原文信息:
Korinek, A. (2023). Generative AI for economic research: Use cases and implications for economists. Journal of Economic Literature, 61(4), 1281-1317.
随着生成式人工智能(Generative AI)技术的快速发展,特别是大语言模型(Large Language Models,LLMs)的崛起,经济学研究正在经历一场前所未有的变革。ChatGPT等AI工具不仅加速了研究过程,还极大地提升了学者在创意生成、数据分析等方面的效率。
本期推送一篇发表在Journal of Economic Literature期刊上的前沿研究Generative AI for economic research: Use cases and implications for economists,该文详细探讨了如何利用这些先进的AI工具提高研究效率。
作者将LLMs的应用分为六大领域:创意生成与反馈、写作、背景研究、数据分析、编码及数学推导。在每个领域,生成式AI都展现出显著的优势,从加速头脑风暴、精炼论文写作,到简化数据处理、编写代码。通过这些工具,研究人员可以自动化处理日常的微小任务,大幅提升生产力。
更重要的是,随着AI技术的不断进步,其对研究人员的帮助将愈加显著。本推送将深入探讨生成式AI如何在经济学研究中发挥关键作用,并揭示这一前沿技术如何引领未来的研究趋势。对于经济学家和研究人员来说,掌握这些新工具,意味着能够在信息化时代的竞争中占据更大优势。
表1 主流大语言模型规格与应用概览
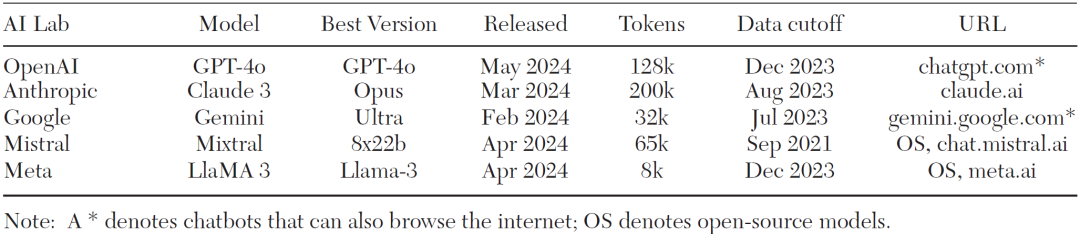
截至2024年5月15日,最新LLMs在处理能力和应用场景上取得了显著进展。表1数据显示,OpenAI的GPT-4o、Anthropic的Claude 3 Opus和Google DeepMind的Gemini Pro 1.5等前沿模型,不仅扩展了上下文窗口,还通过不断优化性能提升了经济学研究的效率。这些模型能够在大规模数据分析、创意生成、写作和数学推导等领域提供强大支持,极大缩短了研究时间。随着LLMs技术的升级,研究人员能够处理更加复杂的任务,从而进一步提高生产力,推动经济学研究的创新与发展。
01
LLM的技术革新与生成式AI的驱动因素
生成式人工智能依赖大语言模型来进行自然语言处理任务,推动了经济学研究领域的变革。随着技术的飞速发展,LLMs在处理复杂文本、数据分析以及写作生成等方面表现出色,具备极大的应用潜力。本节将基于最新的研究成果,深入探讨LLMs的训练、规模与突现能力、提示词设计以及它们的局限性,帮助读者全面理解这些模型的技术内核及其在学术研究中的应用前景。
训练过程:LLMs的训练是基于大规模文本数据集的无监督学习过程,模型通过捕捉语言中的模式和规律来生成准确的文本输出。例如,像GPT-4这样的模型被训练处理数十亿的词汇,这使其在理解和生成复杂的句法结构时具有出色的表现。这种训练架构的基础是变革性的Transformer模型,它能够处理长距离依赖,从而生成高质量的、连贯的文本(Vaswani et al.,2017)。通过这种方式,模型不仅掌握了语言的基本结构,还能应用于跨学科任务,显著加速了经济学研究的效率。
规模与涌现能力:随着模型规模的不断扩展,LLMs展现了新的涌现能力。表1展示了如GPT-4和Gemini Pro等最新模型拥有超大上下文窗口(最大可达1百万tokens),使其能够处理更为庞大的文本数据,并在经济学研究中应用复杂的推理任务。研究表明,当模型参数达到一定规模时,许多原本无法预测的功能会突然显现,例如复杂任务中的推理能力增强(Hagos et al.,2024)。这种突现能力让LLMs在多个学科中,包括经济学的数据分析和文献综述方面,展现出独特的优势。
提示词设计:LLMs的输出质量在很大程度上取决于提示词(prompt)的设计。提示词作为用户与模型之间的桥梁,能够引导模型生成与任务高度相关的文本。研究者发现,通过精心设计的提示词,LLMs可以在创意生成、论文写作和经济模型构建中表现出更好的灵活性和精准性。特别是在经济学研究中,有效的提示词不仅可以加速研究进程,还能够帮助学者获得更具创新性的洞见。然而,提示词设计是一项需要不断优化的工作,需要根据不同任务进行调整,以确保输出结果的高质量和相关性。
局限性与挑战:尽管LLMs在许多领域表现卓越,但它们仍存在一些重要的局限性。首先,这些模型依赖于历史数据进行训练,因此无法获取实时更新的信息。像GPT-4的训练数据截止于2023年12月,无法应对之后的最新事件和数据。此外,LLMs在处理复杂的推理任务时,仍然存在“幻觉”(hallucination)问题,模型可能会生成看似合理但实则错误的内容。同时,数据隐私和伦理问题也是LLMs应用于学术研究中亟待解决的挑战,研究人员需要格外谨慎,确保数据安全并对模型的输出进行严谨审查。
主要LLMs概述
02
随着生成式AI的普及,几大科技公司开发的语言模型成为了推动经济学研究变革的关键工具。该文介绍了最常用的几款大语言模型及其在经济研究中的应用场景。
(1)OpenAI的ChatGPT
ChatGPT是由OpenAI开发的,基于GPT架构的生成式语言模型。其最新的GPT-4o版本拥有超过18000亿参数,能够生成连贯且具有上下文相关性的文本。这款模型擅长处理各类任务,从创意生成、数据分析到文献综述。在经济学研究中,ChatGPT能有效帮助学者撰写初稿、处理大规模数据并生成研究假设,特别是在文本密集型任务中表现出色。
(2)微软的New Bing
Bing Chat是微软推出的基于GPT-4技术的搜索引擎聊天助手,与ChatGPT不同,它能够实时访问互联网,这使其在经济学研究中的应用更为广泛。Bing Chat不仅可以回答复杂问题,还能检索和验证实时数据,适用于需要引用最新信息的研究场景。此外,Bing Chat集成在Microsoft Edge中,用户可以利用其对比产品、生成文本,并将其用于学术研究的数据搜索和分析。
(3)谷歌的Bard
Bard由谷歌开发,最初基于LaMDA模型,目前已更新为PaLM 2,这一技术显著增强了Bard的语言生成能力。Bard的最大优势在于它能够通过谷歌搜索实时获取数据,并为用户生成准确、及时的研究资。尽管Bard在一些复杂问题上仍有改进空间,但其与谷歌生态系统的无缝集成使其成为经济学研究中获取最新信息的重要工具。
(4)Anthropic的Claude 3.5 Sonnet
Claude 3.5 Sonnet是由Anthropic开发的生成式语言模型,专注于提高模型的伦理性和安全性。Claude 3.5 Sonnet在处理复杂数学推理和文本生成任务中表现出色,同时具备较强的文本分析能力。在经济学研究中,Claude 3.5 Sonnet可用于高效生成复杂分析报告和处理大规模文本数据,特别是在推理和总结领域显示出优势。
(5)Meta的LLaMA 3
Meta的LLaMA 3模型以其轻量化和高效性著称,适合资源有限的研究环境。与其他模型相比,LLaMA 3能够在保持良好生成效果的同时大幅降低计算资源的需求。这款模型特别适合中小型经济研究项目,能够用于数据处理、文献分析和生成研究报告。
(6)插件支持
一些生成式AI平台,如ChatGPT和Bing Chat,通过插件扩展了其功能。研究人员可以借助这些插件,将模型与数据库、代码库等外部工具集成,从而提高研究效率。例如,ChatGPT的插件能够与代码编写平台相结合,使其在生成代码、处理数据时表现更为出色。
(7)视觉-语言模型
视觉-语言模型(Vision-Language Models,VLMs)是结合图像和文本理解的生成式AI模型,能够处理视觉数据和语言任务的跨模态融合。这些模型在经济学研究中的应用范围广泛,尤其是在处理图表分析和地理数据时,VLMs可以通过将视觉输入与文本生成相结合,提供全新的数据洞察。
(8)可重复性
LLMs在研究中的可重复性问题备受关注。由于大语言模型的训练数据和算法的复杂性,不同模型可能对同一任务给出不同的结果。因此,如何确保模型生成的内容可重复且具有一致性,是研究人员在使用这些工具时需要注意的一个关键挑战。
通过上述模型的应用概述,可以看出LLMs技术为经济学研究提供了新的工具与方法,但在选择使用哪种模型时,研究人员仍需根据具体的研究需求和模型特点做出权衡。
03
大语言模型在经济学研究中的应用
3.1创意与反馈
头脑风暴:LLMs能够快速生成大量创意,并为研究者提供不同的研究视角。通过输入研究主题,AI可以提出多种假设、研究问题以及潜在的研究框架。例如,在经济学领域,使用ChatGPT 4o或Claude 3.5 Sonnet等工具,研究者能够通过自动化的头脑风暴环节生成新的经济模型假设或理论框架,这些想法往往可以作为研究初期的参考。通过向AI提出开放性问题,例如“什么因素可能影响某国的货币政策?”生成式AI会列出多种潜在因素,例如通货膨胀率、国际贸易动态、以及国内生产总值变化等,帮助研究者快速获取新的思路。这种方式特别适合经济学研究的初期阶段,能够激发研究人员从不同角度考虑问题。
反馈:LLMs不仅能生成创意,还可以对研究者的内容提供反馈。输入一段自己撰写的理论分析部分,AI能够识别文本中的逻辑漏洞或表达不清的部分,并提出修改建议。例如,如果一段关于市场均衡的分析存在模糊的逻辑链,AI可以指出具体需要澄清的地方,并建议如何补充数据或引用文献支持论点。通过模型的自然语言处理能力,AI能够分析文章的逻辑结构、数据分析结果,并给出建设性的修改建议。这种反馈机制能够帮助研究者更快地优化研究内容,提升整体学术水平。
提出反驳:LLMs在提供正面反馈的同时,提出反驳意见。举例来说,如果研究者提出某一经济政策对就业市场有正面影响,AI可以生成反对意见,指出该政策可能导致的通货膨胀风险或长期投资减少等负面影响。通过这样的反驳生成,研究者可以更好地完善其论证结构,考虑到不同的反应路径和外部影响。
3.2写作
综合文本:将多个来源的文献或研究资料进行整合,帮助研究者生成连贯的文本。这一功能对于撰写文献综述尤为重要。研究者可以通过提供多个输入,LLMs会自动总结出文本的主要内容,生成精炼的综述。
文本编辑:在编辑文本时能够识别语法错误、风格不统一或内容不清晰的部分。研究者可以借助AI工具快速校正文本中的语法错误,调整写作风格,使文章更具可读性。特别是在学术写作中,LLMs可以帮助确保文字的精确性和简洁性,减少不必要的冗长表述。
评估文本:LLMs在文本评估方面的应用广泛,特别是学术文章的结构、论点是否连贯、数据分析是否合理等都可以通过LLMs进行快速评估。这种自动化评估方式能够节省研究者大量时间,并确保文章的逻辑性。
生成标题和摘要:根据文章的内容自动生成精准的标题和摘要。特别是在需要撰写简明而吸引人的文章标题时,LLMs能够提供多种选项供研究者选择,并确保标题与内容高度一致。
生成推广推文:为研究者生成简短的社交媒体推广文案,如推文或博客摘要。这一功能对于发布最新研究成果的宣传至关重要,LLMs可以根据文章内容提炼核心观点并生成易于传播的文案。
3.3背景研究
总结文本:在短时间内对大量文献进行总结,并生成简洁的文本摘要。这一功能在经济学研究中非常有用,研究者可以快速了解大量文献的核心观点,而不必逐字逐句阅读原文。
文献研究:自动搜索并整理相关的文献资源,生成详细的文献列表。研究者可以通过输入关键词,LLMs根据数据库自动生成包含相关文献的研究报告,有效简化文献研究的过程。
格式化参考文献:自动化处理参考文献的格式调整。无论是APA、MLA还是Chicago风格,LLMs都能快速生成符合学术规范的参考文献列表,并自动检查引用是否完整和准确。
翻译文本:支持多语言文本翻译,能够帮助研究者在跨文化学术交流中进行更便捷的沟通。无论是将英文论文翻译为中文,还是将国际文献翻译为本国语言,AI都能提供精确的翻译结果。
解释概念:在研究过程中,LLMs能够快速解释复杂的经济学概念和理论,为研究者提供简明的背景知识。这一功能特别适合新手研究者,帮助他们快速掌握所需的专业术语和概念。
3.4代码
代码编写:为研究者生成符合需求的代码段。无论是数据处理、统计分析还是模型构建,LLMs都能根据需求快速生成相关代码,大幅减少研究者手动编写代码的时间。
解释代码:研究者不仅可以让LLMs生成代码,还可以让其解释现有代码的作用和运行机制。这一功能对于初学者理解复杂的代码逻辑尤为有用,也能帮助资深研究者更好地调试代码。
代码翻译:进行代码的语言翻译。例如,将Python代码转换为R语言,或将MATLAB代码翻译为Python。这对于跨平台研究有极大的帮助,能够提高研究的灵活性。
调试代码:自动识别代码中的错误,并提供调试建议。研究者可以通过LLMs自动检查代码中的逻辑错误或语法问题,帮助加快调试过程,确保代码的准确性和高效性。
3.5数据分析
创建图表:根据研究数据自动生成各类图表,帮助研究者直观展示研究结果。无论是条形图、折线图还是散点图,LLMs都能根据输入数据生成最合适的图表形式。
从文本中提取数据:从大段文本中提取有用的数据,并自动将其格式化为研究者需要的形式。这对于需要处理大量文献的定量研究尤为有效。
重新格式化数据:根据研究需求自动将数据重新格式化,例如将非结构化数据转换为结构化表格,或将数据转换为适合分析的格式。
文本分类与评分:对大规模文本进行分类和打分,帮助研究者快速筛选出与研究主题相关的文本数据,并根据预设的标准对其进行评分。
提取情感:进行情感分析,帮助研究者分析文本中表达的情感倾向。这在社会经济研究中非常有用,特别是分析舆论或公众情绪时,LLMs的情感提取功能能够提供有价值的见解。
模拟人类受试者:模拟人类受试者的行为,用于经济实验或行为经济学研究。研究者可以利用LLMs模拟不同情境下的决策过程,帮助预测经济决策的可能结果。
3.6数学推导
设置模型:设置复杂的数学模型,特别是在经济学研究中,LLMs能够根据输入的参数和目标自动构建相应的经济模型。
推导方程:进行数学推导,并生成复杂的方程。这在理论经济学研究中非常有用,能够加速模型构建的过程。
解释模型:解释现有数学模型的运行机制,帮助研究者更好地理解模型中的变量关系和数学逻辑。
3.7总结
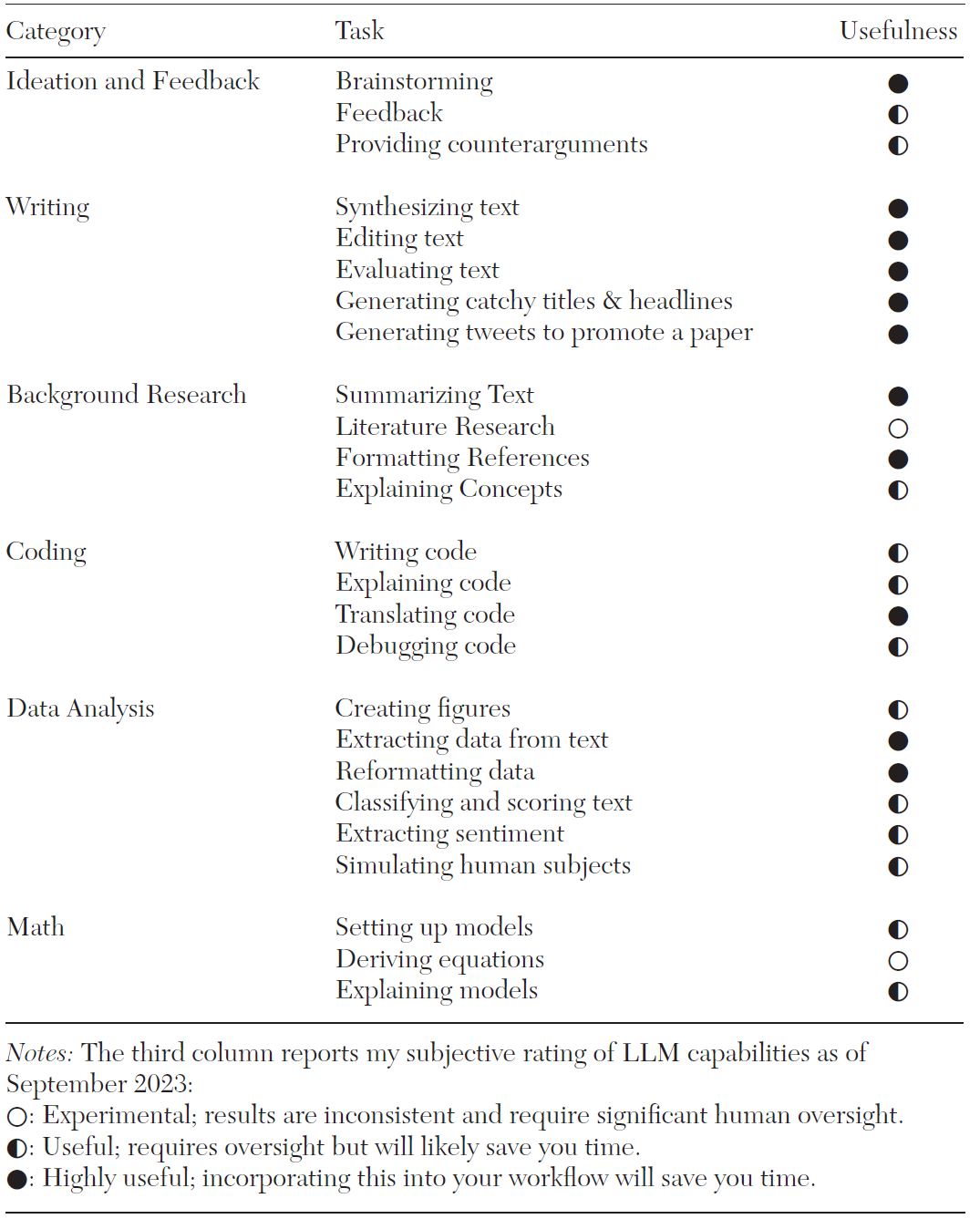
本章的核心内容集中于LLMs在六大领域中的实际应用表现,并对各项功能进行了分类和评估。这些领域包括创意与反馈、写作、背景研究、编码、数据分析和数学推导。通过表2的评分体系,该文对LLMs的实用性与稳定性进行了精确划分,展示了不同功能在学术研究中的价值。
首先,实心圆(●)的功能表现出色,几乎不需要人为干预,能够显著提升研究效率。这类功能集中在写作和背景研究领域,如生成摘要、标题和参考文献格式化等任务。这些功能在日常研究工作中已经展现了极高的稳定性和效率,帮助研究者节省了大量时间和精力。其次,半满圆(◐)代表这些功能已有一定的实用性,但在一致性和准确性上仍存在不足。例如,跨领域的文本综合、翻译复杂学术文献、以及处理复杂的代码任务等功能仍需要一定的人工监督。这些功能尽管已经能在多数情况下节省时间,但在精确性上仍需要进一步优化。最后,空心圆(○)的功能仍处于实验阶段,表现较为不稳定,尤其是在生成反驳意见和复杂数学方程推导的任务中。这些功能尽管具有潜在应用价值,但在当前阶段仍需谨慎使用,并要求较多的人工监督和修正。
总体而言,LLMs在某些领域,如写作和数据分析,已经展现出高度的实用性,极大地提高了研究效率。而在处理更复杂的任务时,其功能仍需进一步完善和提升。随着技术的持续发展,生成式AI在未来的研究工作中将会更加高效和可靠,为学术界提供更广泛的支持。
表2 大语言模型功能及实用性评分汇总
代码
04
基于LLMs展开的研究中,代码的使用至关重要,能够帮助研究者通过自动化方式生成文本并进行数据分析。该文提供的脚本及其相关附件是经济学研究者使用LLMs进行文本生成的一个具体实例。通过这一工具,研究人员能够高效调用OpenAI的API,生成所需的文本响应,并将结果存储为结构化文件,方便进一步分析。本节将对代码的功能、实现方式以及其在实际研究中的应用进行详细解析。
4.1核心功能概述
脚本的主要功能是从prompts.xlsx文件中读取提示信息,并通过 OpenAI API生成相应的文本回复。这一过程包括对不同模型的调用,例如GPT-4或Davinci,生成的结果随后会输出到results.csv和results.txt文件中。这些文件不仅包含生成的对话内容,还包括相应的元数据,如代币使用情况和模型类型。对于需要批量生成文本的研究者而言,这样的自动化流程能够大幅提升工作效率。
4.2代码结构解析
从整体上来看,的实现流程可以分为几个步骤:
(1)API密钥设置与初始化
在代码的最初部分,脚本会检查用户是否配置了OpenAI API的密钥。如果没有,则会提示用户手动输入。为了确保后续的API请求能够顺利进行,这一部分是必不可少的。研究者也可以选择将密钥配置为环境变量,以避免每次手动输入。
(2)读取提示文件并处理
在prompts.xlsx文件中包含了每次对话的提示内容、模型类型等关键信息。通过pandas库读取该Excel文件,脚本会逐行处理每个提示,并根据模型类型选择相应的API进行调用。每次提示的结果将以对话的形式生成。
(3)API调用与生成响应
在生成对话时,脚本根据每个提示行中指定的模型类型调用OpenAI的ChatCompletion或Completion API。这一设计使得研究者可以灵活地选择不同的模型,以满足不同任务的需求。例如,GPT-4被广泛应用于复杂的对话生成任务,而Davinci则适合更具创意或文本生成的任务。
(4)结果输出与存储
生成的文本响应会被自动写入results.csv和results.txt文件中。results.csv文件记录了每次对话的详细元数据,例如生成的内容、使用的提示、模型类型以及代币的使用情况。这些元数据有助于研究者后续分析LLMs的性能,而results.txt文件则展示了完整的对话内容,便于研究者快速查看生成结果。
4.3代码实现细节
代码的实现围绕自动化处理LLMs对话的主要任务展开。下面将对每个关键部分进行更详细的解释,以帮助读者理解其背后的逻辑和实现细节。
(1)API密钥设置与初始化

这一部分代码首先尝试从环境变量OPENAI_API_KEY中获取OpenAI API密钥,这是连接OpenAI服务的必要凭证。如果环境变量未设置,脚本会提示用户手动输入API密钥。这确保了运行脚本时能够成功连接OpenAI API进行后续的文本生成。
(2)读取Excel文件

这里使用pandas库中的read_excel方法读取包含提示的Excel文件prompts.xlsx。该文件是脚本的核心输入源,包含了每次对话的提示文本、使用的模型类型等元数据。
(3)遍历每个提示并生成响应

脚本通过pandas.DataFrame.iterrows()方法遍历prompts.xlsx文件中的每一行。每一行的提示文本和对应的模型类型将分别赋值给prompt和model变量。
(4)调用OpenAI API生成响应

代码依据从Excel中读取的模型类型决定调用ChatCompletion或Completion API。ChatCompletion用于支持对话功能的GPT模型,而Completion则是通用的文本生成API。每个API调用都会将提示文本发送给OpenAI模型,并获取相应的回复。
(5)处理API响应并提取文本

该代码行提取OpenAI API返回的响应文本。在ChatCompletion模型中,响应保存在message字段,而在Completion模型中,响应存储在text字段。此段代码通过条件判断来确定应该从哪个字段提取结果。
(6)将结果保存到文件中

生成的响应会被追加到results.txt文件中。文件中记录了每次提示的输入和相应的输出结果,方便用户后续查看和分析生成内容。每个提示及其响应都会以“提示-响应”形式依次写入文件中。
(7)生成详细的元数据文件

除了生成文本文件results.txt外,脚本还会将生成结果的所有元数据写入 results.csv文件。该文件记录了每个提示的元数据以及生成的结果和代币使用情况。这为后续的量化分析提供了基础数据。
4.4应用场景
通过该脚本,研究者可以高效地将多个提示文本转化为生成式AI的对话内容。这一功能在处理大规模文本生成任务时尤其有用。例如,在经济学研究中,研究者可能需要自动生成多种场景下的对话,以测试不同经济假设下的结果。这种自动化流程减少了手动输入的工作量,并通过生成的元数据为后续分析提供了支持。
4.5学术意义
生成式AI在经济学研究中的应用还处于探索阶段,而提供了一个标准化、可重复的框架,帮助研究者快速入门这一领域。通过自动化生成对话、分析文本输出,研究者可以更好地理解LLMs的应用潜力,并将其整合到日常研究工作中。这种流程不仅提高了工作效率,还为研究提供了新的角度和方法论。
05
总结
该文中,LLMs的六大主要应用领域——创意生成与反馈、写作、背景研究、数据分析、编码及数学推导——均已展现出巨大的潜力。这些工具能够显著提升研究效率,尤其在处理重复性任务时,LLMs展示出了前所未有的能力。从中期来看,LLMs的能力将进一步增强,未来有望成为更为高效的科研助手。随着技术的持续进步,研究者将能够更高效地完成任务,AI将逐渐在研究工作中承担更多的内容生成任务,而人类研究者则可以更多地专注于内容的组织、设计和结果评估。最终,AI有可能在未来产生独立且具备高水平的经济学研究成果,这将极大改变当前的研究范式。
尽管如此,当前的LLMs仍存在局限性。包括“幻觉”现象,即生成不准确内容的风险,以及在处理复杂推理任务时表现的不一致性。这意味着在人类监督下使用这些工具仍然至关重要。此外,LLMs面临的隐私问题、偏见复制问题等挑战,仍需进一步解决。这些问题限制了AI在某些领域的广泛应用,但并未削弱其在微任务自动化中的潜力。
随着生成式AI的持续进步,经济学家和其他研究人员应积极拥抱这些工具,并合理整合到研究工作中,以提高工作效率和推动学术创新。AI的快速发展将为未来的学术研究提供更大的可能性,也为认知自动化带来了全新机遇。
参考文献
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency (pp. 610-623).
Hagos, D. H., Battle, R., & Rawat, D. B. (2024). Recent Advances in Generative AI and Large Language Models: Current Status, Challenges, and Perspectives. IEEE Transactions on Artificial Intelligence.
Vaswani, A. Shazeer N. et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems.
Abstract
Generative artificial intelligence (AI) has the potential to revolutionize research. I analyze how large language models (LLMs) such as ChatGPT can assist economists by describing dozens of use cases in six areas: ideation and feedback, writing, background research, data analysis, coding, and mathematical derivations. I provide general instructions and demonstrate specific examples of how to take advantage of each of these, classifying the LLM capabilities from experimental to highly useful. I argue that economists can reap significant productivity gains by taking advantage of generative AI to automate micro-tasks. Moreover, these gains will grow as the performance of AI systems continues to improve. I also speculate on the longer-term implications of AI-powered cognitive automation for economic research. The online resources associated with this paper explain how to get started and will provide regular updates on the latest capabilities of generative AI in economics.
推文作者:吕志冲,西南交通大学管理科学与工程博士,研究方向为大语言模型与金融预测,欢迎学术交流。推文内容若存在错误与疏漏,欢迎邮箱批评指正!
个人邮箱:
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}