
图片来源:必应
原文信息:
Cao, S., W. Jiang, B. Yang, and A. L. Zhang. 2023. How to Talk When a Machine Is Listening: Corporate Disclosure in the Age of AI. The Review of Financial Studies 36.
01
引言和研究假设
随着机器学习技术和NLP(自然语言处理)工具的快速发展,许多买卖决策都转而由机器做出,公司也逐渐认识到其财报的主要读者并非人类,而是机器。对于希望实现与利益相关者的沟通、以获得预期收入的公司,可能需要调整他们在人工智能时代谈论公司财务、品牌和预期的方式。
当前已有许多研究引入机器学习对财报、新闻进行文本分析,但鲜有人研究这一机制的“反馈效应”(feedback effect):当公司意识到接收、分析其信息的对象是机器,他们会如何应对?本篇文章采用了三种方式定义“machine readership”(机器对公司财报的关注度):机器下载量(Machine downloads),与AI相关的机构投资者持股比例(AI ownership),以及机构投资者的AI人才供给(AI talent supply)。
文章构建的理论联系了面向机器读者的公司披露与证券交易定价。公司通过两个层面管理基本面的真实质量:语调和噪音。财报文本的机器可读性越高,噪音越小。在一场交易游戏中,玩家包括机器交易者(如读取财报并做出投资决策的AI),噪音交易者,和制定价格的做市商。公司在一开始希望采用更积极的语调和更高的机器可读性,但最终会受到定价错误(包括声誉问题和诉讼风险)和技术升级成本的限制。为机器交易者提供更准确的信号会增加他们和做市商之间的信息不对称,迫使做市商在交易时提高价格敏感性,以避免被机器交易者利用。最终,当采用机器交易的投资者越来越多,公司也会更多地进行语调管理,导致股票流动性下降,市场的信息不确定性提升。
本文的边际贡献体现在以下两方面。第一,文章丰富了从SEC获取并传播信息的文献族,为人类如何应对人工智能时代的到来提供了新的研究视角;第二,文章首次研究了机器学习在金融领域的“反馈效应”,市场预期会影响公司经理的信息集和决策;公司投资者关系部门也会使用算法提前测算AI对财报的判断是否符合其目标结果。如果不及时训练模型,机器学习算法可能成为公司“操纵财报”的工具。
数据来源与描述性统计
02
文章关于财报下载量的数据来源于SEC的EDGAR(电子数据收集、分析和检索)系统,原始数据集中的每个观测值都包含访问者的IP地址、时间段和访问者下载文件的唯一登录账号信息。公司层面控制变量来自WRDS等数据库。文件下载统计的时间范围为2003.1 - 2017.6,包括81,075份年报和243,532份季报。选择SEC监管文件的原因是,此类信息披露是公司和市场交流的主要渠道,且读者类别相对公司而言外生。
4文章采用了三种方式定义机器读者数(machine readership)。第一个指标为机器下载的财报数目(Machine downloads),即统计财报发布7天内的总下载量(同一IP地址在某天下载50份以上报告,即被视为机器),同时使用其余渠道下载量、总下载量、机器下载量比例作为控制变量。第二个指标为与AI相关的机构投资者持股比例(AI ownership),定义为具有AI能力的投资公司(从招聘广告中判断是否有与AI相关的岗位需求)持有的已发行股票的比例。第三个指标为AI人才供给(AI talent supply),定义为投资者总部所在地的AI人才供给量,并采用其持股比例加权。
第二类变量为财报文本的机器可读性(Machine readability),包括表格获取难度(Table extraction),数字获取难度(Number extraction),表格可读性(Table format),信息完整度(Self-containedness),和文本标准化程度(Standard characters)。将以上五个维度的指标标准化求得Z-score,并取平均计算出文本的机器可读性。
第三类变量用于衡量文本的(负面)情绪和语调。文章选择了两本常用词典,其一是哈佛大学通用调查词典(Harvard General Inquirer IV-4 psychological dictionary)中被归类为“负面”词汇数的比例(Harvard sentiment);其二是LM词典(相关论文发表于2011年,其附带的单词列表已成为行业和学术界情绪分类算法的主要词典)中被归类为“负面”词汇数的比例(LM sentiment),包括诉讼、不确定性、弱语气、强语气词。同时,文章构造了二者比例差异指标(LM – Harvard sentiment),以度量LM词典发布后公司使用词汇类别的变动。
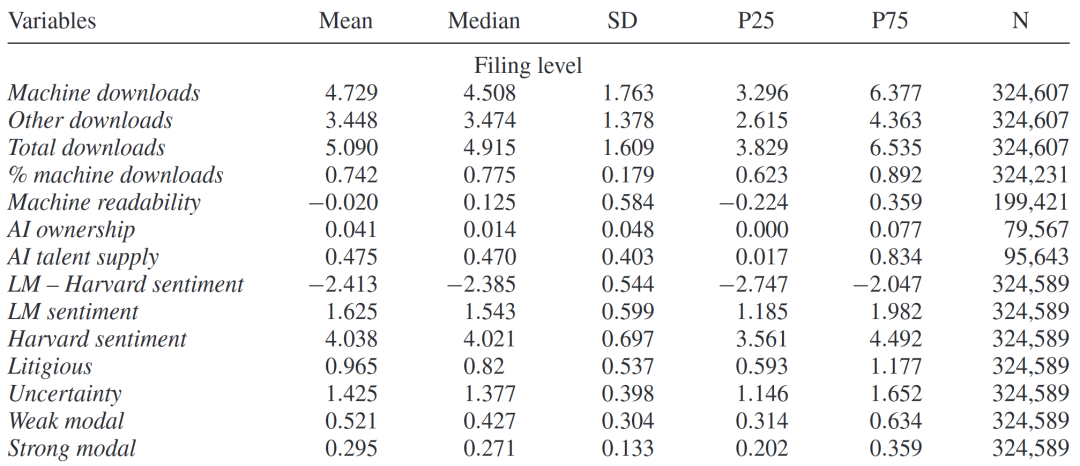
样本描述性统计结果
03
AI读者和信息披露的机器可读性
首先,文章验证了机器下载量是度量“AI读者关注度”的良好指标。通过使用ARIN Whois数据库,手动将机器下载量最高的IP地址与样本期内作为13F文件管理器出现在Thomson Reuters 13F数据库中的投资者进行匹配,发现具有较高机器下载量的IP地址大多为量化基金公司,这说明机器下载量可以较好地代理“AI读者数目”。
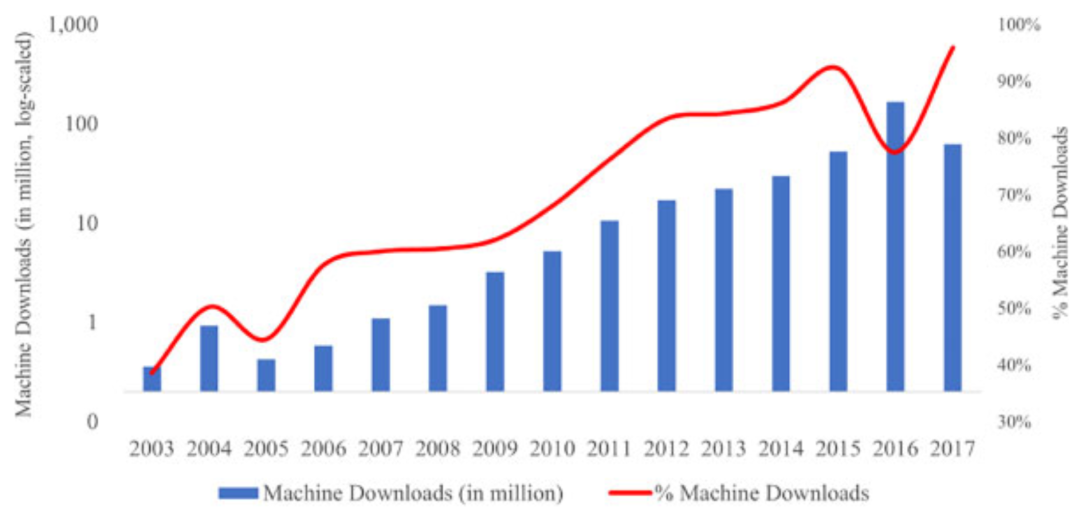
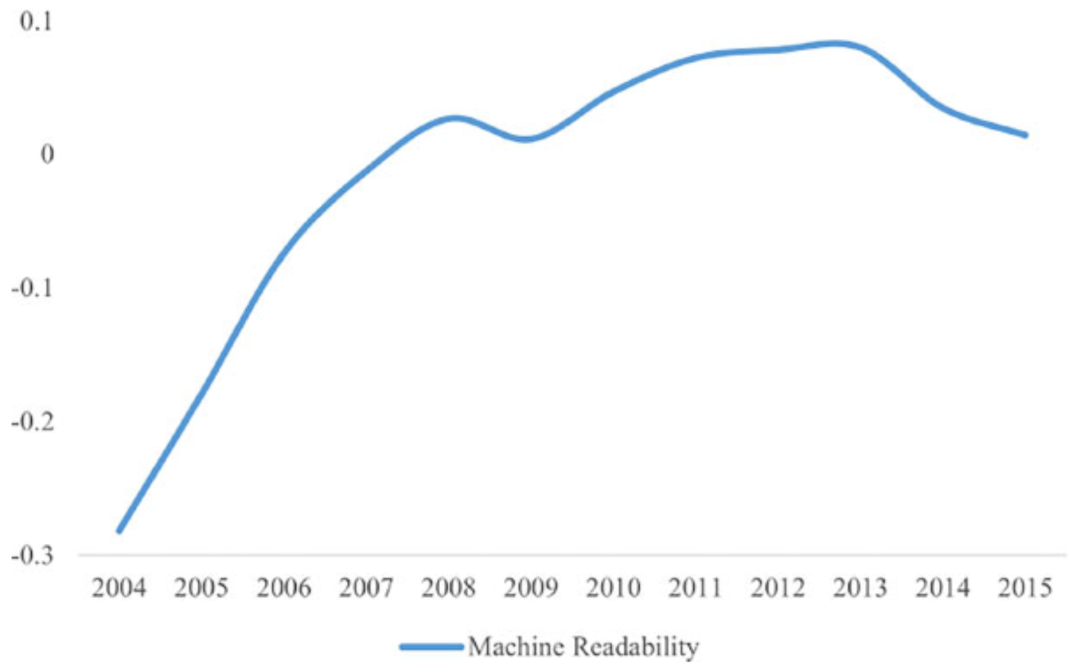
AI读者数目和文本机器可读性的时间趋势
接下来,文章探讨了AI读者数目和财务报告文本的机器可读性之间的关联。回归模型如下:
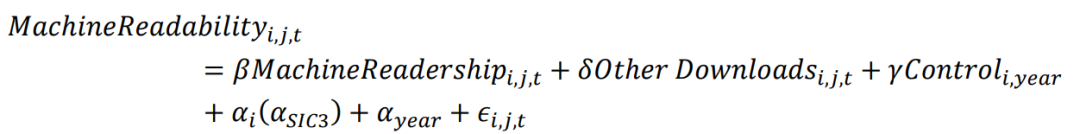
核心解释变量为AI读者数目,被解释变量为机器可读性,并添加了年份和个体(或行业)固定效应。回归结果(如下表)表明,机器下载次数越多,文本的机器可读性越高。其余下载渠道的回归系数则不显著。进一步将因变量替换为机器可读性的升级(MR upgrade,表示一份文件比前一年的平均机器可读性增加一个标准差),回归结果仍正向显著,说明机器下载次数的变动可以较好地预测机器可读性的升级。
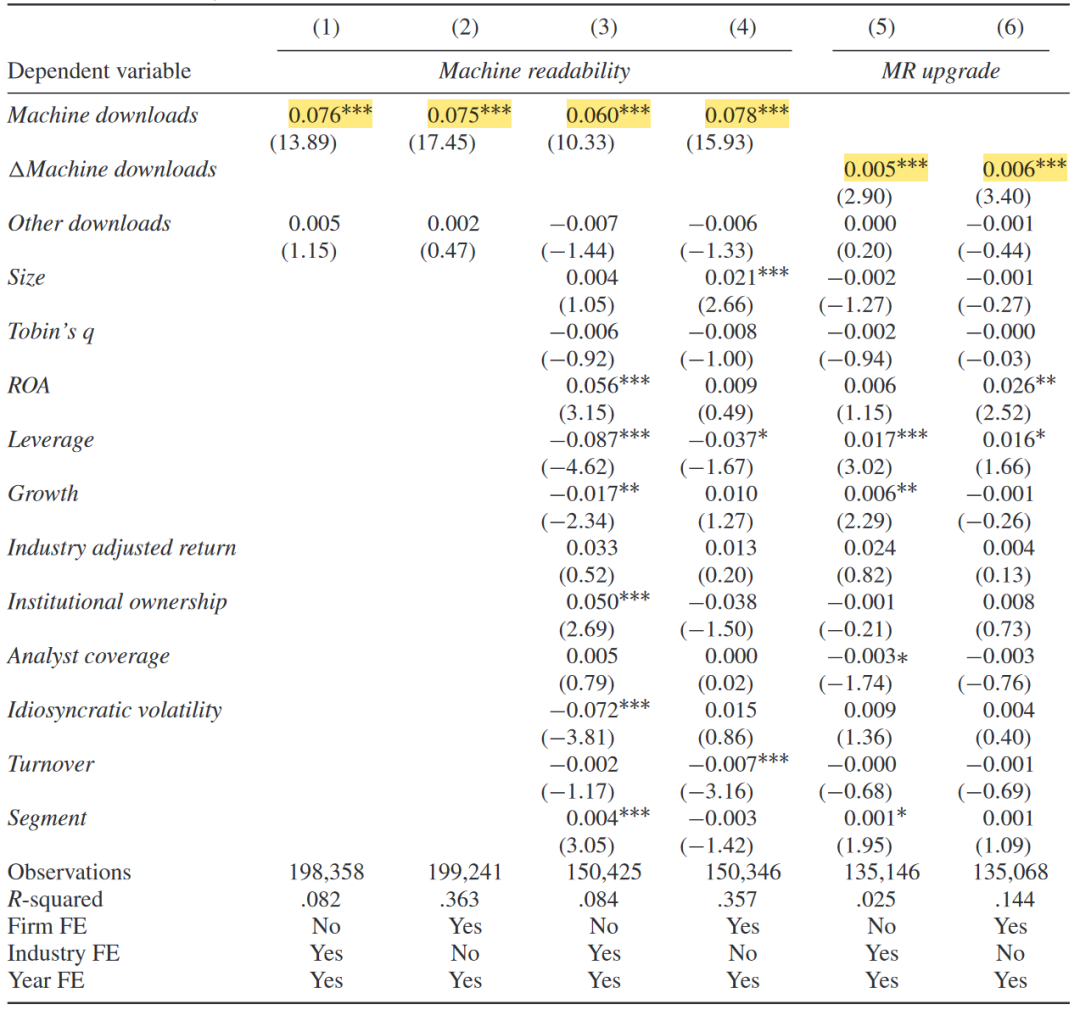
机器下载量和文本的机器可读性
进一步,将因变量机器可读性拆分为五个子指标,回归结果(如下表)表明,机器下载量的提升会显著提高各层面的机器可读性。最后,将自变量换为AI相关的机构投资者持股比例和AI人才供给。AI持股比例(AI人才供给)每增加一个标准差,机器可读性将提升0.04(0.12)个标准差,验证了基准回归结果的稳健性,且AI人才供给相对于AI文本分析的广泛应用外生。
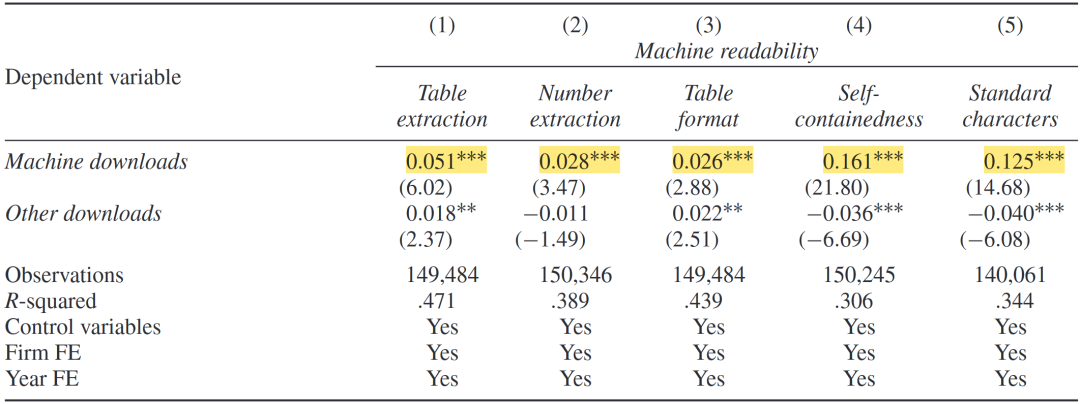
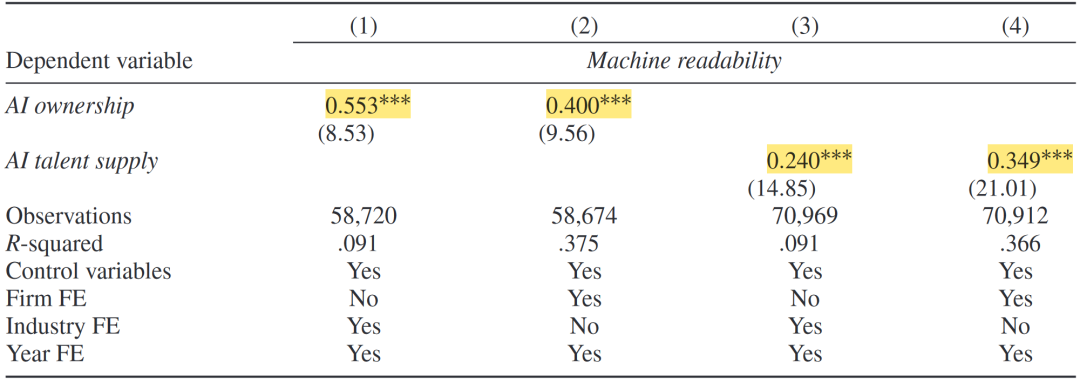
机器可读性和机器下载量的替代指标检验
在本章节的最后,文章讨论了机器下载量和可读性对交易和信息传播的影响。随着机器的“入场”,交易速度和信息传播速度都会提升。通过使用NYSE Trade and Quote (TAQ) 的高频交易数据,构建以下回归模型:

文章首先讨论了AI关注度和文本可读性对交易的影响。以Time to the first trade(EDGAR系统上发布财报和第一次后续交易之间的时间间隔)为因变量,机器可读性和下载量的交乘项为核心自变量回归,结果发现对于机器下载量较多、且机器可读性较高的公司,第一次后续交易时间将缩短。接下来,文章以Time to the first directional trade(以低于(高于)最终价值的价格第一次买入(卖出)的交易)为因变量,结果相似,第一次“有效”交易时间也将缩短。
文章进一步讨论了机器下载量和可读性对信息传播的影响。以买卖价差为因变量,机器下载量和After(财报发布后取值为1)交乘项为核心自变量回归。系数正向显著,表明引入AI提升了买卖价差。由于AI能够更快读取信息并做出交易决策,正如理论模型所推导,市场信息不对称程度将会提升。
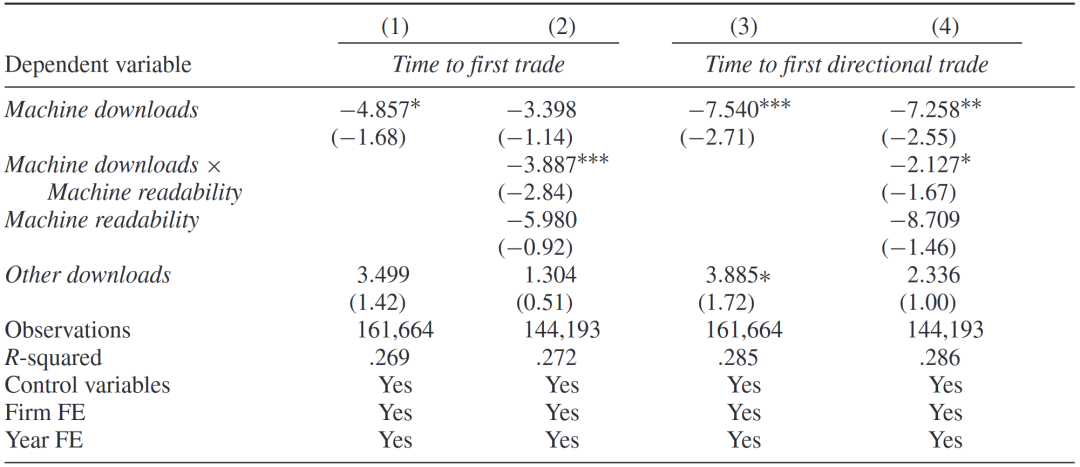
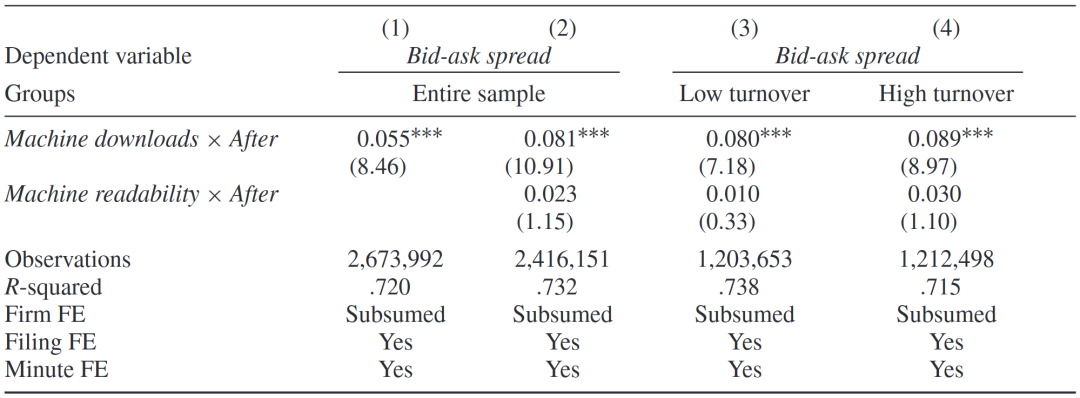
机器下载量和可读性对交易和信息传播的影响
AI时代下的文本情绪和语调管理
04
管理者通常希望以积极的态度来描述他们的商业活动和前景,以吸引利益相关者或从中获益。早期文献主要采用哈佛词典中定义的正负面词汇衡量文本情绪,但这一词典在分析财报情绪时不够“金融”。2011年LM词典的诞生标志着衡量金融文本词典的出现,并成为情绪校准算法中使用的主要词典。以LM词典的发布作为随机外生事件,构建以下模型:
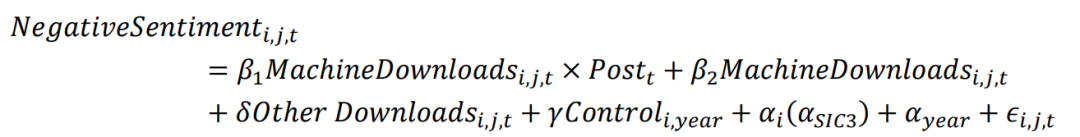
机器下载量和Post(2011年LM词典发布后)交乘项为核心解释变量,负面情绪(以哈佛词典、LM词典和二者之差度量)为被解释变量。对于机器下载量高的公司,LM词典发布后其以LM词典度量的负面情绪显著降低,而以Harvard词典度量的负面情绪有所提升。这表明公司倾向于使用哈佛词典中的负面词汇来规避LM词典所定义的负面词汇。该结果通过了平行趋势检验,并排除了替代解释:2011年后机器下载量高的公司更倾向于规避LM词典中的负面词汇不是因为金融危机等负面事件的发生。
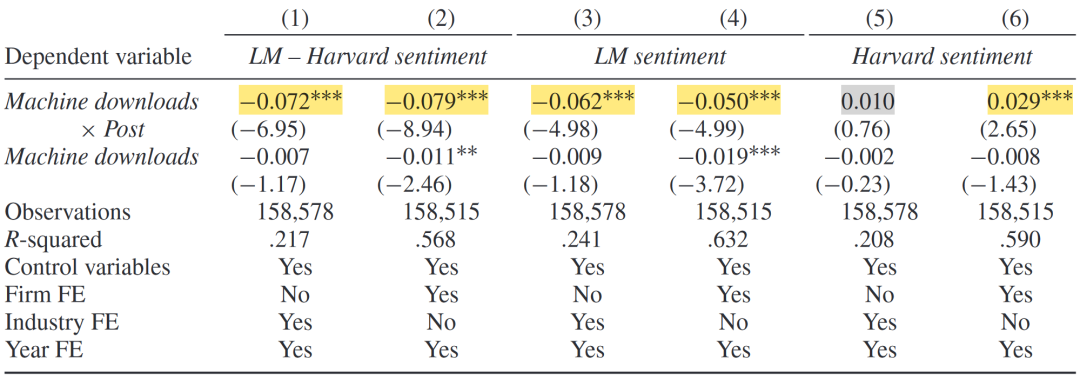
机器下载量和负面情绪管理:以LM词典发布为准实验
由于LM词典也包括四种类型的“语调”词汇——诉讼、不确定性、弱语气词、强语气词,文章进一步探讨AI时代下公司对(除负面情绪外)其他文本语调是否存在管理。回归结果均显著为负,表明2011年后公司财报会有意规避此类词汇。
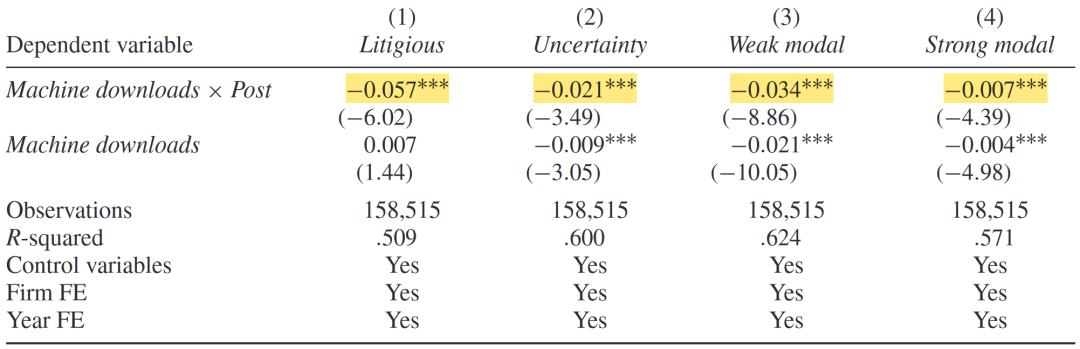
机器下载和其他文本情绪管理
05
样本外检验:最新技术和音频语调
由于LM词典发布时间较早,为探讨近年来最新技术对财报文本可读性的影响,文章采用谷歌2018年开发的用于NLP的BERT模型进行文本情绪识别。由于2016年后SEC不再公布财报下载量的数据,回归的自变量为与AI相关的机构投资者持股以及AI人才供给。结果表明,AI关注度更高的公司,更倾向于规避负面词汇,与基准回归结论相符。
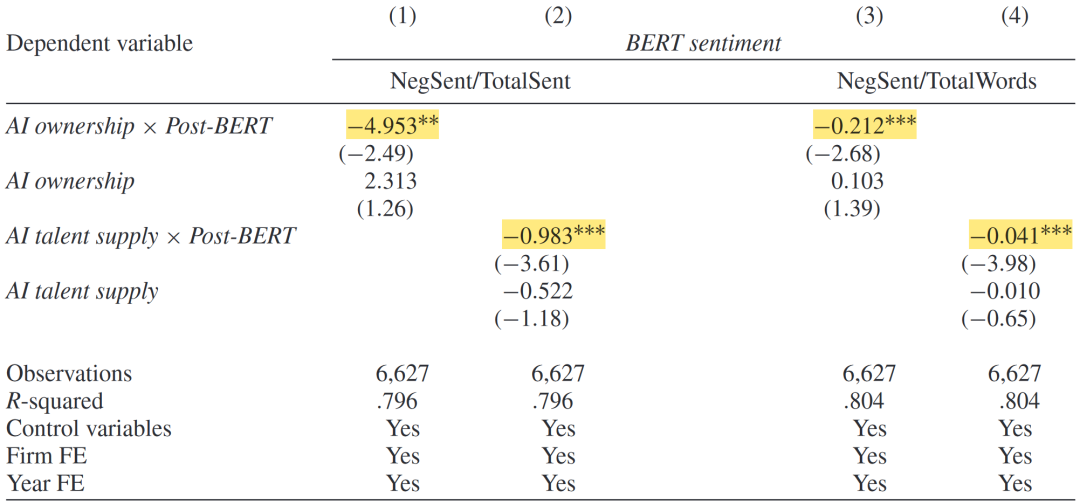
基于最新技术(BERT)的情绪管理
如果公司意识到他们的信披文件会被机器解析,他们也应该意识到,AI可能会使用语音分析技术来提取管理层演讲中包含的语调和情感信号。由于电话会议是公司与机构投资者、分析师直接交流的平台,且经理的演讲语调与公司基本面高度相关,文章爬取了2010-2016年EarningCast上与盈余相关的电话会议语音记录,并采用pyAudioAnalysis机器学习程序进行分析,构造了情绪积极度(Emotion valence)和兴奋程度(Emotion arousal)两个指标。将构建的两组情感指标对机器下载量回归(机器下载量能够作为公司受AI关注度的良好反映),发现对于机器下载量较多的公司,经理语调会更积极,情绪也会更高涨。
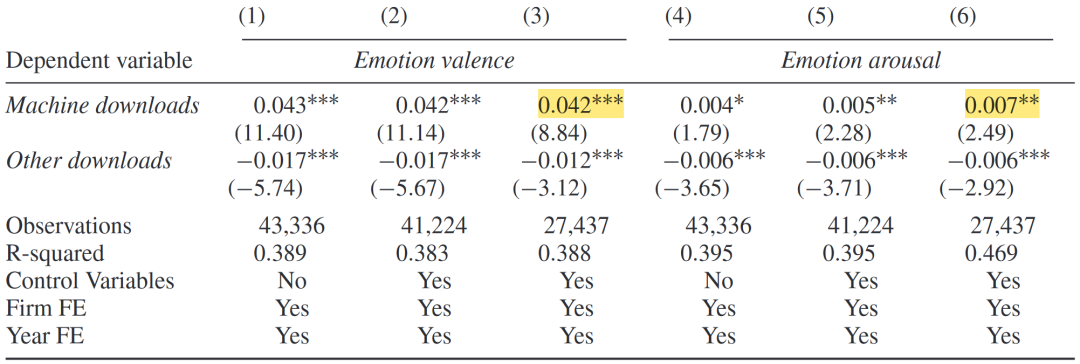
机器下载量与电话会议中的情绪管理
结论
06
本篇文章研究了以算法交易员和量化分析师群体为主的“AI读者”如何重塑公司的信披行为。研究表明,AI读者的增加促使公司使用更适合机器解析和处理的方式书写信披文件,突显了人工智能在金融体系中不断提升的作用及其对企业决策的潜在影响。具体而言,公司可以通过管理情感和语气的表达来迎合AI读者,例如,相对于被人类认为负面的词汇,公司可以差异化地避免使用被算法认为负面的词汇。CEO也倾向于在电话会议等场合努力展现出对使用软件评估有利的声音特质。
同时,本文首次识别了“反馈效应”,即公司知道其潜在读者是AI后,如何调整与外界沟通的方式。反馈效应可能导致操纵和勾结,提升市场信息不对称程度。技术的进步意味着需要更多研究来了解人工智能对金融市场和社会的影响。
Abstract
Growing AI readership (proxied for by machine downloads and ownership by AI-equipped investors) motivates firms to prepare filings friendlier to machine processing and to mitigate linguistic tones that are unfavorably perceived by algorithms. Loughran and McDonald (2011) and BERT available since 2018 serve as event studies supporting attribution of the decrease in the measured negative sentiment to increased machine readership. This relationship is stronger among firms with higher benefits to (e.g., external financing needs) or lower cost (e.g., litigation risk) of sentiment management. This is the first study exploring the feedback effect on corporate disclosure in response to technology.
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}