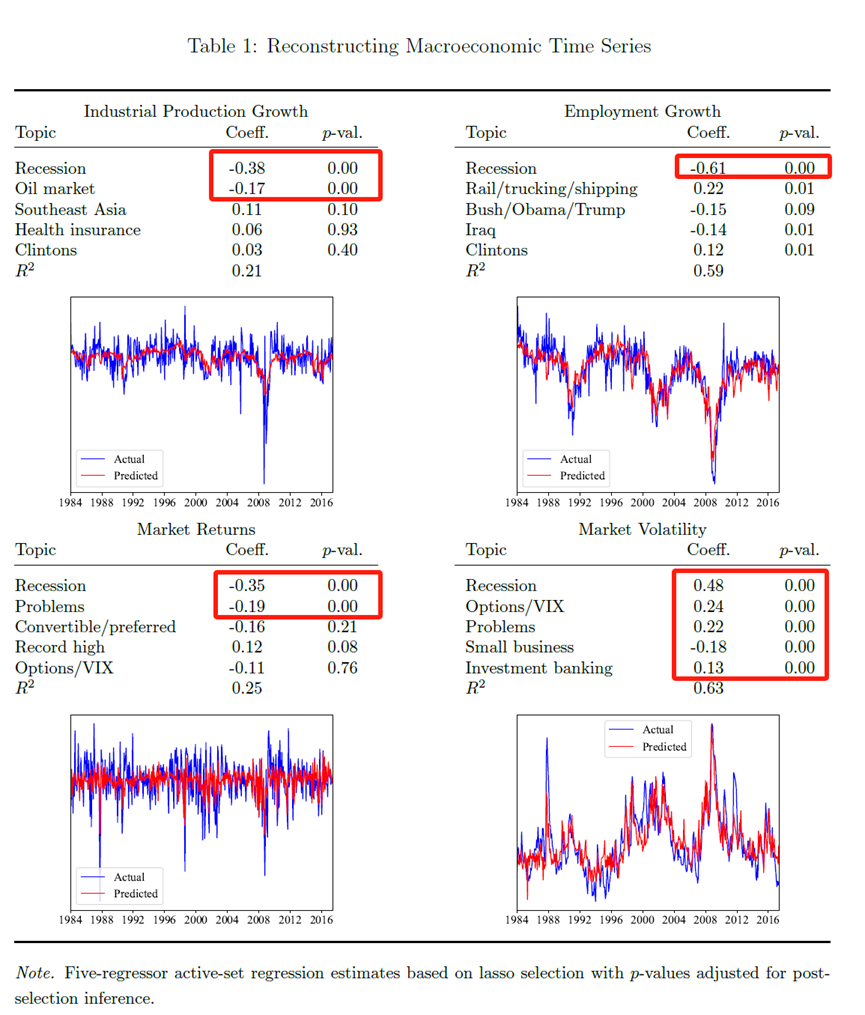
第二个例子是金融市场的融资活动。表3报告了四个例子,被解释变量分别是首次公开募股(IPO)的每月美元交易量、杠杆收购(LBO)的每月美元交易量、每月美国上市公司的破产次数、欧元区主权国家的平均信用违约互换(CDS)利差(由于数据可得性,样本自2002年起)。有意思的是,最后一个例子(表3右下图)里,受到惩罚的Lasso回归聚焦于支持欧洲主权债务的叙事,没有选择与金融危机和次级抵押贷款有关的新闻主题。模型的精度可见一斑。
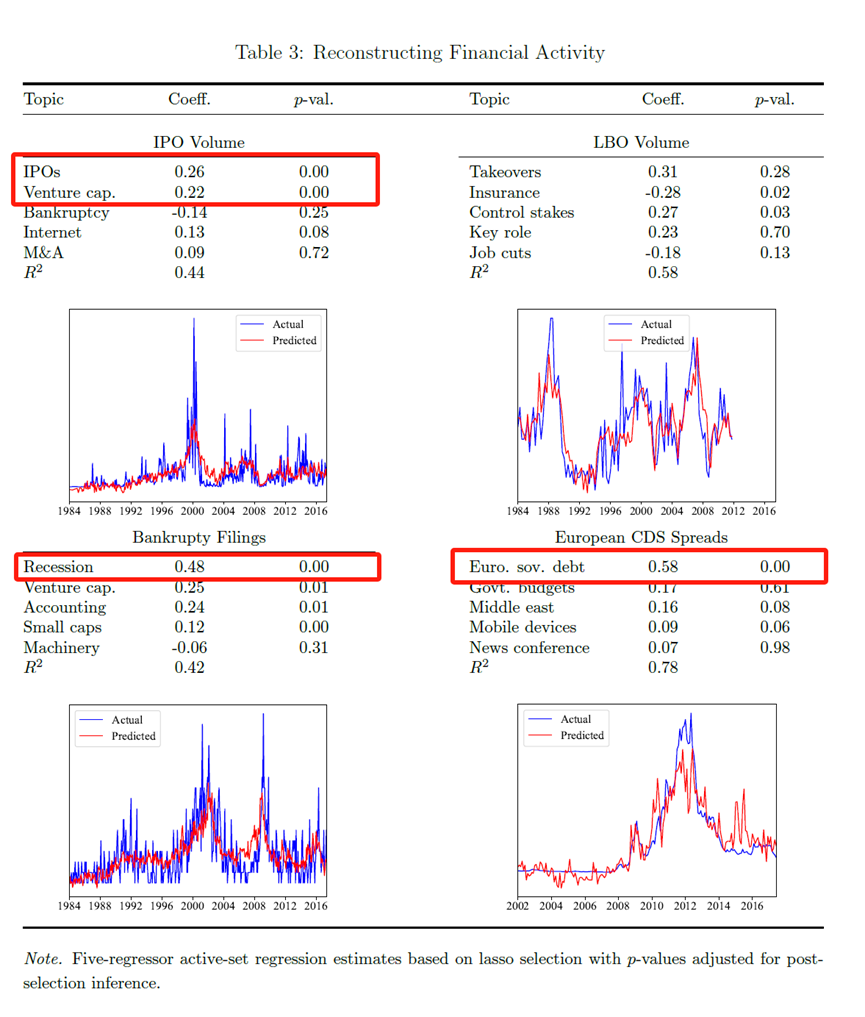
第三个例子是分行业的股票波动性与新闻关注度。作者的行业分裂是Ken French网站上的49个行业类别,并以该股票当月内日行业回报的标准差来度量股票波动性。为了防止结果和表1过于相似,作者对数据进行了两项预处理:(1)使用主成分分析找出最能代表行业的股票。(2)对这些股票的回报率进行调整,选取AR(1)进行回归。
表4报告了最相关的9个行业。比如,银行业就和“不良贷款”和“抵押贷款”等主题的新闻高度相关。计算机硬件行业(包括苹果、戴尔和惠普等公司)的波动性与“零售”、“计算机”和“软件”主题的关注最紧密相关。制药行业的波动性还与关注“克林顿”主题相关,可以看到比尔·克林顿的医保政策对于制药行业的巨大影响。当然也有一些很奇怪但很有意思的回归,比如“文化生活”新闻和石油和天然气行业的股票市值波动高度显著。
第四个例子是交互项。表1报告了以工业生产(国内一般叫工业增加值)增长率和非农就业率变化为被解释变量的两个例子。同样,也是让Lasso模型在180个主题构成的16,110种组合中,挑选5个最相关的组合。可以看到,大多数组合都包括“衰退”主题,这也证明,机器学习的非线性模型也许在经济解释中,会有更好的表现。
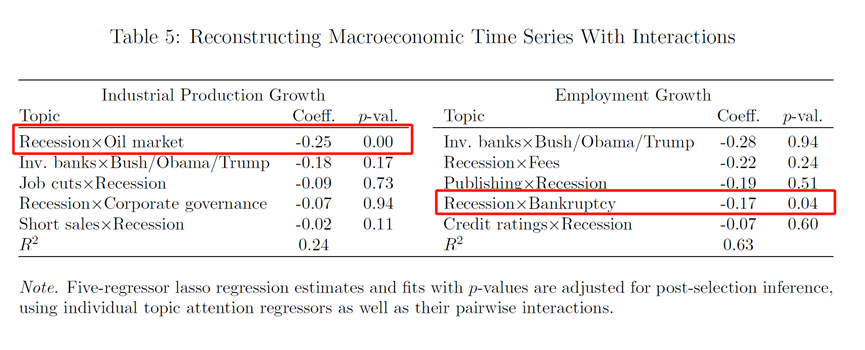
05
新闻关注度对于宏观经济的VAR冲击
5.1 包含新闻关注度的向量自回归(VAR)模型:
Baker等人(2016)提出的向量自回归模型,包括五个经济变量:经济政策不确定性(EPU)指数、标准普尔 500 指数、美联储基金利率、就业和工业生产。作者扩展了这一模型,将“衰退”这一新闻关注度替换了EPU指数。具体结果如图4所示。结果表明,“经济衰退”新闻关注度的冲击会对宏观经济产生重大影响,17个月后工业生产下降1.99%,20个月后就业下降0.92%。而且,与EPU指数相比,“衰退”新闻关注度带来的负面冲击在工业产出是EPU指数的2倍,在就业影响方面大约是EPU指数的3倍。
在图4的Panel-B,作者还做了一些稳健性检验,比如改变变量的顺序、同时控制EPU指数的影响,考虑密歇根消费者信心指数或 VIX 指数等。结论和Panel-A保持一致。可以看到,新闻关注,特别是与经济衰退相关的新闻关注,对产出和就业等宏观经济变量具有重大且相当大的影响。通过新闻关注捕获的媒体和公众情绪对关键经济指标有非常显著的影响。
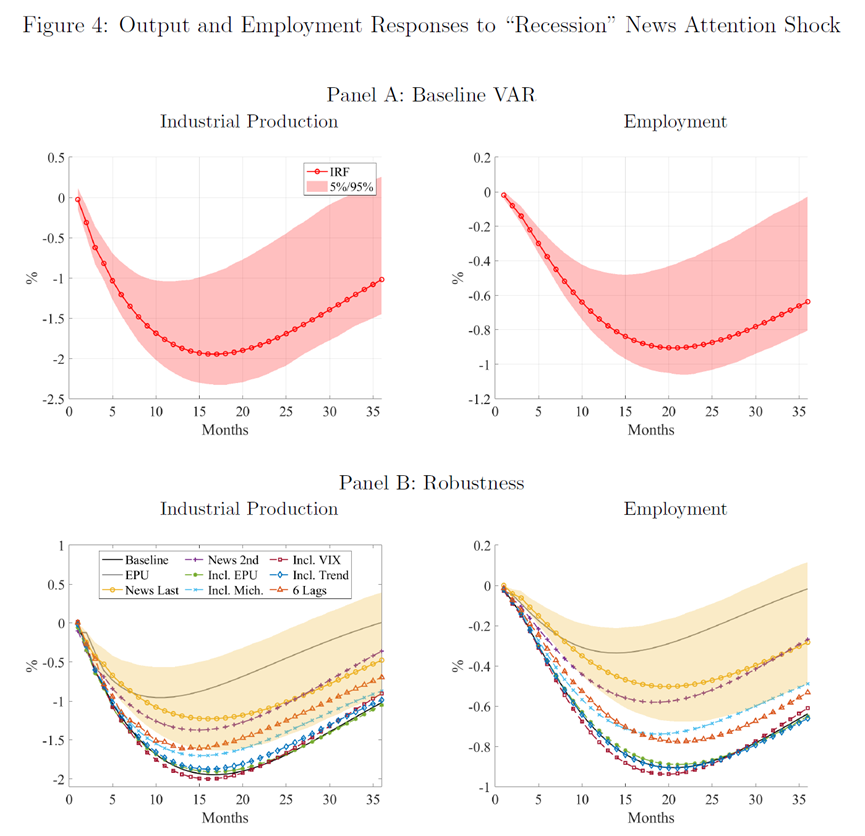
5.2 “衰退”主题的新闻关注度对股市回报率变化的冲击
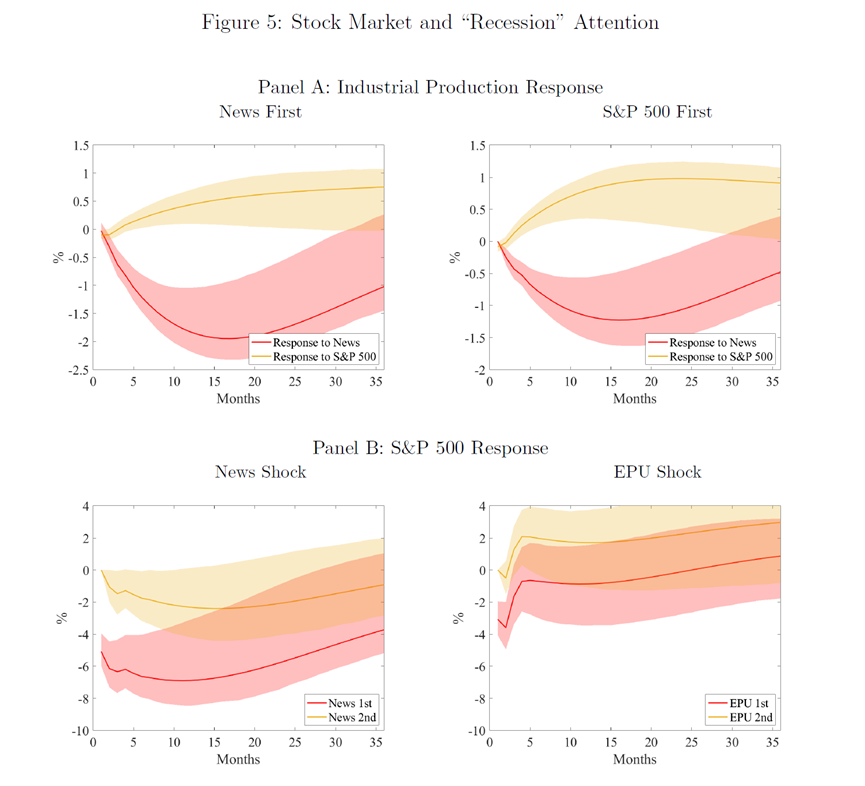
股价波动主要是由未来宏观经济预期变化驱动(Fama,1990)。在前文,我们也知道,股市回报率和新闻关注度有强烈的同使其相关性。这说明,新闻关注度可能捕获了一些经济信息。图5展示了“衰退”这一主题的新闻关注度与股市反应之间的关系。
对于Panel A,左图(News First)展示了工业生产对于新闻关注度冲击的反应,以及它对标普500指数(S&P 500)冲击的反应。红色线表示对新闻关注度冲击的反应,黄色线表示对标普500指数(S&P 500)冲击的反应。可以看出,工业生产对于“衰退”新闻关注度的反应在几个月后达到最低点。右图(S&P 500 First)在VAR模型中,把S&P 500指数的变量位置置于在“衰退”新闻关注度之前。但结果仍然类似。“衰退”的新闻关注度与工业生产的下降有强的负相关,且在90%的置信度中显著。
对于Panel B,左图(News Shock)显示了标普500指数(S&P 500)对“经济衰退”新闻关注度冲击的反应。当新闻关注度排在VAR模型中的第一位时,股市的初始反应是下跌大约5%,并且在接下来的一年中会有进一步的下跌。右图(EPU Shock)里,把“经济衰退”新闻关注度替换成了EPU指数,EPU指数的冲击对股市也有持续的负面影响。但影响幅度大约是“经济衰退”新闻关注度冲击反应的一半。作者在Panel B两个图的纵轴是同个度量衡,我们可以很直观的对比“经济衰退”新闻关注度和EPU指数的冲击效果。这些冲击,都在90%的置信区间(阴影区域)中显著。
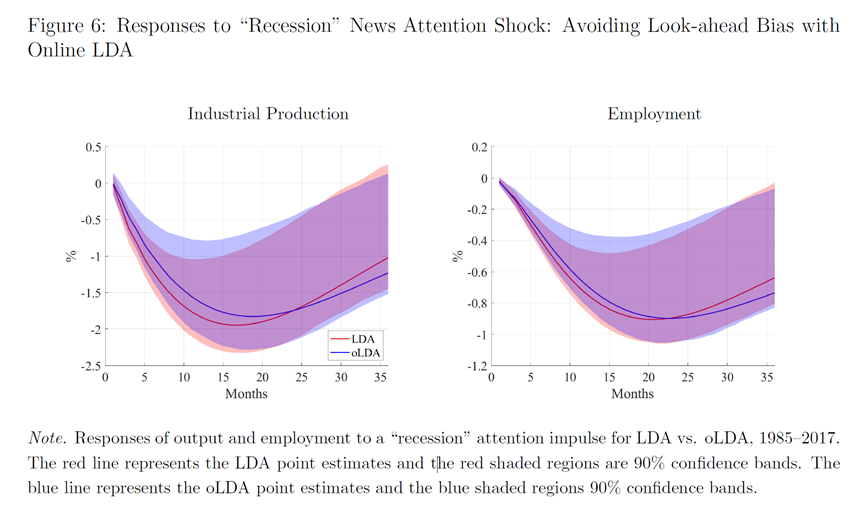
5.3 online LDA的VAR稳健性检验
图6展示了使用online LDA的稳健性检验,比较了两种估计:LDA(全样本)和oLDA(无前瞻性偏差)对于冲击结果的影响。红线代表LDA点估计,红色阴影区域代表90%的置信区间,蓝线代表oLDA点估计,蓝色阴影区域代表90%的置信区间。
短期来看,online LDA确实会导致冲击水平略微降低,但长期两者区别很小。在15个月时,使用oLDA估计的工业产出比正常水平低1.27%,而使用LDA全样本估计的工业产出低1.94%。在就业方面,使用LDA估计时15个月的反应从0.86%的下降减少到使用oLDA估计时的0.76%。这表明,尽管oLDA可能减少了前瞻性偏差,但这种减少并没有显著改变关于“经济衰退”新闻关注度冲击对工业生产和就业影响的总体结论。
5.4 扩大时间长度的稳健性检验
1984年之前,《华尔街日报》没有全文的数据,但有摘要的数据。为了提高结果的稳健性,作者将样本延申到《华尔街日报》创办初期的1890年,这已经几乎是经济史研究了,当前关于量化经济史的研究也主要集中于这个时期。
不过,作者的主题聚类是基于1984年到2017年的全文数据,即,1984年之前,1890年到1983年的数据,只是对1984年到2017年已经提取出的主题关键词的简单计数,并除以当期摘要词汇数,得到该主题的当年新闻关注度。
图7报告了1890年到2017年,超过一个世纪的“衰退”主题新闻关注度。其中,红色线是1984年前的新闻关注度,蓝色线是1984年后的新闻关注度。灰色阴影是NBER定义的经济衰退期。有趣的是,“衰退”新闻关注度通常早于“衰退”周期反应,并比“衰退”周期更早降低“衰退”相关表述,可谓是,春江水暖“新闻”先知。
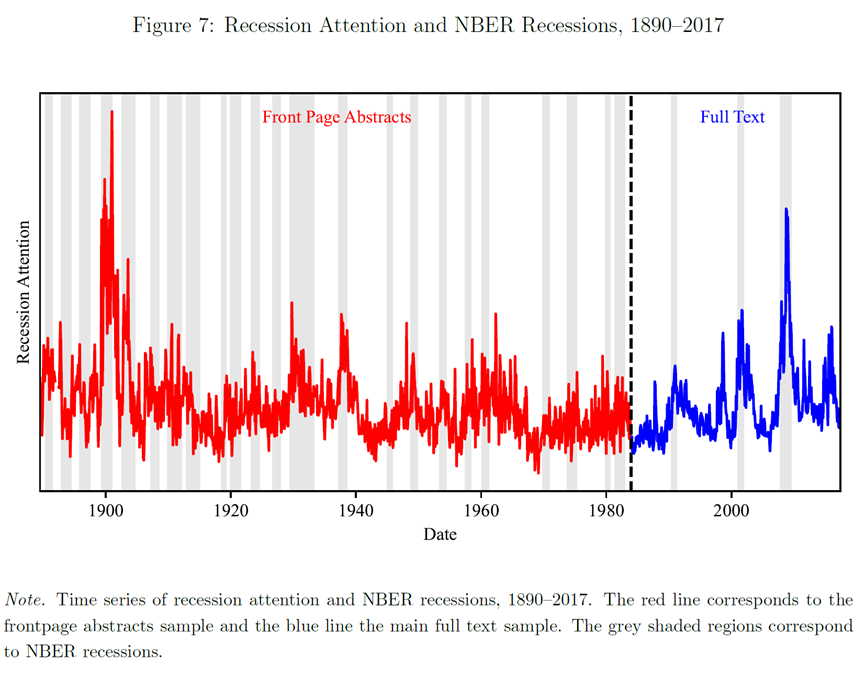
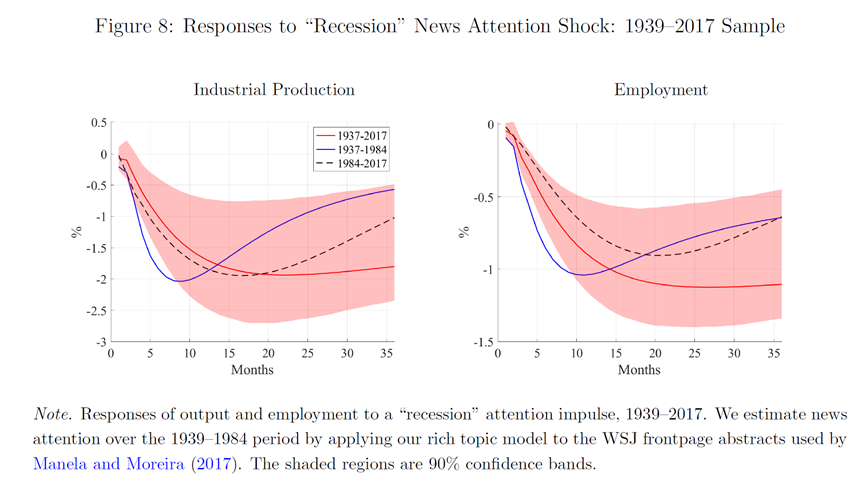
图8展示了1939年至2017年期间,对“经济衰退”新闻关注度冲击的工业生产和就业的反应。时间开始于1939年,主要是因为美国的非农就业数据是1939年开始公开。图中,红线表示整个时间段(1937-2017)的冲击反应,蓝线表示早期样本(1937-1984)的冲击反应,黑色虚线表示近期样本(1984-2017)的冲击反应。阴影区域代表90%的置信区间。
无论是长期样本还是近期样本,工业生产和就业对“经济衰退”新闻关注度冲击在短期内的反应都是相似的。在“衰退”新闻关注度上升后的20个月,工业生产和就业分别下降了大约2个和1个百分点。早期样本(1937-1984)并不显著,但趋势与长期样本一致。
5.5 在文本增强的VAR中选择关注度
前面,作者都是用“衰退”是唯一的新闻主题变量。之后,作者使用交叉验证的Group Lasso回归来解释,为什么“衰退”是最好的新闻主题。。Lasso回归是一种用于选择变量的统计方法,它通过引入一个惩罚参数λ来减少模型中的变量数量。Group-lasso是Lasso的一种变体,适用于选择变量组而不是单独的变量。基于此,作者设计了一个基于Group Lasso增强的VAR模型。这个模型中,作者考虑了包括180个新闻关注度序列以及经济政策不确定性指数(EPU)、波动率指数(VIX)和密歇根消费者情绪指数在内的一系列预测变量。这些预测变量被视为影响宏观经济变量(如标普500指数、联邦基金利率、就业和工业生产)的潜在因素。
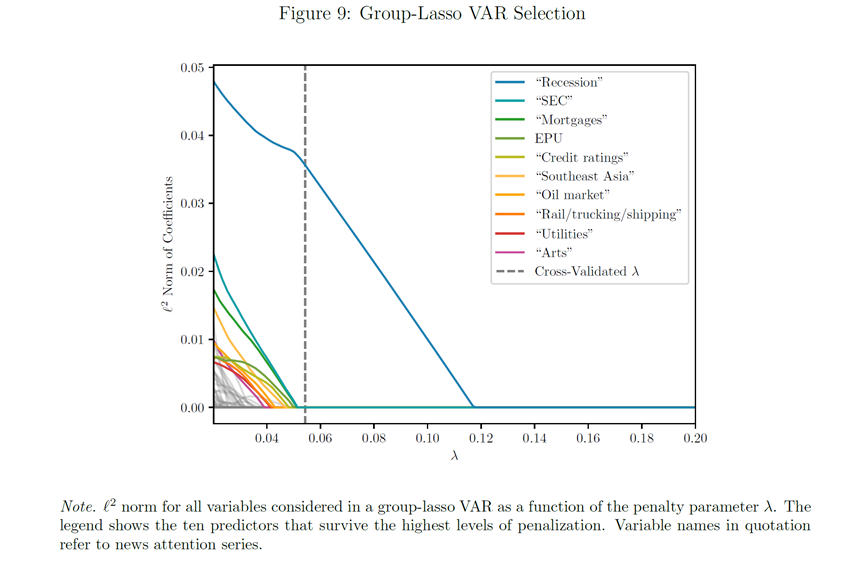
图9展示了Group-Lasso VAR回归模型的结果。横轴λ表示惩罚参数的大小,纵轴表示每个预测变量组的系数的ℓ2范数。随着λ的增加,更多的预测变量因为其系数被惩罚到零而被模型剔除。图例中列出了在高惩罚下仍然被保留的十个预测变量,它们根据统计重要性从上到下排列。
从图中可以看出,“经济衰退”新闻关注度(Recession)是所有变量中最重要的预测变量,因为它的系数范数在所有λ值下都很高,这表明它对预测宏观经济变量具有显著的贡献。“经济衰退”新闻关注度的预测贡献超过了EPU、VIX和消费者情绪指数。
λ=0.054(图中虚线),十倍交叉验证确定这是平均预测平方误差最小的模型,此时模型只有一个新闻关注度主题,即“经济衰退”,验证了本文结论。
5.6 机制分析:新闻为什么能预测经济?
至少有四个方面:(1)商业新闻概括了未来的预期生产力;(2)新闻里包括了商业周期相关的噪声,这些噪声本身会影响宏观经济的波动;(3)《华尔街日报》采访的很多人都是经济代理人们,这些有影响力的资产管理者、企业高管和政策制定者本身就在影响经济;(4)新闻的生产受到媒体公司激励的影响,这反过来又受到消费者需求的影响(Mullainathan和Shleifer, 2005; Gentzkow和Shapiro, 2010)。因此,新闻文本还反映了媒体倾向,这反过来又可以影响经济动态。
5.7 叙述性检索
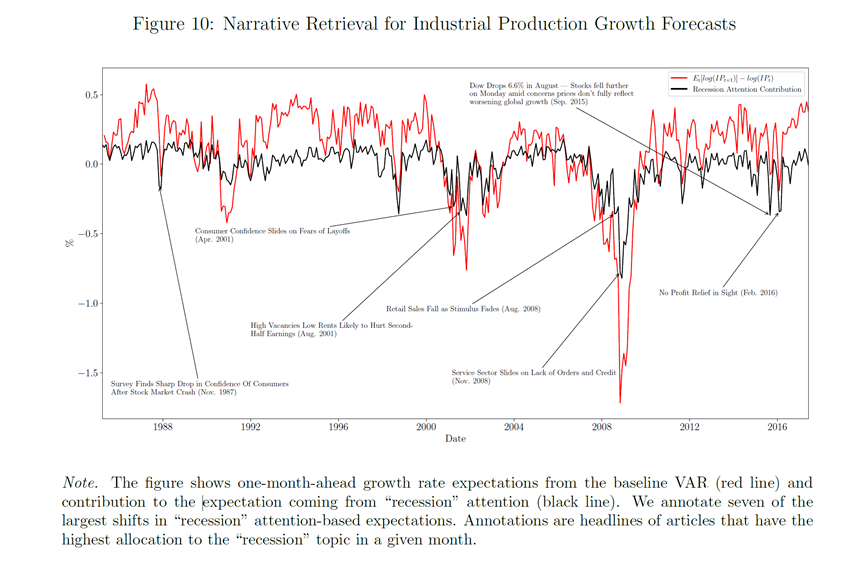
图10展示了新闻关注度如何影响VAR模型的预测结果,直接抓取了预测宏观经济的几则新闻报道,以帮助我们更好的理解新闻叙事的作用。图中的红线表示基于基线VAR模型的一月前工业生产增长率预期,而黑线表示“经济衰退”关注度对这些预期的贡献。换句话说,红线是VAR模型预测的输出增长率,而黑线显示的是当考虑了“经济衰退”新闻关注度后,这些增长预期如何变化。
图10中还标注了七个由“经济衰退”关注度转变引起的预期工业生产增长率最大月度下降点,并分配当期的导致“经济衰退”关注度月度变化的文章标题。例如, 2001年4月的“由于裁员担忧消费者信心下滑”和2008年11月的“股市崩溃后消费者信心急剧下降”与公众的经济预期有强相关。
看新闻买股票,能不能赚钱?
06
看新闻来购买股票是否可以?作者对比了几种策略的表现,并报告夏普比率、预期回报、预期回报的相应t统计量、信息比率(IR)、最大损失(即该策略赚取的最低回报),和偏度。
具体如表6所示。几种策略从左到右分别是,直接买入并持有策略、通过主题建模提取“衰落”主题来预测股市波动并买入、修正后的主题建模提取“衰落”主题再预测未来波动买入、直接计算“衰落”词汇的次数再预测买入、通过经济不确定指数(EPU)预测未来波动买入、2008年提出的Goyal-Welch策略(一种常见的多因子交易策略)、经过Lasso修正后的Goyal-Welch策略。从表6的结果,可以看到,看新闻买股票,确实可以赚钱。
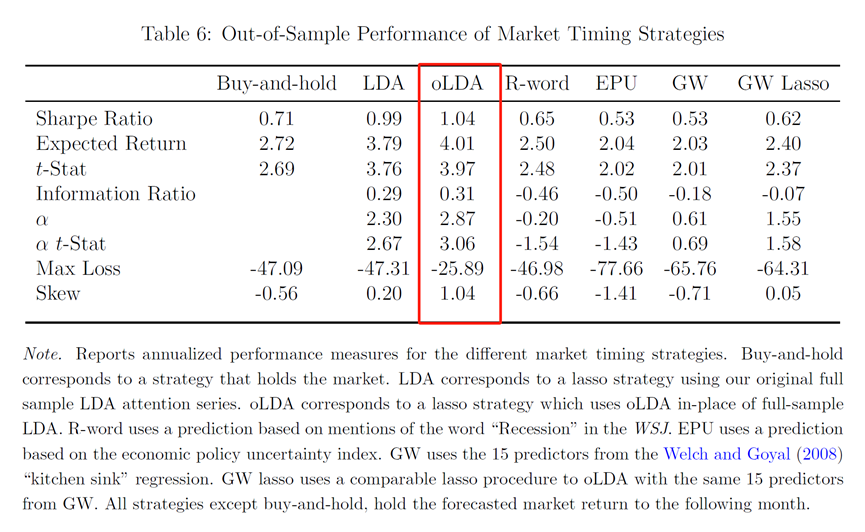
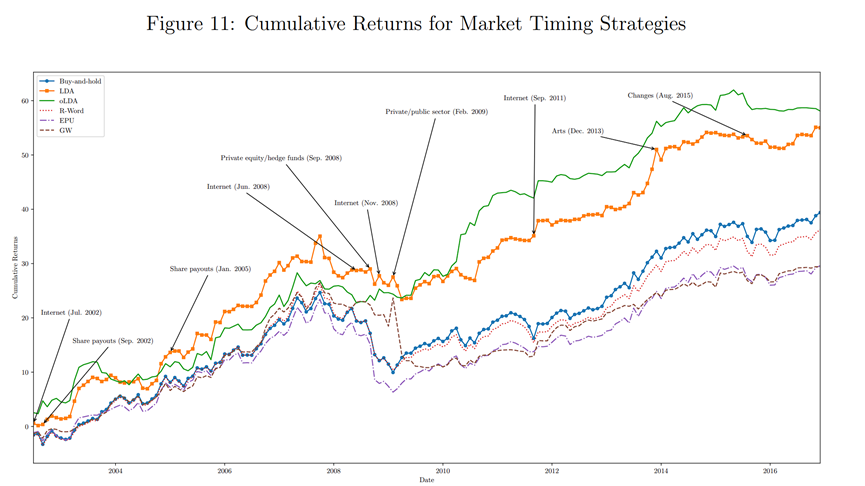
作者还提取了影响赚钱的《华尔街日报》相关文章主题以解释,oLDA策略为什么可以赚钱。简单来说,这得益于《华尔街日报》在某些事件的提前报告。比如,2009年2月《华尔街日报》报告了美国可能将重新规范金融业,大部分策略普遍低估了这一事件的影响,而oLDA策略预期,未来市场回报会低于市场平均水平,并采取了规避策略,从而在未来赚取了超额收益。
07
结论
一直以来,怎么用微观指标来推断宏观经济状况?这是经济学家的重要任务之一。但数据驱动的机器学习方法在社会科学的应用中,总缺乏思想深度。本文介绍了一种基于机器学习的主题建模预测经济状况的方法,并考虑了在主题建模中,可能遇到的各种问题。比如:虽然现在文本分析使用的很广泛,但很少有文本分析考虑新闻文本结构本身。本文使用无监督的主题建模技术,将过多的超高维度文本降维到相对低维度的“主题”中,这很像聚类。作者还计算了不同主题在新闻文本中的比例(即,新闻关注度),这不仅有效总结了《华尔街日报》的历史主题,还在时间层面有效总结了新闻主题演变。这为我们在经济学乃至其他社会科学领域运用主题建模方法提供了借鉴。
当然,我国缺乏类似《华尔街日报》这样影响力巨大、历史悠久的财经报纸,但我国的互联网财经新闻数据量是更庞大的。如此清洗这些财经文本数据?作者给出了很好的示范。
论文作者已经在www.structureofnews.com公布了他们对《华尔街日报》的主题建模模型,您可以随意选择主题数量进行自己的感兴趣主题的建模。欢迎感兴趣的学者可以下载使用。
推文作者:林泽腾,香港科技大学数据科学与分析学域研究生,南方科技大学访问研究生。本推文从易于传播的角度,跳过了大部分数学解释,必然有很多纰漏,如有错误,请联系zetenglin@yeah.net。
Abstract
We propose an approach to measuring the state of the economy via textual analysis of business news. From the full text of 800,000 Wall Street Journal articles for 1984–2017, we estimate a topic model that summarizes business news into interpretable topical themes and quantifies the proportion of news attention allocated to each theme over time. News attention closely tracks a wide range of economic activities and explains 25% of aggregate stock market returns. A text-augmented VAR demonstrates the large incremental role of news text in modeling macroeconomic dynamics. We use this model to retrieve the narratives that underlie business cycle fluctuations
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号