
图片来源:LinkedIn
原文信息:Eisfeldt, A.L. & Schubert, G. (2024). AI and Finance. NBER Working Paper.
01
引言
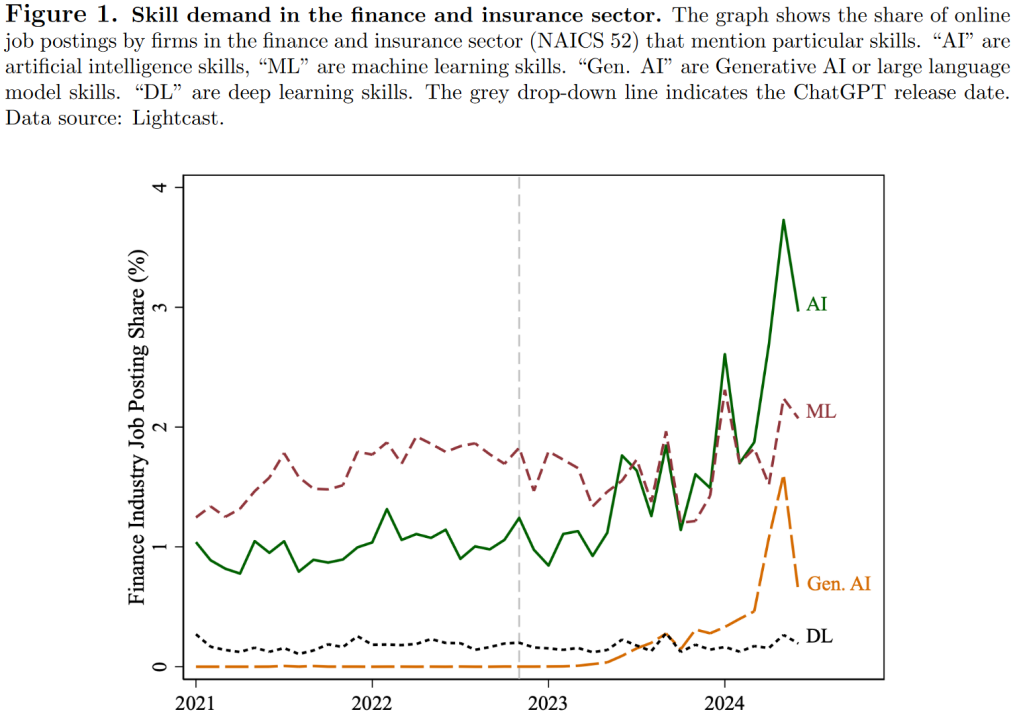
生成式人工智能(Generative AI)对企业和金融研究带来了重大技术冲击。在金融行业,生成式人工智能和大语言模型(LLMs)的最新进展引发了对相关技能的需求急剧增长。图1显示了金融和保险行业中提及特定技术技能的月度职位发布比例。在2022年11月ChatGPT发布后,“人工智能”技能需求在2024年中期已增至三倍,而专门涉及生成式AI或LLMs的技能需求从零上升至大约1%的职位发布。
本文将生成式人工智能作为金融经济学研究主题和金融研究方法工具,聚焦于大语言模型和相关深度学习技术,而非更广泛的人工智能工具,如机器学习、神经网络、机器视觉和机器人等,这些工具早在2010年代便已应用于研究和实践。本文讨论这些工具对公司价值、决策和金融研究的影响。
本文的目标包括描述和推进金融研究前沿,并提供生成式AI如何提升资产管理和公司财务决策的实用建议。关于金融企业内生成式AI的新兴应用案例,可参考Aldasoro等(2024)的研究。
具体而言,本文讨论两大主题:(1)生成式AI作为影响公司价值和企业政策的技术冲击;(2)生成式AI作为金融研究方法的技术冲击。针对(1),本文不仅回顾现有文献,还指出未来研究的潜在方向;针对(2),本文为研究者提供将生成式AI纳入研究工具箱的实用指南,并讨论最佳实践。
02
生成式人工智能:技术对企业的冲击
2022年11月ChatGPT的发布代表了一个对各行业企业产生重大影响的技术冲击。总体来看,其对企业价值的影响显著且正面,但不同企业的估值变化存在较大差异。这种技术冲击不仅通过投资者对企业未来自由现金流增长前景的预期影响企业价值,同时我们也预期生成式AI将推动企业政策的未来调整。企业价值的变化既与其对技术冲击的不同程度的暴露相关,也与企业在快速发展的AI技术前沿背景下所作出的决策变化相关。现有研究仅初步揭示了生成式AI对生产流程的转变、生产率的提升及创新不确定性对企业行为的影响。
尽管生成式AI技术冲击相对较新,但已有大量研究关注其对劳动力、企业招聘决策、工资水平以及最终企业价值的影响。在此部分,本文首先回顾Eisfeldt等(2023)的研究成果,该研究对生成式AI的显著影响进行了测量。接下来,本文探讨未来研究的有益方向,包括生成式AI创新对资本结构和资本投资等其他企业政策的潜在影响。
2.1 测度生成式人工智能暴露
要确定哪些公司受到技术冲击的影响,可以通过调查、专利数据或产品信息来评估技术使用情况,从而推断出生产率潜力。然而,对于像生成式AI这样快速进步的技术,目前的生产率潜力和当前采用水平之间往往存在较大差距。因此,研究人员常用公司当前特征作为衡量技术潜力的替代指标。
Eisfeldt等(2023)提出了另一种衡量方法,结合Eloundou等(2023)对不同职业任务暴露于LLM能力的分析,将公司在生成式AI方面的暴露度与公司在LinkedIn上的就业结构结合,评估生成式AI对公司的影响。该方法使用O*NET数据库中的任务内容,并借助LLM分类算法将任务分为三种暴露等级:(1)直接暴露:LLM直接使任务完成时间减少≥50%;(2)间接暴露:结合其他工具,LLM可减少任务时间≥50%;(3)无暴露:LLM无法显著缩短任务时间。结果显示,14%的职业任务直接暴露,22%在结合工具后暴露,64%不受暴露影响。
例如,“贷款专员”的一些任务如计算支付计划、填写表单、写商业邮件可直接通过LLM完成,但需要内部数据库访问的任务或需要决策权限的任务则无法依赖LLM完成。这表明生成式AI暴露在职业任务间存在差异,一些任务可因AI而更易完成,而另一些则不受影响。
Eisfeldt等(2023)认为,由于不同任务对工作职责的影响不同,技术暴露对员工的影响因任务而异:若员工的核心任务部分或完全可自动化,公司可能重组或裁减相关岗位,而若仅是“补充”任务被自动化,员工可能因节省时间而在公司中更具价值。此外,其他研究者还开发了衡量前期AI创新浪潮对企业暴露的指标,如Babina等(2024)基于AI相关技能的识别和公司招聘信息评估了2007-2018年企业的AI投资水平。
2.2 不同职业的生成式人工智能暴露
对于研究生成式AI影响的金融研究人员来说,了解不同职业间的技术暴露差异,尤其是金融相关岗位的暴露情况至关重要。
图2展示了一些描述性内容:Panel A显示所有职业的平均生成式AI暴露度为0.27(基于2022年就业数据加权),医疗职业较低(0.18),而金融职业几乎是平均水平的两倍。此外,计算机相关职业因LLM的编程能力而具有最高暴露度(0.62),管理岗位也高于平均,但低于金融和计算机职业。计算机职业的暴露多源于核心任务,而管理者更多涉及辅助任务。
金融职业的高暴露度符合高薪职业更易受生成式AI影响的规律。2022年,金融职业年均工资为108K美元(美国平均为62K美元)。Panel B表明,金融岗位的总体暴露差异较小,但核心任务的暴露差异更显著:金融经理、贷款专员和财务顾问的核心任务受影响较少,而会计师和保险承保人受影响较大。这是因为需要人际交往能力的岗位较少依赖LLM的分析能力。
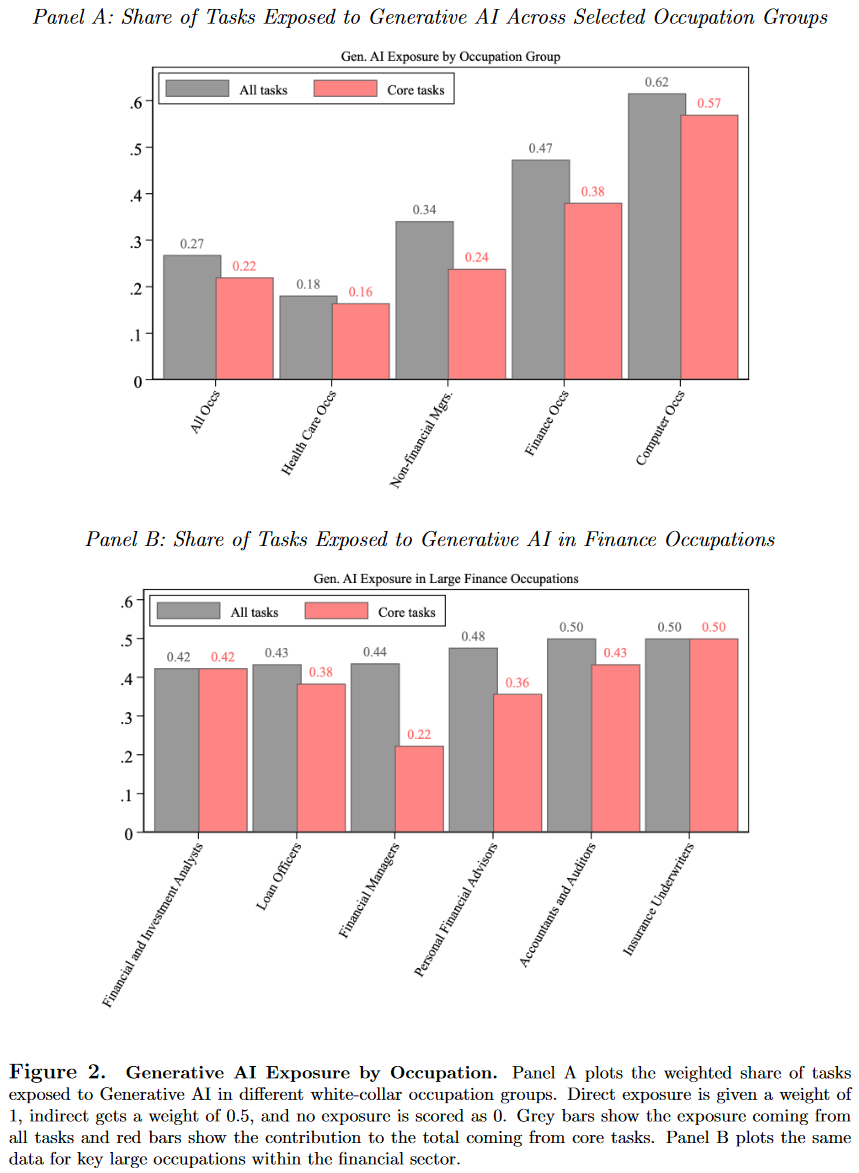
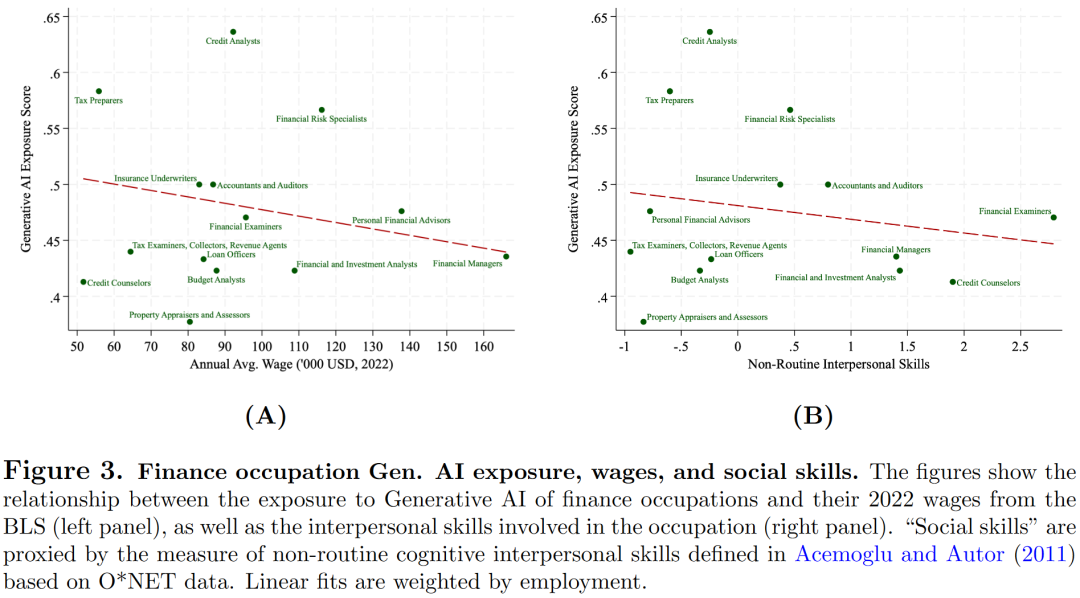
图3揭示了暴露度与职业工资及人际技能需求的关系。Panel A显示高薪金融职业的暴露度较低,这与整体经济中工资与暴露度呈正相关的关系相反,可能是由于金融职业本身对分析技能要求较高。Panel B显示暴露度越高,人际技能需求越低。
2.3 生成式人工智能对企业的影响
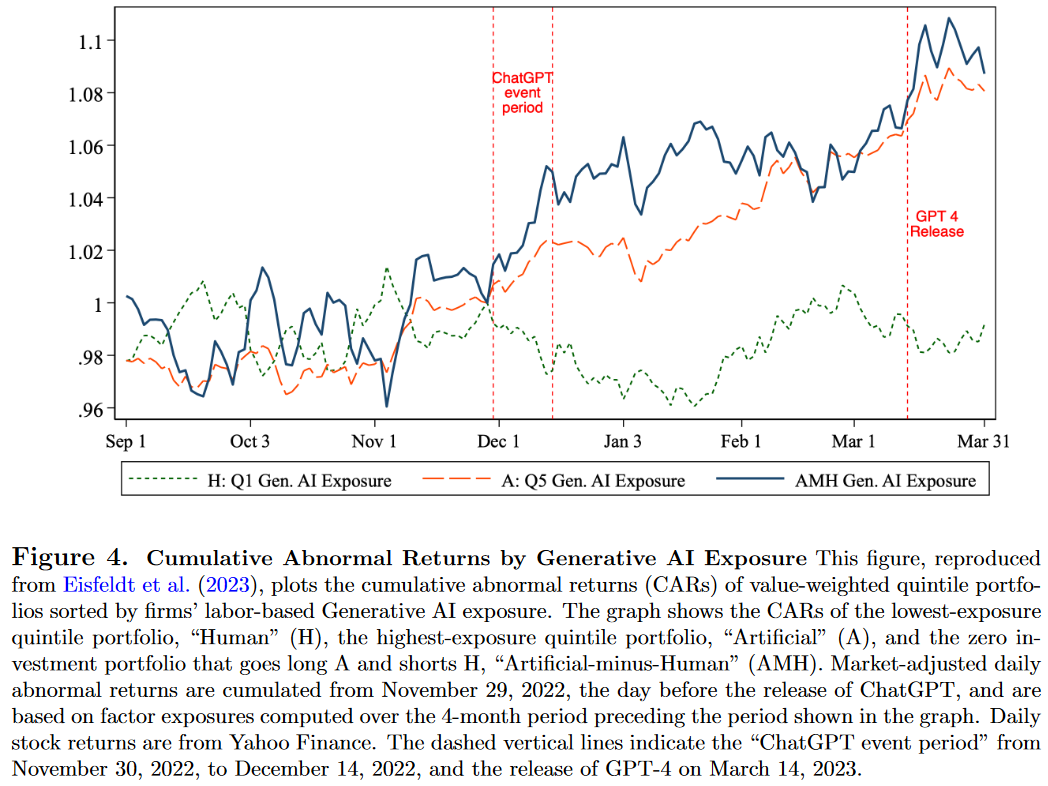
自2022年11月生成式AI技术发布以来,金融市场对这一技术冲击的反应提供了一个自然实验。研究重点是金融市场预期新技术的生产力潜力以及哪些公司最可能受益。Eisfeldt等人(2023)研究了ChatGPT发布这一事件,发现暴露于生成式AI的公司(“Artificial”组合)在发布后两周内,相比于低暴露公司(“Human”组合),每天获得高出44个基点的超额回报。图4展示了“Artificial Minus Human”组合(AMH)的累计异常回报。
为了估算技术带来的劳动价值,本文粗略计算了基于GPT 4的生产力提升,结果如图5显示,所有职业的年创造价值约为1.4万亿美元,其中金融行业约为910亿美元。与此相比,2022年11月29日“Artificial”组合公司总市值为10.2万亿美元,可能部分解释了其相对价值增加4-5个百分点。
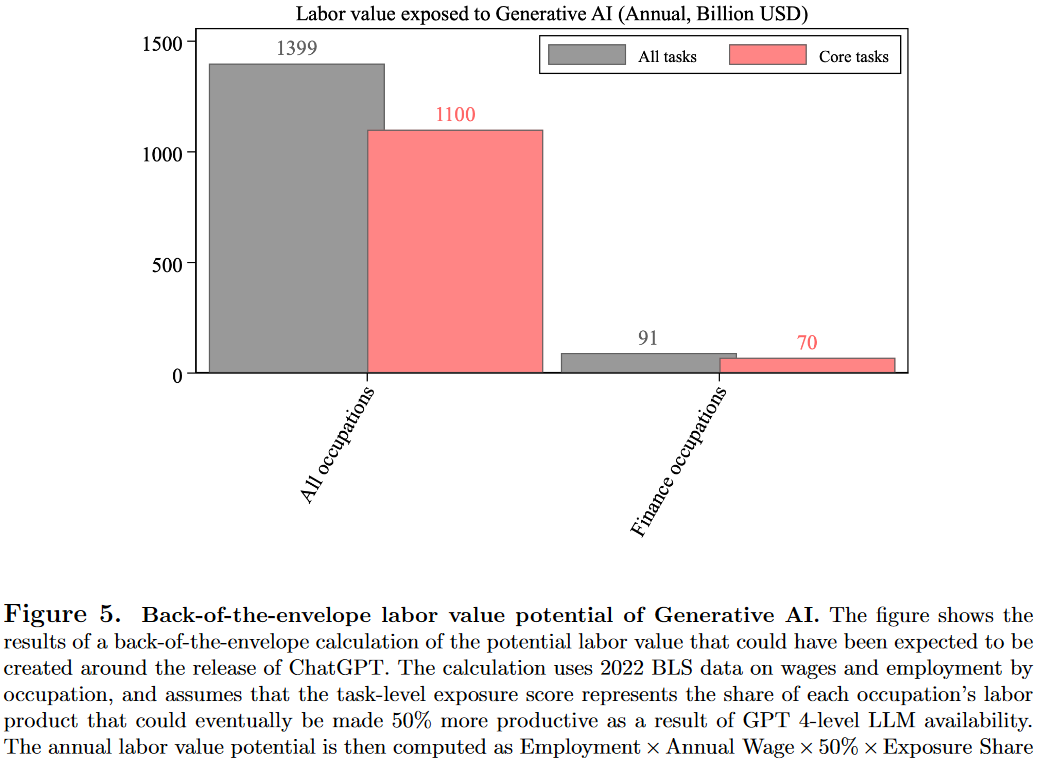
此外,后续技术更新,如2023年3月GPT 4发布,也显著影响了AMH组合的回报,展示了生成式AI对公司估值的持续影响。
2.4 未来研究方向
生成式AI对劳动市场、公司投资及融资的影响是未来研究的关键方向。研究可以探讨生成式AI如何改变职业等级结构、工资差距和职业任务,以及其如何影响公司投资决策和资本结构。此外,生成式AI的普及可能增加能源需求,影响能源生产和气候变化投资。资产定价方面,技术冲击会改变市场风险构成,特别是AI人才的招聘与公司系统性风险之间的关系。
03
生成式人工智能:技术对研究的冲击
生成式人工智能、大语言模型(LLM)和深度学习方法广泛应用于金融与经济学研究,不仅大幅降低时间和成本,还支持新的分析方法。生成式AI技术首先提升了研究效率(Korinek, 2023):利用LLM生成和调试代码、快速分类文本数据、辅助撰写与校对等,都能显著加快研究进程并减少成本(如Dell(2024)关于历史文档构建经济指标的建议)。此外,生成式AI还能生成研究新思路、模拟调查参与者、实现大规模定性数据分析,为学术研究带来革新。
这些工具更有助于“辅助”任务的自动化,腾出时间供研究者专注核心工作,如设计、教学与指导(Eisfeldt等,2023)。然而,这些工具的便利也带来风险:其应用虽降低了门槛,但对结果的控制力减少,准确性仍需严谨验证,不能简单粗暴地把这些功能强大的新模型当作“黑箱”工具,其仍需研究者仔细监督。
在此类方法的论文撰写和审阅中,本文强调关注准确性和方法选择的重要性,鼓励通过研究和发表积累“标准”方法和测试工具,如计量方法中的诊断工具,以增强结果可信度。后续章节将探讨生成式AI在金融研究中的具体应用及教学中的潜在用法(详见表2),并附相关建议。
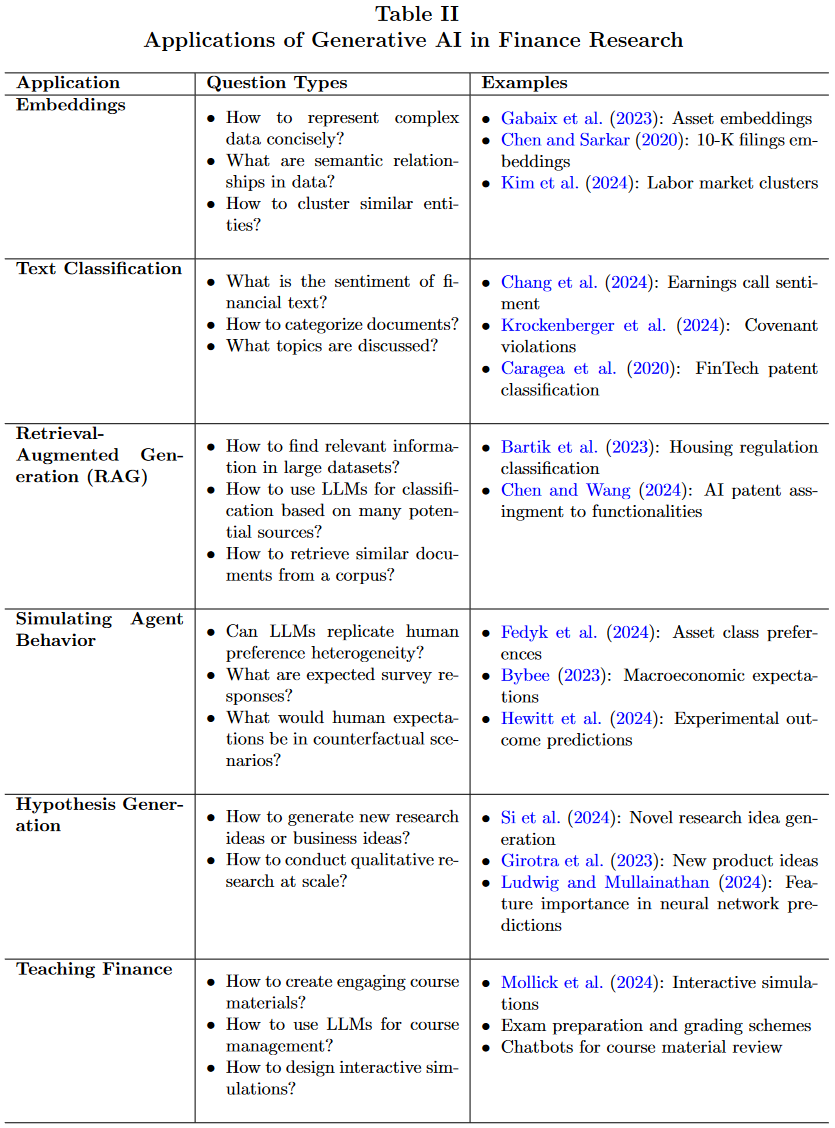
3.1 嵌入(Embedding)
在金融与经济学研究中,处理高维数据是常见需求。例如,通过分析美国公司财报电话会议的文本信息,以预测股票回报率。由于文本句子组合方式无限,直接追踪所有可能短语会导致过多变量。因此,我们可以通过“嵌入”技术,使用编码器模型,将文本信息转化为低维数值表示,提取出关键信息或“本质”。
嵌入是将不同数据类型(如文本、投资组合或市场事件)转化为向量数值的方式,以捕捉语义或特征。其原理是将离散数据映射到连续的低维空间,以便分析非数值数据及其相互关系。以新闻标题的通胀分析为例:嵌入能让相似语义的标题在向量空间上更接近,而非简单依赖词表。现代嵌入生成通常基于“transformer”模型,该神经网络结构利用词上下文,捕捉复杂的文本依赖关系。比如,transformer可分辨“公司因未投资而受损”与“公司盈利增长”之间的语义差异。
在金融研究中,嵌入技术已被用于简化高维数据,如财报电话会议内容,可作为传统机器学习模型(如违约预测和情感分析)的输入。此外,嵌入还可创建“语义轴”用于表征概念差异,例如“风险”与“安全”轴。此技术被Fedyk等人(2024)用于调查回应,分析投资者对资产类别的偏好。
除了文本外,嵌入还能用于其他数据,如Gabaix等(2023)提出的“资产嵌入(asset embeddings)”模型,通过投资者投资组合的上下文预测某资产,并根据相似性在语义空间中聚类资产,进而帮助研究投资者行为及股票市场的联动性。
3.2 文本分类
当前金融研究中一个重要的领域是分析关于公司的文本数据(如财报电话会议、年报、SEC备案、新闻发布、新闻标题等)。在大量文献中,研究者利用这些文本数据来分类公司。例如,研究者可能希望识别某项新法规对公司的影响,进而标记那些在财报电话会议中提到该法规的公司,并分析其提及情感(正面或负面)。
在生成式AI大规模数据分析兴起之前,研究者通常通过预定义的关键词列表进行文本分析。这些关键词被分配“正面”或“负面”权值,再将它们组合成整体情感得分。然而,这种方法在处理复杂文本时可能不够准确,因为词语的含义会因上下文而变化。举例来说,区分“摆脱盈利低谷”与“进入盈利低谷”仅靠词汇的权值并不可靠,这凸显了考虑上下文的文本分析方法的必要性。
基于Transformer的模型能够捕捉语言中的细微差别,尤其是BERT模型在金融研究中影响较大。BERT作为一种编码器,能够将文本转化为低维向量,生成包含语义内容的嵌入。研究者可直接使用预训练的BERT模型将文本片段转化为语义嵌入,这一能力使BERT成为金融研究中分析文本数据的有力工具。此外,BERT模型可以通过微调来进行特定领域的文本分类,使其更准确地反映金融文本的语境和术语,提高分类性能。例如,FinBERT专门针对金融新闻进行优化,通过微调捕捉金融领域的专用语言。
通过在BERT模型上添加额外的分类层,研究者可以直接生成分类标签而非通用嵌入,使这些模型在处理大量非结构化文本数据时更为高效。在专利数据分析中,BERT也得到了成功应用,例如Caragea等人利用BERT对专利摘要进行分类,以识别与金融科技相关的创新发明。类似地,Chen和Wang(2024)将Transformer模型用于专利嵌入,从而对特定技术进行大规模分类。
除了BERT,一些研究还开发了类似模型用于分析财务新闻、监管备案、分析师报告和电话会议记录。例如,Krockenberger等(2024)利用MPNet模型分析10-K和10-Q报告中的契约违约情况。Chen和Sarkar(2020)使用BERT模型处理10-K文件,将公司文本嵌入均值作为特征进行公司聚类,并展示了基于文本信息的聚类在反映公司“软性”特征方面比传统行业定义更为有效。此外,Bonne等(2022)利用Doc2Vec模型结合10-K文本和公司特征数据以创建更符合风险和收益的行业分组。
随着最新一代大语言模型(如ChatGPT)在2022年发布,研究者能够利用其生成文本的能力直接从文本中提取分类标签。这使得研究者无需额外训练模型来进行分类,为金融领域的大规模文本分析提供了便捷的途径。例如,Chang等(2024)使用GPT-3.5-turbo16k模型分析数十万条财报电话会议,并生成情感分数以预测股票回报。此外,Lopez-Lira和Tang(2023)的研究表明,GPT-3.5及更高版本可以预测新闻标题后的股票回报。这些应用显示了高级LLM在金融文本分析中的潜力,未来可能在分析企业新闻稿、新闻文章、专利文本、政策发言等方面进一步得到应用。
3.2.1 检索增强生成(Retrieval-augmented Generation,RAG)
在许多应用中,将所有相关文件提供给大型语言模型(LLM)可能因计算量过大或技术难度而不可行。例如,当要求LLM评估公司产品受不同监管文件的影响时,文件可能长达数千页,因此必须先识别最相关的部分,并仅将部分文本输入LLM。一个常用的方法是“检索增强生成”(RAG)。RAG结合了LLM的文本响应能力与从数据库中检索相关信息的优势,通过在提示中加入检索到的信息,提供查询的背景。例如,研究人员希望在公司财报电话中提取关于环境问题的个别提及内容,可利用RAG从大量历史数据中检索相关信息,以实现更有针对性和上下文支持的分析。
RAG的工作流程如下:
1. 数据库创建:首先建立可能提供上下文的文本数据库。
2. 文本分块:将输入文本拆分成较小的部分(分块)。
3. 嵌入:将文本分块转换为语义向量,以便高效检索。
4. 查询处理:将用户问题也转化为嵌入。
5. 检索:利用查询嵌入查找最相关的文本分块。
6. 筛选/重排序:对检索到的分块进行筛选或重排序,确保分析时只包含最相关的内容。
在最终步骤中,通过筛选排除低相关性分块,并重排序以确定最优的分块顺序。选择后的分块与提示一起输入LLM,使其基于相关内容生成更为精确的回答。
具体而言,若研究公司在财报电话中对环境问题的讨论,可先将电话记录分块并嵌入向量数据库。然后,研究人员可能按特定公司和年份筛选,并检索语义上与环境问题类似的分块。初步筛选可能保留明确提及“环境”的部分,随后利用LLM判断这些片段是否涉及本公司的环境问题。筛选后的内容会与评分标准一并提交给LLM,请求其为环境关注度打分。最终,研究人员可构建数据集,标记各公司在哪些年份表达了环境关注。
最近,RAG在不动产领域得到了应用。Bartik等(2023)使用该方法对全国性分区法规数据库中的市政住房法规进行分类,并通过LLM分析文本,以确定适用于不同区域的分区规定。研究表明,RAG在二分类任务中精确度高,特别适合从大型文本语料库中提取具体信息生成分类或总结。然而,当需要整体分析长文本时,如统计公司财报电话中最常提及的问题,RAG无法有效提供答案。
3.3 经济主体行为和预期的模拟
大型语言模型(LLM)在研究中的潜在应用包括作为廉价、随时可用的“模拟”调查受访者,用于初步调查测试、产品或用户体验测试等,尤其是在无法获得真人受访者时。研究表明,GPT-4在预测实验结果方面可超越人类专家,其生成的模拟响应能够用于估计处理效果,但需要下调其绝对效应量。LLM的这一优势可用于改进研究设计、开展模拟试验或生成贝叶斯分析中的先验分布。
此外,LLM还可生成符合人群特征的个性化理财建议,或在数据收集中充当面试官角色。使用LLM代替真人的价值在于其响应的精准性、方法的复现性及其成本优势。实例包括LLM在宏观经济预期和股市收益预期中的应用,能准确反映实际调查中的预期,并模拟人类行为偏差。此外,LLM在资产选择偏好中也可表现出与人类相似的偏好,但比人类更具传递性。
LLM还能生成“倾向分数”控制变量,用于匹配和加权处理组和对照组的个体,从而作为一种合成对照组。此外,LLM可用于构建具异质性特征的代理模型,以生成现实的叙事示例或用于模拟中。LLM预测还可作为时间序列预测的基准,帮助研究者区分预期内和意外变化。例如,在货币政策研究中,LLM预测可用于衡量“政策意外”,并评估政策声明是否符合外界预期的逻辑与情绪。这种能力有助于分析政策导向的变化。
3.4 假设生成
学术研究中的重要环节是新研究想法的生成,而这些想法往往源于对现有知识的互动和人类反馈。LLMs因其全天候可用和广泛的知识储备,可成为早期阶段讨论的有益伙伴,不仅能帮助评估人类提出的想法,还能自主生成新点子。研究表明,GPT-4在生成产品创意上可优于MBA学生,且LLMs系统可产生比专家更具创新性的研究想法,但LLMs无法可靠地评估想法质量,因此人类仍在构思过程中扮演关键角色。人类与算法的“混合”团队也展现出潜力,例如通过深度学习模型分析嫌犯照片特征,并通过人类的反馈生成可解释的预测特征。在经济学和金融学中,LLMs还可用于扩展定性数据收集和访谈,以助力理论验证和假设生成。同时,LLMs作为不断互动的讨论伙伴,赋予研究者“人机融合”的角色。
3.5 使用生成式AI进行金融教学
生成式AI通过提升教学效率,显著提高学术研究者的生产力。例如,在MBA课程中,AI可以将零散笔记转化为可用于幻灯片的Tex或Markdown格式脚本,节省备课时间。先进的LLM(如OpenAI的o1-preview模型)能够检查推导过程中的错误,并快速生成和测试用于巩固概念的练习题。LLM生成的对话还可用于模拟课堂讨论,并提供互动教学支持。此外,AI可自动运行代码生成图表,展示课堂推导的方程;结合课程记录,创建能解答相关问题的聊天机器人,为学生备考提供帮助。在金融等学科中,教师还可通过LLM进行模拟考试,识别学生可能的误解,优化考题,并以AI生成的答案为基础设计评分标准。Mollick等(2024)指出,LLM还可帮助设计互动模拟,提升商业案例教学的参与度。此外,学生设计自己的LLM聊天机器人,可提高对AI在职场应用的理解和设计AI提示的能力。
04
结论
生成式AI代表了金融研究和实践中的一次重大技术冲击。Eisfeldt等(2023)展示了ChatGPT发布对公司价值产生的迅速且巨大影响,表明未来关于生成式AI对公司政策影响的研究将会富有成果。越来越多的创新性研究利用生成式AI工具研究公司财务和资产定价中的经典问题。与20世纪末金融市场数据的广泛可用性以及21世纪初计算能力的进步等先前的技术创新一样,我们预计生成式AI将在金融研究中产生深远的影响。除了回顾现有的创新研究外,我们希望本综述能够为未来成功的研究提供有价值的工具和指导。
Abstract
We provide evidence that the development and adoption of Generative AI is driving a significant technological shift for firms and for financial research. We review the literature on the impact of ChatGPT on firm value and provide directions for future research investigating the impact of this major technology shock. Finally, we review and describe innovations in research methods linked to improvements in AI tools, along with their applications. We offer a practical introduction to available tools and advice for researchers interested in using these tools.
推文作者:
孙乐轩,中山大学岭南学院金融学博士生
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}