
图片来源
必应
原文信息:
Gilbert, B., Gagarin, H., & Hoen, B. (2023). Distributional Equity in the Employment and Wage Impacts of Energy Transitions (No. w31608). National Bureau of Economic Research.
原文链接:
01
引言
美国政府正积极推行能源转型政策,利用可再生能源逐步替代化石能源。能源转型过程和机制更加复杂多元,给不同地区和人群带来的潜在影响存在显著的差异性,并可能导致进一步的分配不均。将公平正义理念嵌入能源政策之中,降低能源转型对边缘或脆弱群体的压力,改善能源政策的福利再分配机制,正是环境和能源正义理念的思想体现,也是可持续发展观的应有之义。
本文考察了美国风能发展对当地居民就业和工资水平的影响及其在不同群体中的异质性影响效应。具体而言,作者分别估计了能源转型对美洲印第安人/本地阿拉斯加人以及白人工人的影响;对拉美裔工人的影响;对男性和女性工人的影响;对四类不同受教育程度工人的影响。此外,作者对比了两类数据集的分析结果:一是加总到县级的宏观数据集;二是工人层面通过地理编码且限制获取的微观数据集。
数据方面,作者使用美国调查统计局提供的纵向雇主-家庭动态数据集(LEHD)。该数据集涵盖了美国23州风能项目建设中工人的住址信息、就业状态、工资收入、年龄、性别、人种、种族、受教育程度。作者将该数据集与美国风力发电机数据库进行了合并。作者还利用县级加总的宏观数据集进行估计和对比分析。
识别策略方面,为应对繁重的计算任务(作者使用的地理编码微观数据集属于大数据),作者采用了两种识别策略。首先,作者在其中一个子数据集上使用一种特殊的空间滞后模型结合偏移-份额IV(shift-share IV)的识别策略。这一识别方法需要极高的算力,耗费大量的运算时间。为此,作者随后采取局部投影的DID方法(LPDID)在整体数据集层面(其实是一个近似整体样本的子集)进行因果推断。LPDID的优势在于计算速度快,允许处理变量为连续型变量,并且该方法也能够修正交错DID模型中TWFE估计量的偏误问题。
研究表明,风能发展显著提高了当地居民就业和工资水平。该效应在不同群体间存在显著的异质性。具体而言,黑人工人受到的影响最强;男性工人的回报高于女性工人;高中没毕业的工人受到的影响最强,其次是大学毕业的工人。
数据
02
1.风能数据
风能数据来自美国风力发电机数据库。该数据集包括风能项目的经纬度坐标、运营年份、额定容量及其他风能发电特征。项目ID编码来自劳伦斯伯克利国家实验室,该编码用于将风能项目和发电厂进行合并。
2.LEHD
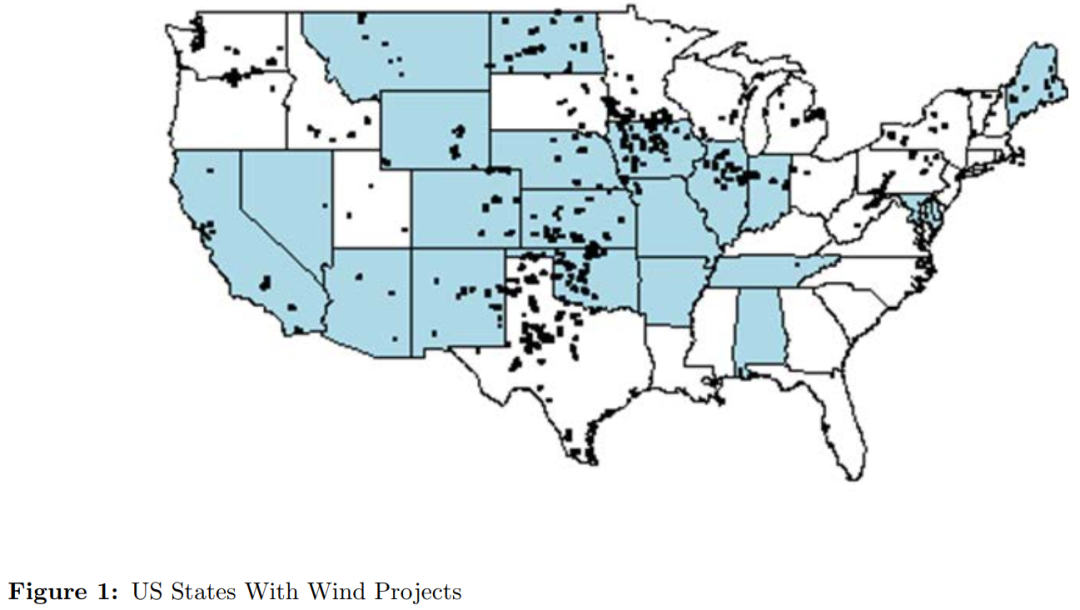
该数据集来自美国人口普查局联邦统计研究数据中心(FSRDC)。LEHD为州-季度层面失业保险名单,覆盖超过96%居住在美国的工人。作者首先将数据整理为州-年度层面,并对23个获准进入项目名单的州进行处理,图1展示了这23个州风能发电项目的基本情况。图1蓝色部分为23个州的风能发电情况,基本能够覆盖全国风能发电设施。作者使用LEHD个体层面信息,包括个体就业、收入、性别、种族、民族、受教育程度以及经纬度信息。
两种识别策略使用了不同长度的数据集,shift-share IV使用LEHD2014数据集(2000-2014),LPDID则使用LEHD2021数据集(2000-2021)。为排除疫情冲击带来的影响,作者将样本区间限制在2000-2020。
在每个数据集中,作者利用工人住址和风能项目的经纬度信息来确认风力发电设施距离每个工人居住地的距离。经过上述一系列操作,最终作者获得一份工人层面的面板数据集,该数据集包括工人就业和工资信息、人口学特征以及不同距离上的风能暴露量。
03
识别策略
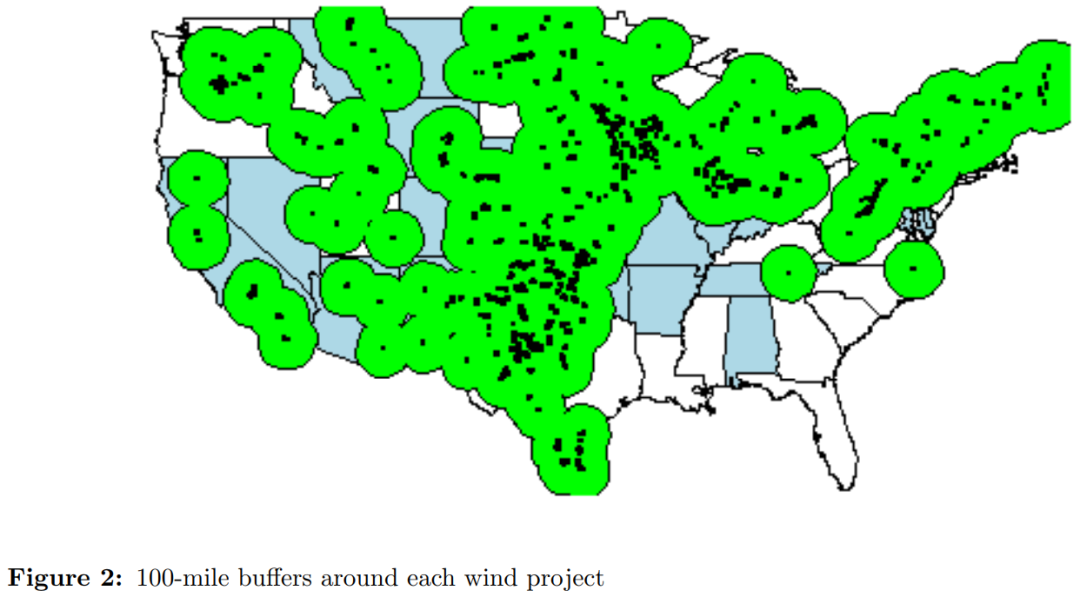
作者认为工人住址选择和劳动供给决策内生于风能发展。此外,有两大重要问题需要克服:一是本文构建的工人层面数据集为十亿量级,对计算能力要求很高;二是由于能源建设项目对劳动力市场具有溢出效应,较难界定处理组和控制组。因为许多工人居住地附近存在多个风能项目,因此按照工人住址距离风能项目地址的最近距离界定处理组会低估暴露程度。如图2所示,作者参考现有研究将风能项目四周100英里的距离作为临界距离,若工人住址不在绿色圆内则为控制组,从图中基本上找不到控制组。
为处理内生性问题和处理组分配的溢出效应,作者利用空间滞后模型进行估计,并在每一个空间滞后项上使用shift-share IV。并且由于该方法对算力要求极高,作者只能在一个随机子样本下进行分析。
上述方法只是备选方案,作者主要采取时髦的LPDID方法进行估计。该方法对算力的要求相对较低,且几乎利用到整体样本进行估计,弥补了shift-share IV方法的不足。
1.Shift-share IV
基于LEHD2014的0.1%随机子样本,作者采用空间滞后模型结合Shift-share IV的方法进行估计。“Share”部分(外生的截面变异)来自每个地区的平均风速,“Shift”部分(时间序列冲击)来自于国家总体风能的扩张趋势,包括涡轮机数量、风能发电厂数量,以及原油、天然气、铝等大宗商品价格和稀土金属综合指数。该策略下,识别既可能来自于“Share”的外生因素,也可能来自于许多外生冲击或者“Shift”。作者将模型设定为式(1)的形式:
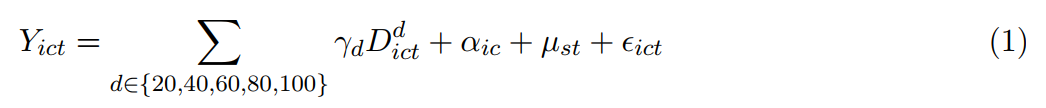
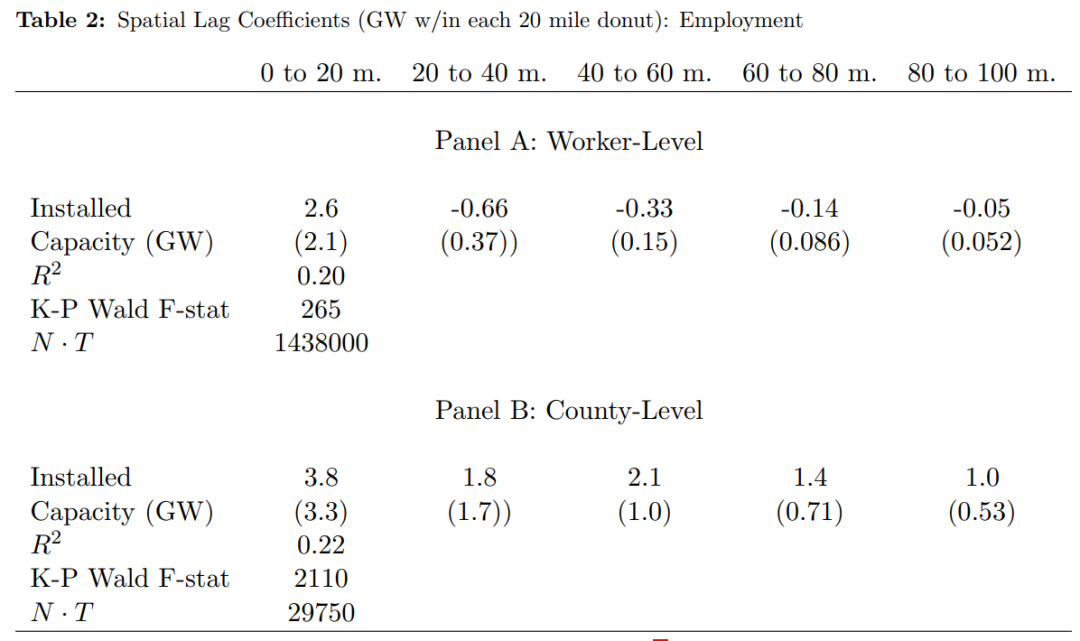
Dictd表示t年个体i的住址到风能项目甜甜圈距离d上的风能发电量,d为0-20一直到80-100。作者利用每位工人住址所在甜甜圈范围内风能发电量的预测值作为Dictd的工具变量。作者首先将美国48个州分成大约216000个大小均匀的六边形,这些六边形大概相对于人口普查区域的平均大小。利用美国风力发电机数据库,作者随后计算了每个六边形在每一年度的总电机数量和发电量。由于许多六边形内风能发电量为0,因此作者采用面板泊松回归模型预测电机数量和装机容量。作者控制了六边形固定效应、州-年份固定效应,平均风速的三次多项式与每年美国全国的总风能交互项,当年美国的风能发电机数量,当年美国的风能发电厂数量,商品价格向量。此外,考虑到许多甜甜圈距离上根本没有风力发电量,所以IV估计结果可能和OLS相差不大。为此,作者在县层面进行汇总,将县作为处理单位进行分析,最终使得县级层面上存在发电量的variation。作者将县层面预测的风力发电容量作为方程(1)内生解释变量的IV并进行估计。
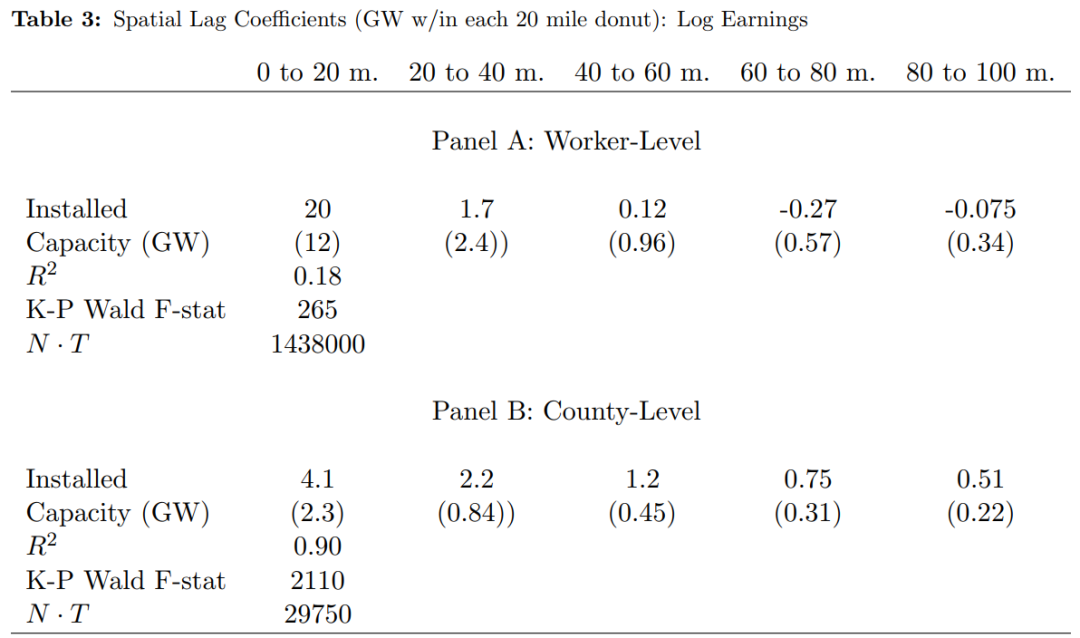
接下来简要介绍该方法下回归结果。如表2和表3的Panel A所示,当距离超过20以后,估计结果显著下降。而甜甜圈距离(工人住址到风能项目的距离)为0-20的情形下捕捉了绝大部分风能项目的影响效果。通过对比表2和表3的第(1)列回归结果可以发现,工人层面和县层面回归结果的差异在结果变量为工资时更为明显。作者指出,LPDID方法下也会产生类似结果,说明两种方法的分析具有可比性。
2.LPDID
模型设定如式(2)所示:
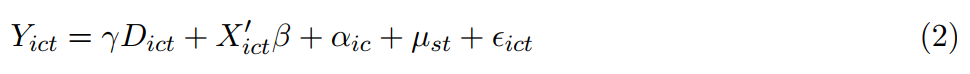
作者定义居住地附近20英里以内有公用事业级风能发电容量风能项目的工人为处理组,否则为控制组。Yict表示就业和工资水平。处置变量Dict有两种定义方式,一种是作为虚拟变量定义工人住址附近方圆20英里范围内是否包括10兆瓦级别的风能发电站,另一种则是定义连续变量即以千兆瓦为单位测量当年20英里内的总发电容量。Xict表示控制变量向量,表示t年20英里之上甜甜圈距离内(20-40直到80-100)的风能发电量的空间滞后项。αic表示工人-县固定效应,捕捉不随时间变化的工人所处位置的特征,例如工人在当地特定工作机会中的生产率。μst表示州-年份固定效应,捕捉州层面的宏观趋势特征。
为估计式(2),采取连续长差分处理方式,进而对式(3)进行估计。
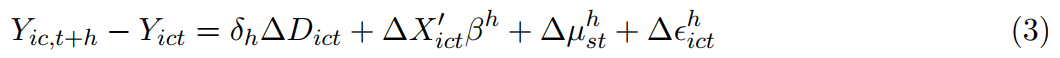
每次差分都将样本限定在新处理组(ΔDict > 0)和尚未接受处理(Dic,t+h = 0)。处理效应δh对应事件研究法下每一个事件窗口期h的估计结果。干预后δh的均值就是方程(2)平均处理效应γ。利用图形可以展示事前每一期的处理效应以及联合显著性水平。控制Yict的滞后项可以控制事前趋势差异从而得到条件平行趋势,同时控制基于事前结果变量的内生选择。
3.蒙特卡洛估计
鉴于作者构建的数据集规模过于庞大,即便是LPDID方法下计算速度仍十分缓慢。为解决这一问题,作者随机抽取一百万工人样本,重复100次,按照式(3)进行估计后得到估计系数和标准差的均值。作者在县层面进行分层抽样,重点增加了工人数量较少的县的抽样权重。后续的实证结果主要基于该方法得来。
4.将数据加总至县层面
若将工人水平的微观数据集加总至县层面,会对估计结果造成偏误。为探究这一偏误的大小及其在不同子样本下的分布情况,作者将微观数据集加总至县层面。作者将结果变量数据加总至县层面,并按照一个县是否有10兆瓦风力发电项目或者一个县的风力发电量定义处理组变量。
04
实证结果
1.平均效应
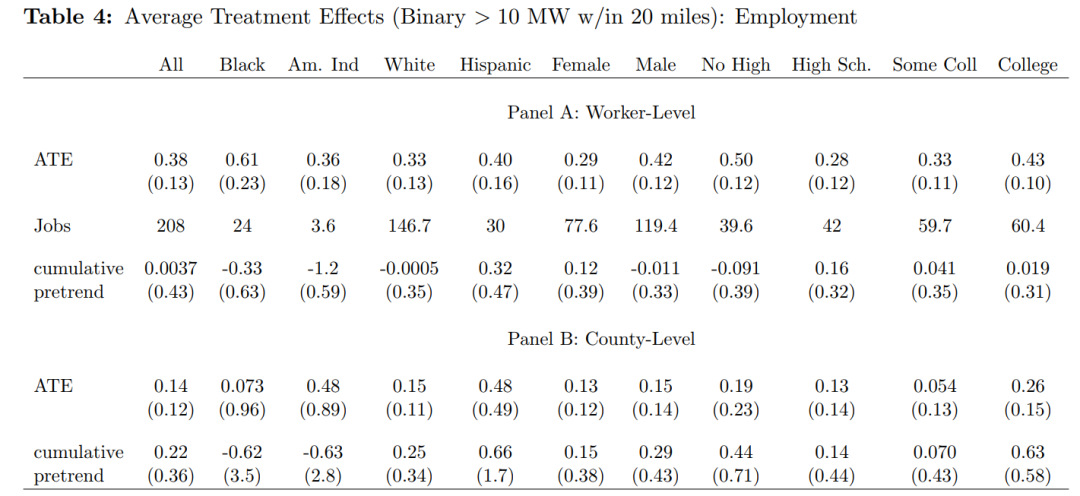
表4和表5展示了风能发展(处置变量为虚拟变量)对当地工人就业和工资水平的平均处理效应。表6和表7则将处置变量换成了连续变量,其他设定不变。聚焦表4和表5(表6和表7结果类似,被作者放在附录部分),Panel A呈现了工人层面经100次蒙特卡洛抽样以后的LPDID估计结果。可以看出,总体而言风能发展显著提高了当地工人的就业率和工资水平。Panel B展示了加总至县的估计结果,不难看出平均处理效应显著降低。从纵向看,第(1)列报告了总样本下估计结果,而后续列则报告了分样本的回归结果,可以看出平均处理效应在不同子样本下的估计结果存在显著差异,比如对于没上过高中的工人而言,风能发展给其带来的收益是最大的。当然,即便是在分样本条件下,工人层面数据和加总至县以后的回归结果仍存在明显差异,这意味着加总以后造成了平均处理效应的偏误。
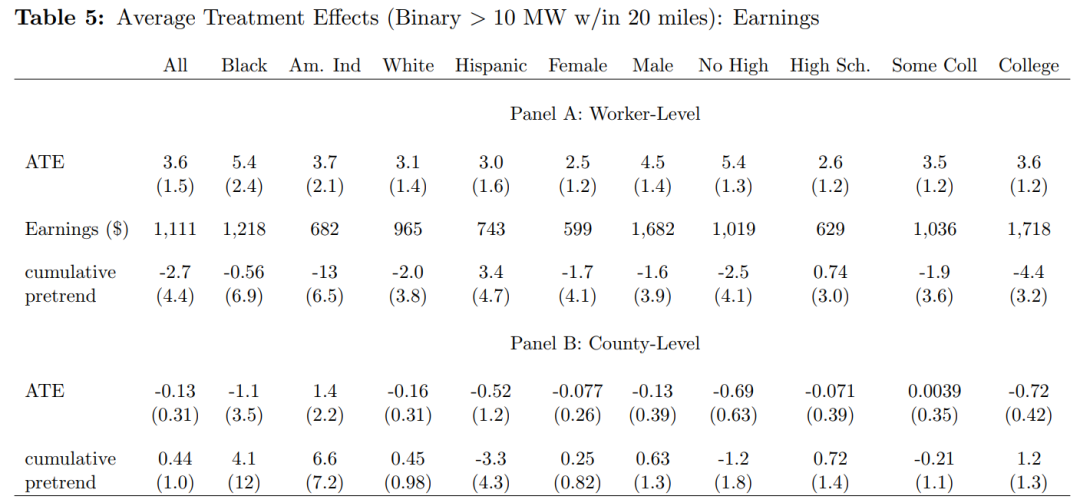
2.事件研究法
事件研究法估计结果如图3和图4所示。由于风能发电设施在项目正式运营之前就开始建设,为捕捉提前建设的效应,作者将干预前第二期作为参照点。结果表明:当数据为工人层面微观数据集时,事件研究法结果表明,风能项目在干预时点以前的点估计结果均不显著,干预后的动态处理效应在前6期是显著的,且呈依次增强的趋势。而使用县级加总数据以后,不仅干预后动态效应均不显著,而且事前趋势也更加不平稳。误差棒的长度比工人数据要短,这表明工人数据的随机抽样过程产生了明显的异质性。
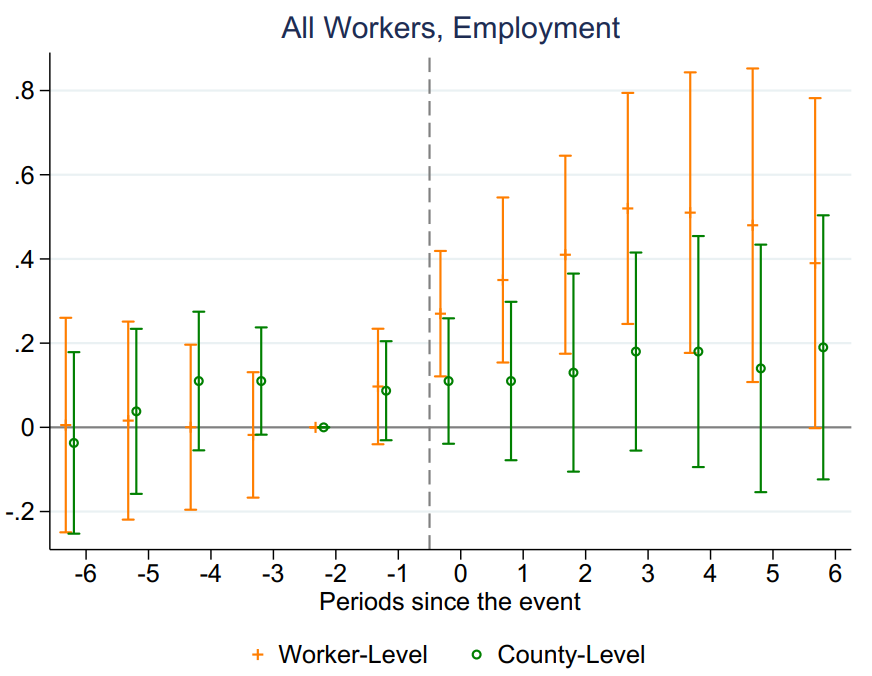
Figure 3: Impact of Wind Capacity on Employment: Worker-Level vs. County-Level
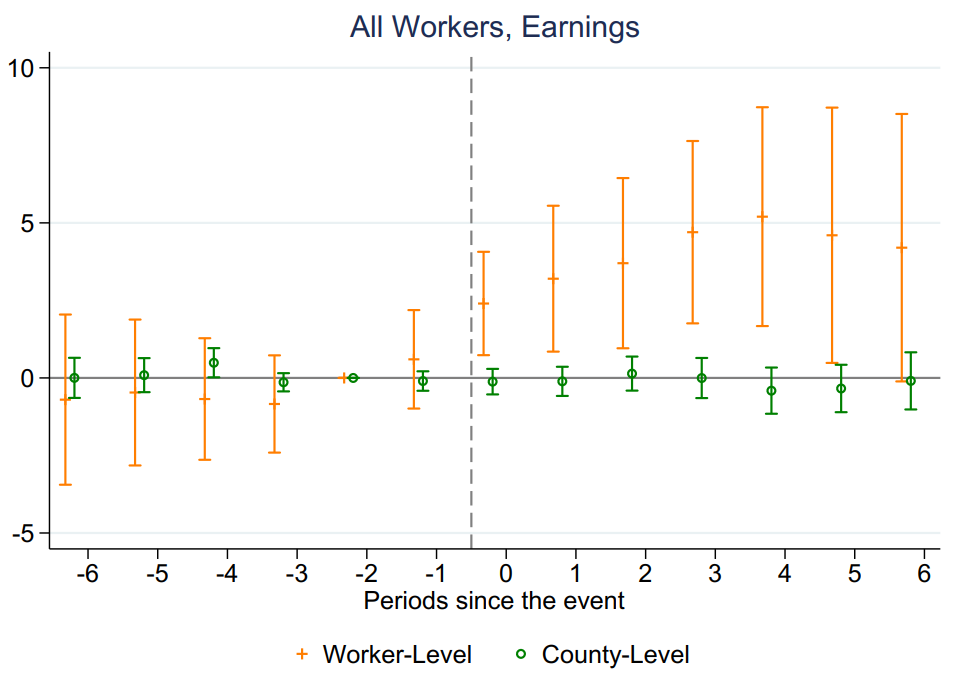
Figure 4: Impact of Wind Capacity on Log Earnings: Worker-Level vs. County-Level
2.1 种族和民族
接下来作者对几组子样本进行事件研究法分析。图5和图6展示了区分种族和民族的异质性检验结果,结果变量分别是就业和工资。结果显示,对于黑人工人(图中绿色线条),风能发展对其就业和工资都有显著的积极影响。并且这一正向作用要大于其他种族和民族的工人,比如白人和拉美裔工人。
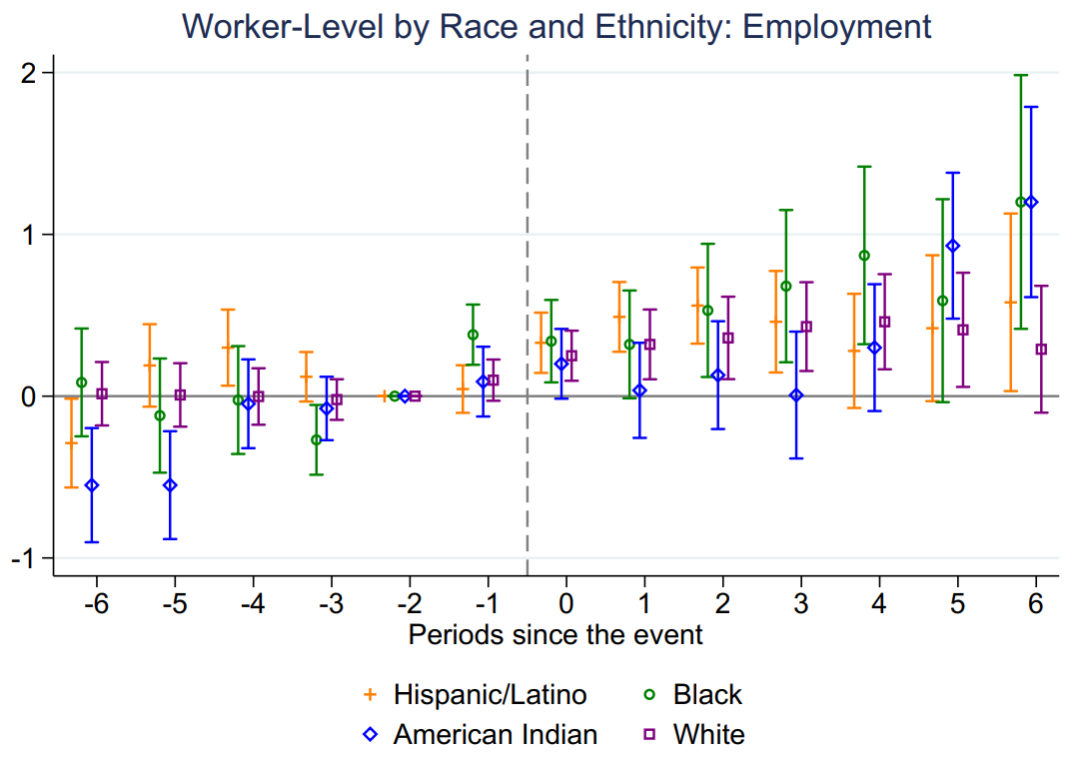
Figure 5
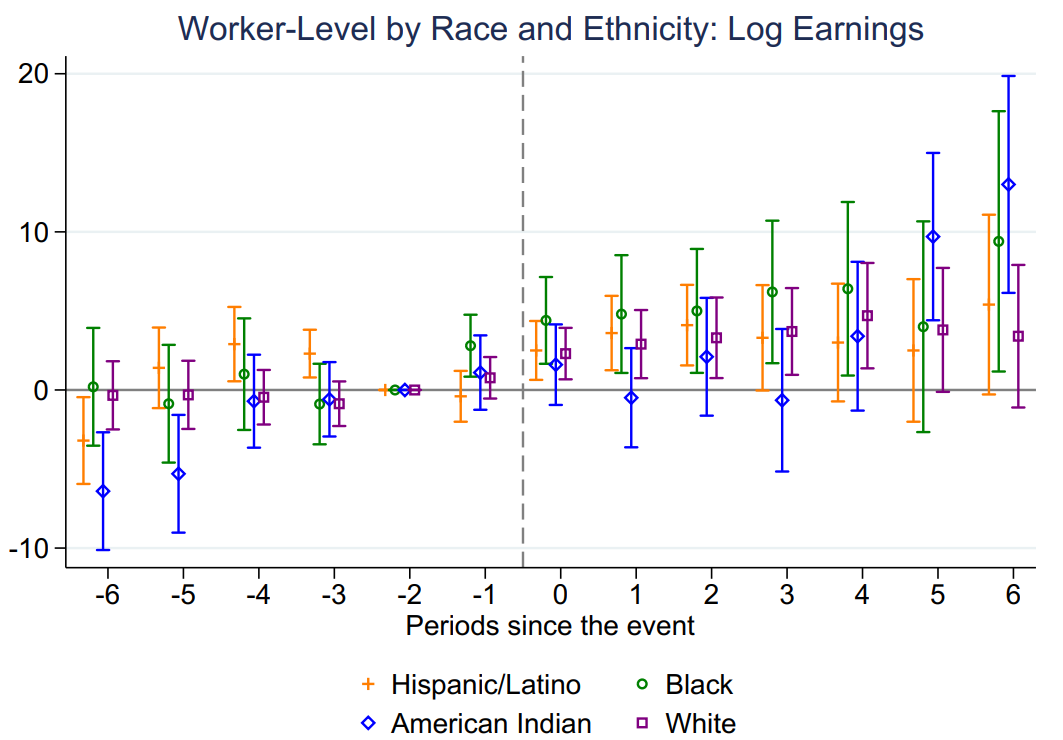
Figure 6
2.2 性别
图7和图8展示了区分性别条件下的分组事件研究法结果。总体上,风能发展对当地男性工人的影响高于女性。
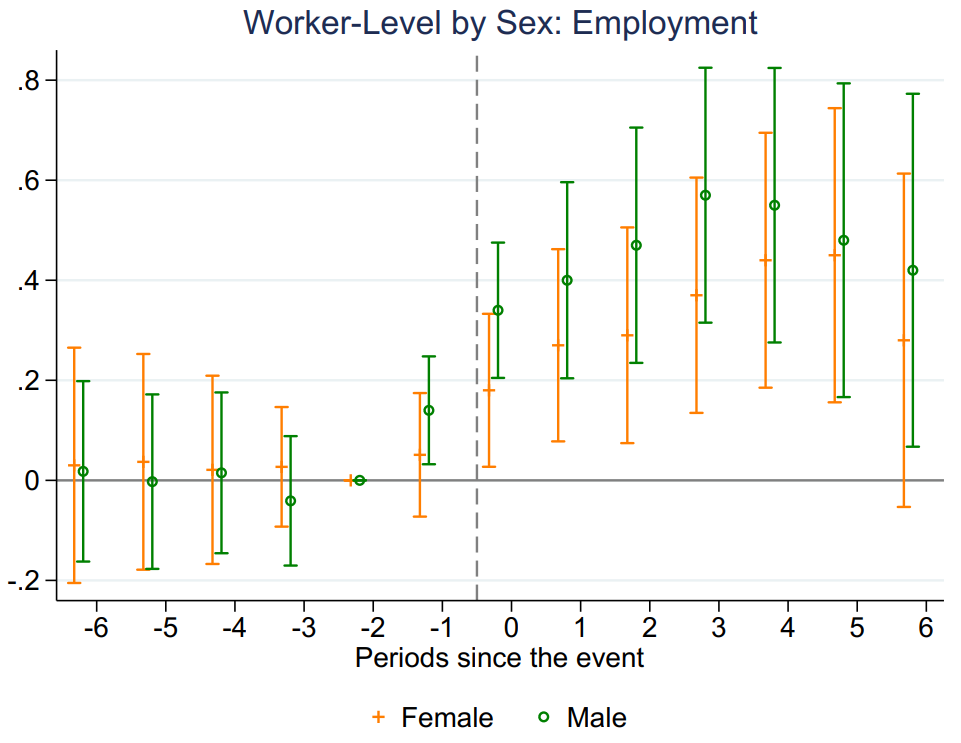
Figure 7
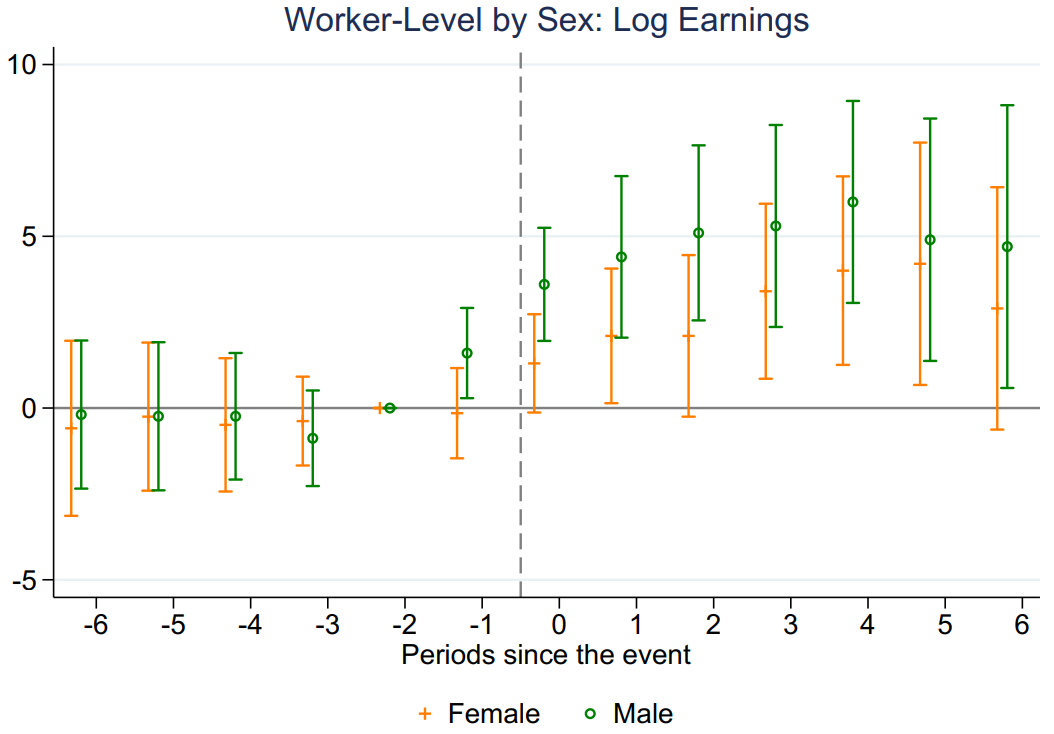
Figure 8
2.3 受教育程度
作者按照工人的受教育年限将其分为四组,分别是没上过高中 vs. 上过高中以及大学毕业 vs. 大学没毕业。分组事件研究法结果如图9和图10所示,可以看出,风能发展对四组教育类型的工人就业和工资都有显著的、持续的正向影响。同时,风能项目对没上过高中的工人影响最大,其次是大学毕业的工人。
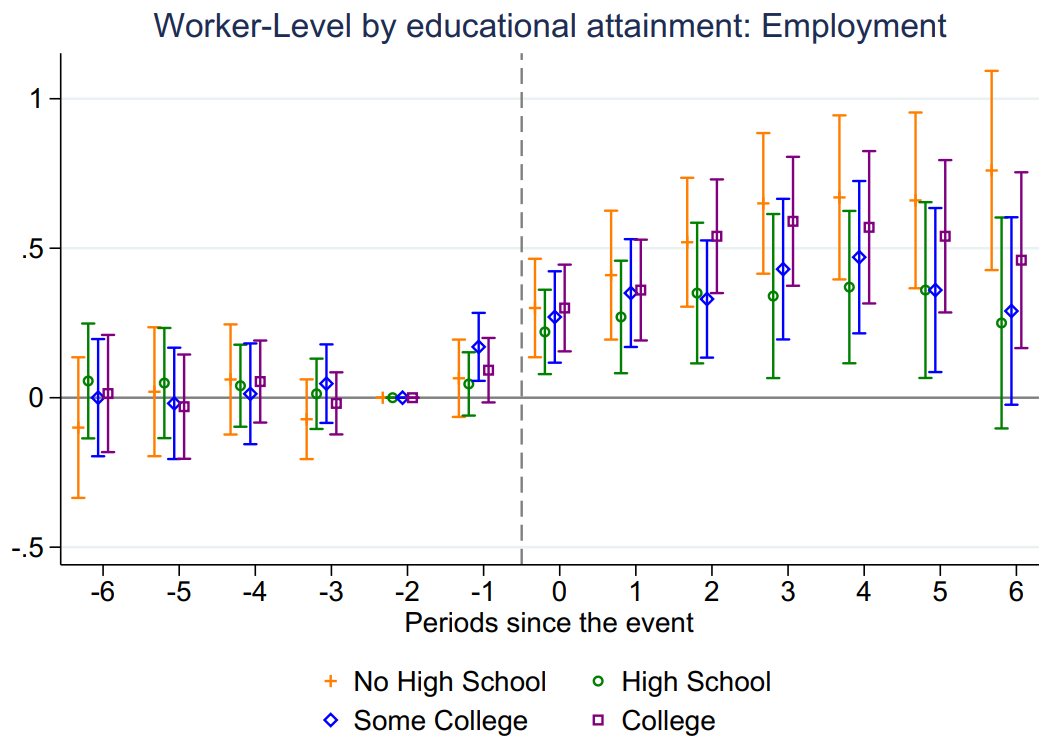
Figure 9
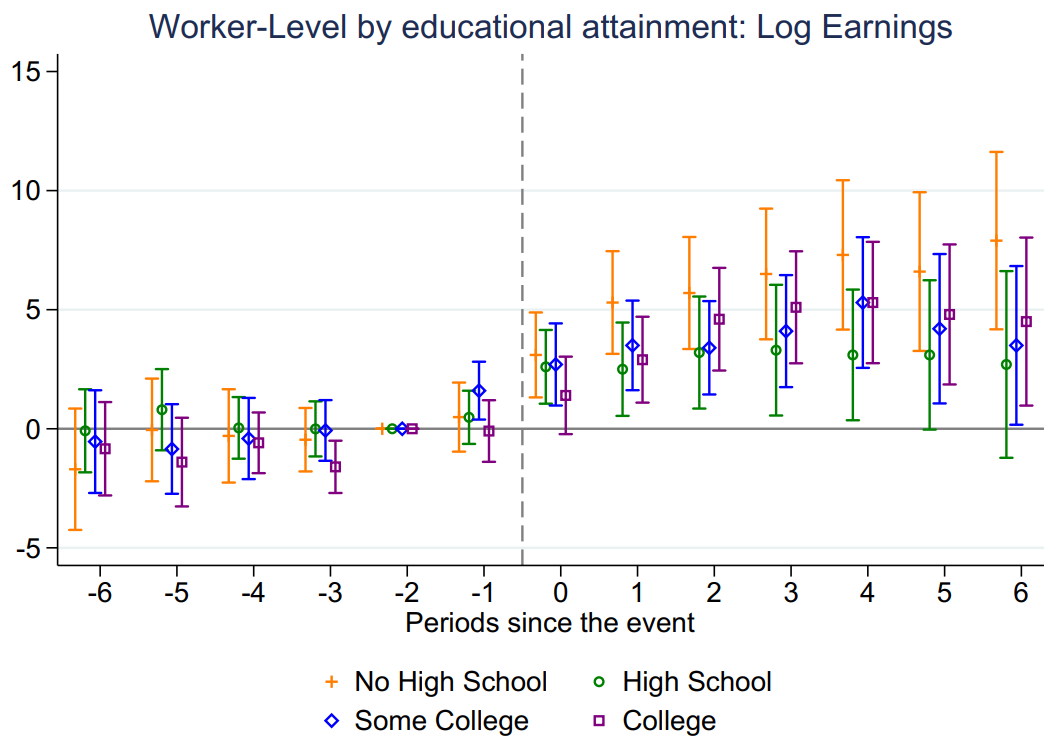
Figure 10
05
结论
美国政府大力发展新型能源技术以促进碳减排,这一生产转型会带来各项收益,同时也使得这些新增收益在不同群体之间的重新分配。作者利用地理编码的工人微观限制数据集,考察了风能发展对当地工人就业率及工资水平的影响。除在整体上探究风能发展的效应外,作者还对不同人群之间的异质性处理效应进行了分析。随后,作者将微观数据在县级水平进行加总,将估计结果与基本结果进行对照分析。作者发现:工人居住地方圆20英里以内存在风力发电站会对其就业和工资产生显著正向的影响。异质性分析表明,该效应对于黑人、男性以及极低技能劳动者或极高技能劳动者而言更加显著。事件研究法表明不存在事前趋势,且干预后风能发展的动态处理效应持续显著地存在,这意味着存在某些渠道使得风能发展能够产生长远收益。使用加总数据的分析结果显著低估了风能发展的平均处理效应,这一结论经过分组回归以及事件研究法分析之后依然成立。
推文作者
张梁,中国财政科学研究院博士研究生,研究方向为财政学和发展经济学,欢迎学术交流~
电子邮箱:。推文内容中若存在错误与疏漏,欢迎邮箱批评指正!
Abstract
We use restricted-access, geocoded data on the near-universe of workers in 23 U.S. states in order to quantify the impact of wind energy development on local earnings and employment, by race, ethnicity, sex, and educational attainment. We find the largest relative impacts for workers without a high school education, or workers with a college education, in addition to other systematic differences across sub-populations. We compare these results to estimates using county aggregates of the worker-level data, such as can be obtained using publicly available data. We find that (a) county-level estimates are dramatically dampened relative to geocoded worker level estimates, and (b) the degree of bias differs by sub-population such that qualitative comparisons of impacts are not consistent using restricted-access data versus county-level data for most sub-populations. We discuss implications for achieving equity goals within energy transition policies.
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}