
图片来源:AI生成
论文来源
Ali Almelhem, Murat Iyigun, Austin Kennedy, Jared Rubin, Enlightenment Ideals and Belief in Progress in the Run-up to the Industrial Revolution: A Textual Analysis, The Quarterly Journal of Economics, Volume 141, Issue 1, February 2026, Pages 263–314
01
引言
2025年诺贝尔经济学奖得主乔尔·莫基尔(Joel Mokyr)认为,17世纪启蒙运动所激发的创造性精神,以及人们对社会进步与科技发展的信念,深刻影响了英国思想家、发明家和工匠的经济行为,进而推动英国迈入工业革命与现代经济增长时代。
Mokyr 的论证已经相当丰富且具有较强说服力,但仍存在两个方面的证据缺口。一方面,尽管思想家和科学家在这一时期普遍持有“进步”观念,但工业革命的真正推动者更多是工匠、手工业者以及技术实践者。那么,这些进步思想是否真正传播到了工匠和手艺人群体之中?那些与工业和技术相关的书籍与文本,是否同样使用了以“进步”为导向的话语体系?另一方面,既有研究主要集中于对少数思想家或科学家的定性分析,而启蒙运动时期英国产生了数十万部书籍,仅依靠个案研究难以全面把握社会思想结构的整体变化。
为此,作者运用文本分析方法,对1500—1900年间英国出版的264443份文本进行主题归类,追溯工业革命前几个世纪中科学、宗教与政治经济语言中“进步”(progress)观念的演变过程,从而从文化与思想层面为英国工业革命提供新的解释。
02
数据和方法
2.1. Hathitrust数字图书馆的数据
HathiTrust数字图书馆(HDL)由美国十大学术联盟与加利福尼亚大学系统合作建立,主要用于数字文献存档与学术研究。其资源包括Google、Microsoft和互联网档案馆等机构数字化的版权及公共领域文献,并为大规模文本挖掘与算法分析提供计算基础设施。HDL目前收录全球150余所高校超过1700万册文献。本研究使用其中1500—1900年间在英格兰出版、以英语写成的264443册作品,并采用HDL的“Extracted Features”数据集进行文本分析。该数据集基于“词袋模型”(Bag of Words),将文本视为词汇集合,忽略词序仅保留词频信息。通过分析不同词汇的出现频率,可以识别文本中的核心主题、情感倾向与关键概念。
2.2. 数据处理
首先对语料库进行筛选,剔除任何重复的卷册,并只保留1500年至1900年间仅以英语印刷的卷册。具体处理过程如下所示:

2.3. 通过LDA提取数据
本文采用潜在狄利克雷分配模型(LDA)结合词袋语料库生成主题集合,其中“主题”是指在同一文本中频繁共同出现的一组词根。LDA是一种无监督生成式统计模型,旨在从大量文档中提取潜在主题结构。该模型将文本视为“词袋”,仅关注词频而忽略词序。LDA假定每篇文档都是多个主题的混合,而每个主题则是不同词汇的概率分布。算法通过对观测文档反复抽样,推导出最优的主题分布,从而识别语料库中的潜在模式。由于LDA属于无监督学习,研究者无需预先设定标签或目标变量,因此模型能够自动发现文本中的共现词组及其隐含主题。在技术上,语料库最初被表示为“文档—词汇”矩阵(D×V),其中D为文档数量,V为词汇数量。经过LDA估计后,文本被重新表示为“文档—主题”矩阵(D×T),从而有效降低数据维度。
2.4. 模型选择
无监督机器学习面临的两个核心问题是模型质量评估与参数选择。由于文本数据缺乏标签,研究者难以直接判断LDA模型是否准确反映语料库结构,也无法事先确定最优参数设置。为此,本文采用机器学习中常用的“困惑度”(perplexity)指标衡量模型拟合优度。困惑度源于信息论,用于衡量模型对未观测数据的预测能力,即模型面对新样本时的“不确定性”。困惑度越低,说明模型越能准确预测文本中的词汇分布,因此模型表现越好。
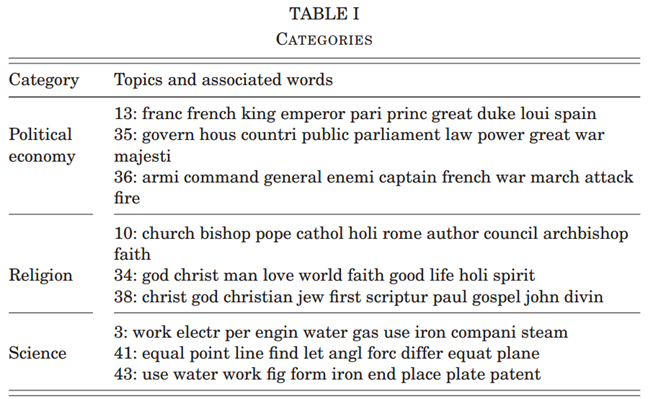
同时,本文结合交叉验证方法评估模型稳定性。具体而言,将数据划分为4折(K=4),每次使用75%的数据训练模型,其余25%用于测试,并轮换训练集与测试集,以减少样本划分带来的偏差。通过重复计算不同参数组合下的平均困惑度,最终选择使困惑度最小的参数设置。本文重点调整的参数包括主题数量T以及狄利克雷先验参数α和β。结果显示,最优主题数量为T=60(见附录A.2),其中部分主题具有明显的科学属性,例如主题60 {acid, water, solut, heat, carbon…} 主要涉及化学内容,主题52 {disea, case, patient, medic, blood…} 则与医学相关。
03
根据主题对文本进行分类
为实现更系统的分类,本文进一步考察不同主题在同一卷册中的共现频率,以识别在语料库中相对重要且彼此区分明显的主题类别,并据此根据共现关系对其他主题进行归类。
3.1.分类
首先,本文识别出语料库中每一卷册对应的60个主题分布。对于每篇文本,每个主题都对应一个反映其出现频率的权重,且所有主题权重之和为1。基于这些权重,本文进一步衡量不同主题在同一卷册中的共现程度。具体而言,在每篇文本中,将某一主题的权重与其他主题的权重相乘,从而得到对应的“主题对权重”,共得到1770个主题对权重。随后,本文统计所有卷册中出现频率最高的主题组合,并计算各主题对在整个语料库及不同时间阶段中的占比。令wiv表示特定主题对i∈{1,...,I}(其中 I = 1,770)在卷册v∈{1,...,V}中的权重,则有:
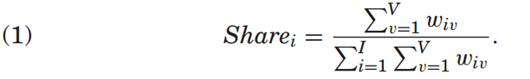
本文通过计算各类别的“出现频率”(Incidence)来衡量其重要性。具体而言,对构成某一类别的三个主题之间所有主题对的份额进行求和:
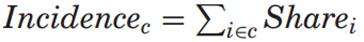
例如类别由主题1、2、3构成时,则对主题对(1,2)、(1,3)和(2,3)的份额加总,并据此对所有可能类别进行排序。随后选择那些既具有较高Incidence值、又具备明确分析意义且彼此主题不重叠的类别。在此基础上,Incidence最高的类别为{10,34,38},其内容均与宗教相关;其次是{3,41,43},主要涉及科学内容;第三类{13,35,36}则主要与政治经济学相关。据此构建三大主题类别:宗教、科学与政治经济学。
3.2主题的定位与演变
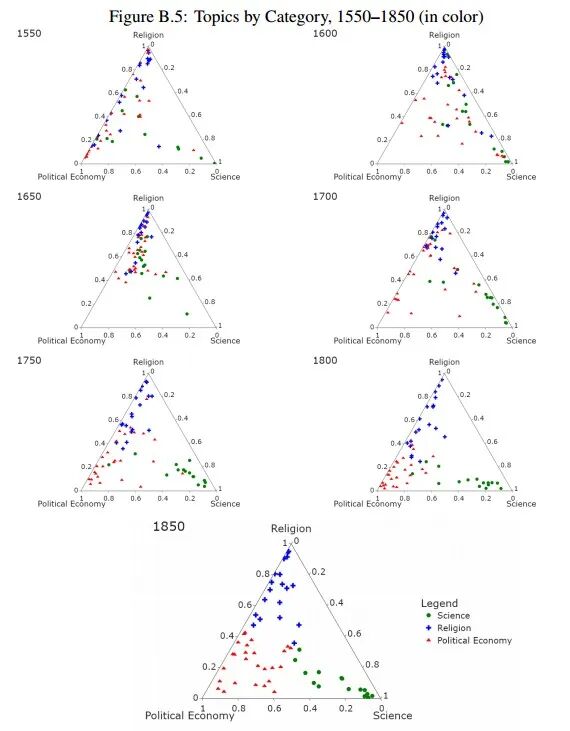
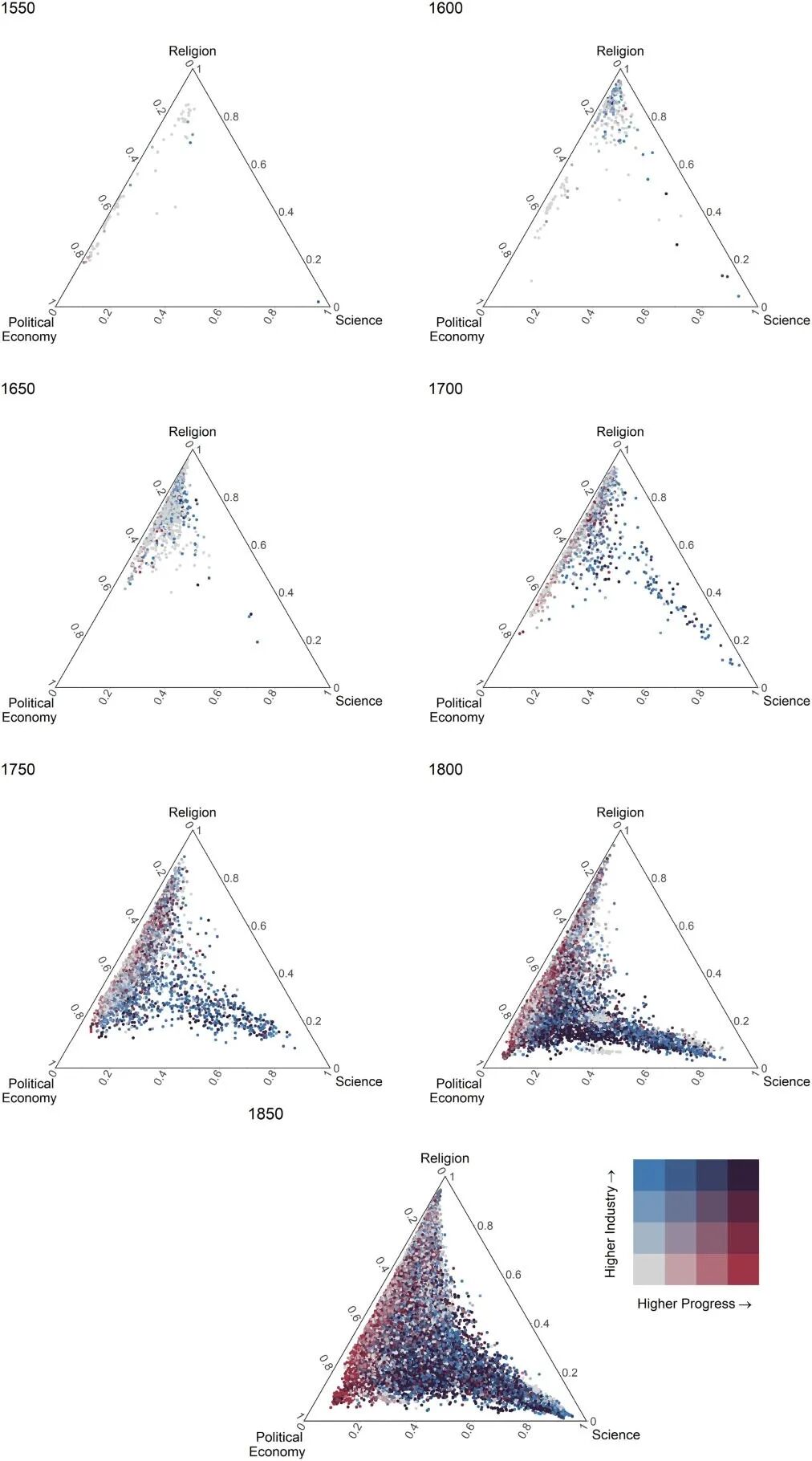
本文计算了各主题与不同类别的接近程度及其随时间的变化。对于任一主题与某一类别,将该主题与该类别内三个主题的主题对份额相加,由此每个主题在每一年均对应三个类别的得分,并可据此判断其与各类别的相对关联强度。将每一类别得分除以三类得分之和得到权重向量,并在三角形图中表示各主题的位置及其动态演化。
如图2所示:第一,语料库在早期较为稀疏;第二,自1700年后语料库显著扩展,主题分布更加分散并覆盖整个空间;第三,自18世纪中叶起,科学与宗教语言逐渐分化,二者共现的主题明显减少,并持续至样本期末。相比之下,科学—政治经济学与宗教—政治经济学的结合则呈现稳定增长趋势。这种科学与宗教语言的分离早于工业革命的发生,初步支持了Mokyr(2016)关于启蒙思想与工业革命之间关系的关键论断。
04
科学和工业语言中的进步思想
4.1情感分析
本文关注与“进步”相关的情感倾向,首先从网站 收集了“progress”的同义词,构建进步导向词汇列表。随后,对词表进行了多轮筛选,删除可能引入偏误、1643年之前在《牛津英语词典》中未记录的词等。最后,将剩余词汇还原为词根形式,最终形成进步导向词汇列表,并按照相关单词出现频率计算了文本的进步情感得分。

4.2科学语言随时间的变化
图6将每一卷册绘制在一个三角形图中,并同时展示每一卷册的情感得分。结果呈现出两个显著特征:第一,自18世纪中叶起,科学与宗教语言的共现显著减少,文本分布在“宗教—科学”轴线上几乎为空,大多数文本集中于“政治经济学—科学”或“宗教—政治经济学”轴线。第二,沿“政治经济学—科学”轴线分布的卷册随时间推移呈现出更强的进步导向特征,相比之下,沿“宗教—政治经济学”轴线的卷册进步倾向较弱,尤其是接近纯宗教的点。
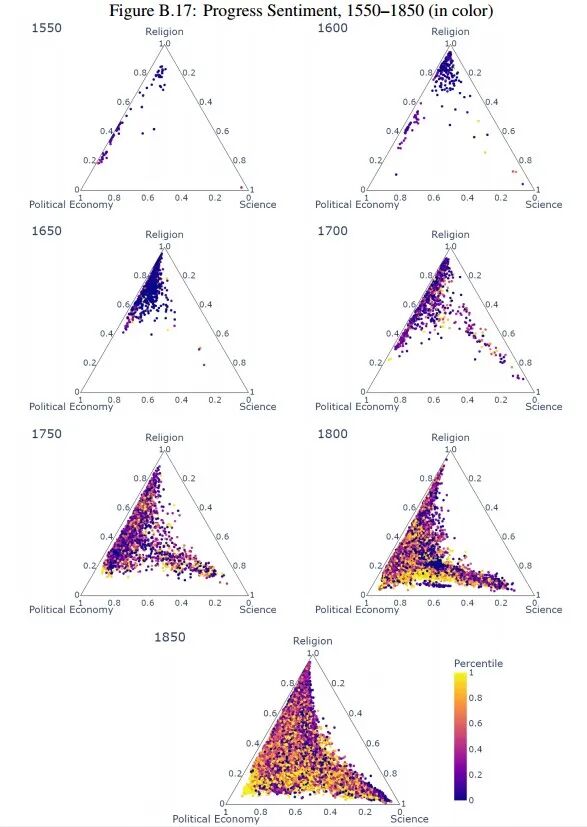
为更准确分析上述图像反映的结论,本节通过回归分析提供定量证据:
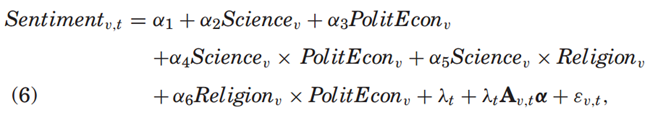
其中,Sentimentv,t代表在区间t出版的卷册v的进步导向情感得分,Science、Religion和PolitEcon代表该卷册的类别权重,λt是区间固定效应。Av,t是一个包含方程(6)中已包括的所有变量及其交互项的向量。
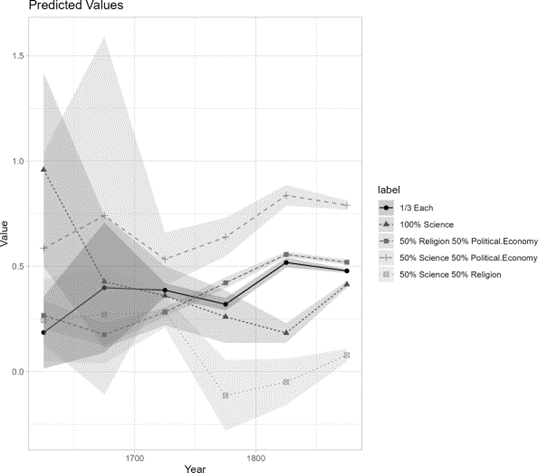
如图所示,从17世纪末开始,同时包含科学与政治经济学语言的卷册表现出最高水平的进步导向情感。同时,位于宗教—政治经济学交汇处、三类交汇处以及仅使用科学语言的卷册也呈现正向进步倾向,但整体水平低于科学—政治经济学交汇处的文本。
4.3.工业语言随时间的变化
Mokyr(2016)认为与工业生产相关的卷册应该更具有进步导向,这正是启蒙运动最终导致工业革命的原因。本文通过对使用工业语言文本进行分析,来检验这一假说。通过将《阿普尔比机械图解手册》第1—5卷的详细索引进行数字化处理,生成一个工业化词汇表,并为语料库中的每一卷册计算工业化得分。
结果如图所示:第一,使用工业术语的卷册大多数出现在科学-政治经济学轴线上。这一点大约从1750年开始尤为明显。第二,使用纯科学语言的卷册与工业化最为相关,而使用宗教-政治经济学交叉语言的卷册与工业化的关系最弱。
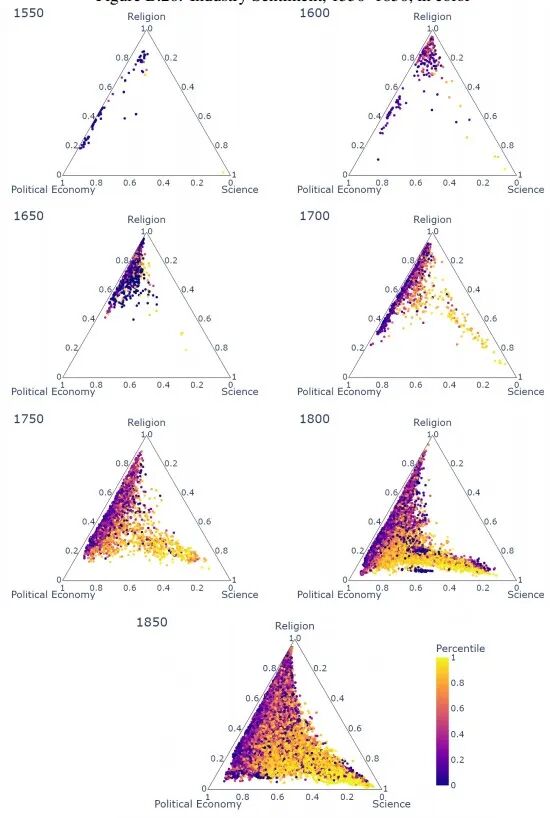
其次,将进步情感和工业情感绘制在同一张图中。可以明显看出,从18世纪中叶开始,特别是在19世纪初,使用科学-政治经济学交叉语言的卷册,在工业得分和进步导向得分上都较高。
05
结论
本文基于1500—1900年间英国出版的264443部文本数据,对Mokyr(2016)的“工业启蒙”假说进行了检验。主要发现有三点:第一,自18世纪中叶起,科学语言与宗教语言在文本中几乎不再重叠,表明启蒙运动使得科学语言世俗化。第二,启蒙时期使用科学语言的文本整体上更具进步导向,主要集中在科学与政治经济学交叉的语言中,而非纯科学语境。第三,兼具科学与政治经济学语言、并涉及工业化的文本表现出最强的进步导向特征。本文据此认为,真正承载并传播进步观念的,是那些更具实践性且面向更广泛受众的工业类文本。尤其是针对具有读写能力技术工人的书籍文本,在文化层面上为英国经济崛起提供了关键支撑。
推文作者:李俊洁,中国社会科学院大学数量经济学专业硕士生。
Abstract
We trace the evolution of the language of science, religion, and political economy in the centuries leading to the British Industrial Revolution. Using textual analysis of 264,443 works printed in England between 1500 and 1900, we test whether British culture manifested a belief in progress associated with science and industry. Our analysis yields three main findings. First, there was a separation in the languages of science and religion beginning in the mid-eighteenth century. Second, volumes using language at the nexus of science and political economy became more progress-oriented during the Enlightenment. Third, volumes using industrial language—especially those at the science-political economy nexus—were more progress-oriented beginning in the eighteenth century.
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}