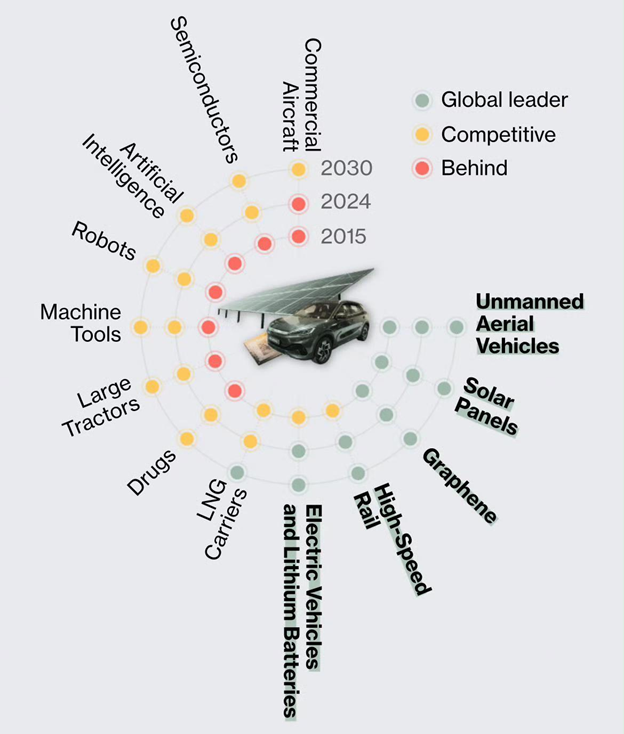
图片来源:中国制造成绩单,彭博社
原文信息:Hanming Fang, Ming Li & Guangli Lu, May 2025. Decoding China’s Industrial Policies, NBER Working Paper 33814.
原文链接略
附录链接略
从美国的汉密尔顿、德国的李斯特,到日本、亚洲四小龙的“东亚奇迹”,再到中国的五年规划、《中国制造2025》、《新一代人工智能发展规划》等,理论和实践反复昭示,产业政策既存在于历史和当下的时间轴,也存在于发达国家和发展中国家的空间轴,任何一个经济体都无法置身于产业政策之外。最近,方汉明老师团队的NBER工作论文,利用大语言模型全面“解码”了2000—2022年中国的产业政策,形成了包括中央、省级、市级政府发布的近300万份文件的综合数据库,提取出政策目标、目标产业、政策基调、政策工具、实施机制以及政府间关系等方面的结构化信息,并且基于上述数据和现有微观数据库进行了大量细致的经验分析。总体来看,本文工作量大、分析框架完善、问题捕捉精准,具有较强的可延展性。从某种意义上说,本文已经不再是一篇简单的论文,而是一部基于中国背景进行产业政策研究的经验分析手册,值得我们反复回看、常读常新!
01
问题提出与边际贡献
早期研究对产业政策主要持批评立场,强调政府干预弊大于利,例如寻租问题。而最近的研究在方法上有了极大改进,因此有不少关于产业政策的积极发现。目前,学者们不再关注是否应该有产业政策这一规范性问题,而是聚焦于目标行业、政策工具、发展阶段、激励措施等实证性问题。例如,Rodrik(2004, 2009)指出,产业政策的问题不在于是否应该实施,而在于如何实施;Juhász等(2022)通过研究国家层面的产业政策,在实证方面做出了重要尝试。但是,对于单一国家内部的产业政策研究仍然很少,这是本文试图填补的文献空白。
具体而言,以中国为背景开展产业政策研究有以下四个方面优势:一是中国广泛制定产业政策以塑造行业发展和技术能力,具体实践的范围广、时间长;二是中央政府制定战略指导方针,地方政府行使自由裁量权,这种“中央—地方”关系会影响产业政策的制定、实验和实施;三是地区之间异质性明显,跨行政单位的政策学习比较普遍,这种“地方—地方”关系也会影响产业政策;四是,地方的自由裁量权为研究产业政策协调中的挑战和可能的影响提供了一个窗口。总而言之,认识中国的产业政策,是认识中国经济在过去二十年中发展经验的关键。
概括来讲,作者指出了本文的三点边际贡献:第一,现有文献经常在特定背景下考察产业政策,这就导致其研究结果可能“喜忧参半”。本文利用大语言模型分析了有史以来最大的政府文件集,能够提供一个更为全面、更为稳健的结论。第二,大语言模型对文本的挖掘颗粒度细,可以得出政策制定、政策工具使用、政策实施与保障、政策传递与学习等多维度的产业政策信息,这对于未来中国乃至其他国家设计与优化产业政策提供了分析范式。第三,现有研究通常局限于国家或省级层面,主要基于特定的文件展开政策评估,而本文拓展了产业政策研究的分析对象。同时,本文还着重探讨了中国政治集权与经济分权相结合的体制对产业政策的影响,并且还关注了地方保护、产业同构等现实问题,全面客观地评价了中国产业政策的绩效与潜在风险。
02
大语言模型的分析流程
现有文献主要基于三种思路测度产业政策,都具有较大的局限性。
第一,依赖于现有的结构化政策文件或具体的政策冲击,例如各地的五年规划有“鼓励”等关键词,可以用于确定支持的产业;“中国制造2025”集中体现了促进制造业转型升级的产业政策。
第二,使用企业数据“间接”衡量产业政策强度,具体涉及补贴、免税期、利息支付和关税等方面。与第一种方法相比,这种方法只关注行业或企业实际获得政府补贴这一维度,而忽视了其他可能的产业政策工具,例如土地和劳动力投入、消费者补贴、政府采购、政府股权基金等。
第三,使用政府文件作为研究对象,基于特定关键词分析产业政策。这种方法虽然扩大了覆盖范围,但是数据集的建立仍然大量依赖于手工整理,例如较为成熟的Global Trade Alert数据库就是各国观察员团队搜集标注的成果。
作者给出了利用大语言模型分析产业政策的详细操作指南,推文篇幅所限,读者可以自行查阅原文和附录,下面仅选取代表性内容进行介绍。
数据来源:北大法宝()上中央和地方政府发布的官方文件,覆盖时段2000—2022年,形成一个约300万体量的政策数据库。
分析流程(如图所示):
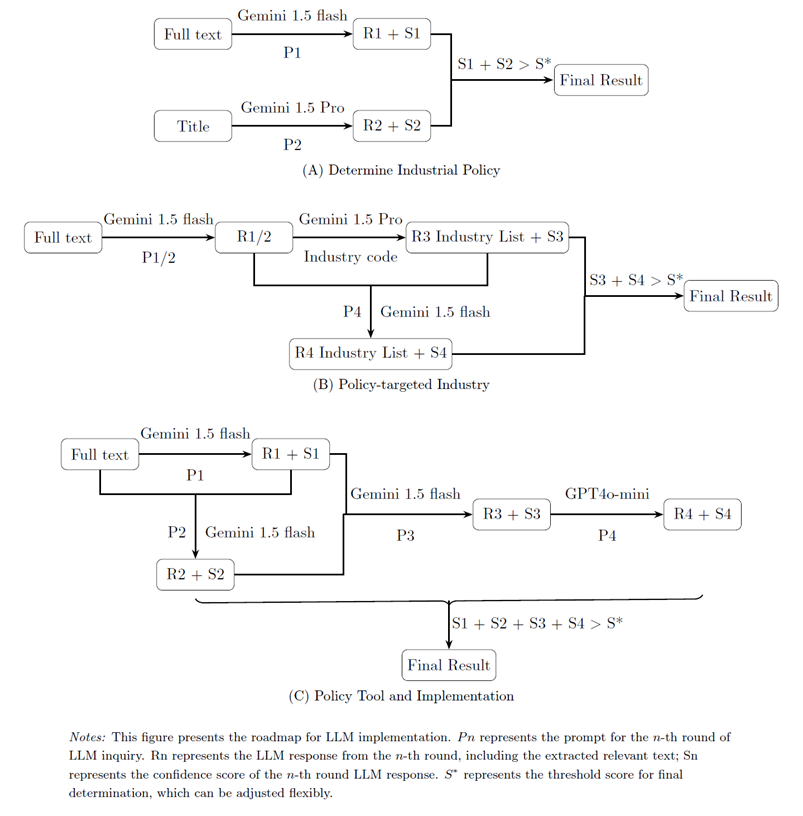
重点提取八个方面信息:
①定义产业政策(选择了一个相对窄化的口径,形成了四条基本判定准则)
②政策基调(划分为支持性政策、监管性政策、抑制性政策三类)
③政策目标(常见的包括促进战略性新兴产业发展,加快技术创新等)
④目标行业/部门(识别到4位行业代码,并且以“直接目标行业”为准)
⑤政策实施工具(基于现有框架引入反映中国特色的政策工具,总结提炼为五种类别)
⑥政策支持的条件(通常包括企业所在地、企业规模与年龄、技术资格、所有制等)
⑦政策实施的组织安排(通常包括激励计划、试验与学习、因地制宜、组织支持等)
⑧政府间关系(通常包括转发与发布、政策依据、政策延续或废除、政策协调等)
大语言模型与关键词检索两种方法比较:
关键词检索会将许多无关内容纳入分析,例如案例报告、政协提案等;大语言模型所确定的产业政策虽然可能不包含高频关键词,但是其能根据上下文理解出产业政策的内涵,而这些是关键词检索方法无法捕捉到的。换言之,大语言模型获取了大量“实质”上的产业政策,而关键词检索只能整理出“形式”上的产业政策,大语言模型突出了情景理解的重要性,更加符合研究需要。
此外,本文还使用了其他微观数据库,具体包括:工商注册企业数据库(来自国家市场监督管理总局)、行政税务记录数据库(来自国家税务总局)、增值税发票数据库(来自国家税务总局)、地方官员数据库(手动搜集)。详细介绍可以查阅原文,这里不再展开。
03
典型事实
典型事实与上文提到的八个方面一一对应,再加一个案例研究,作者的分析思路十分清晰。
(一)产业政策概览
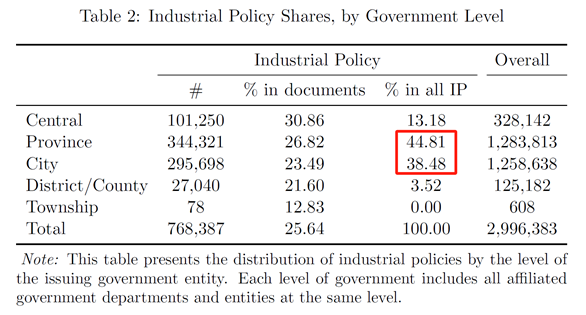
(省市级产业政策占比较高)
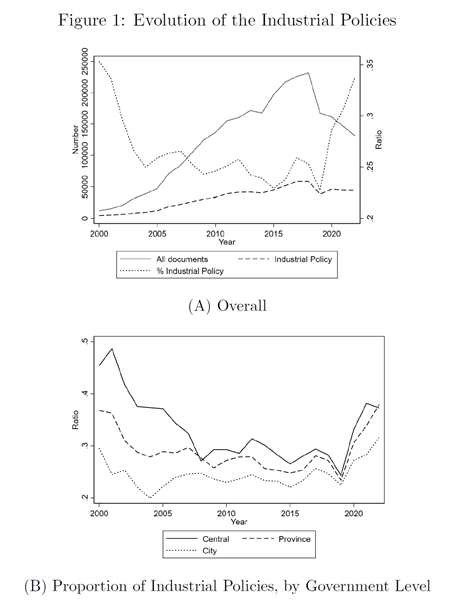
(2018年起产业政策占比大幅上升)
(二)政策基调
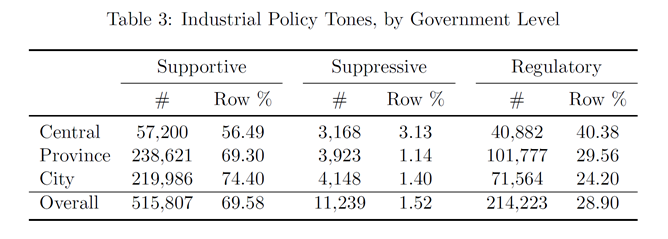
(大部分是支持性政策)
(三)政策目标
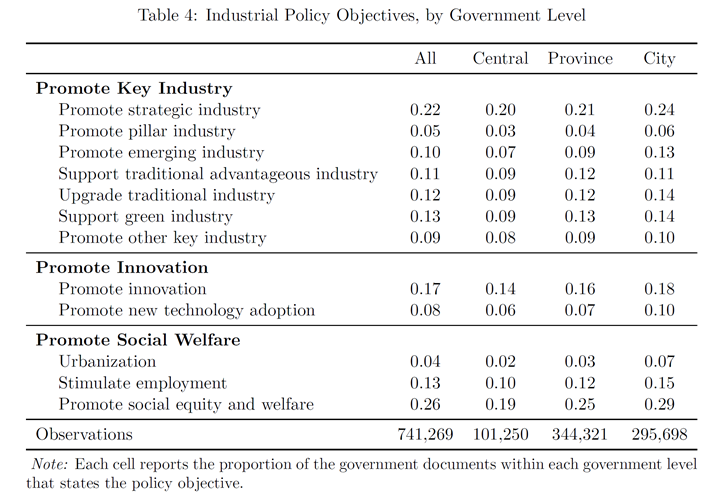
(促进战略性产业是常见的政策目标)
(四)目标行业分布
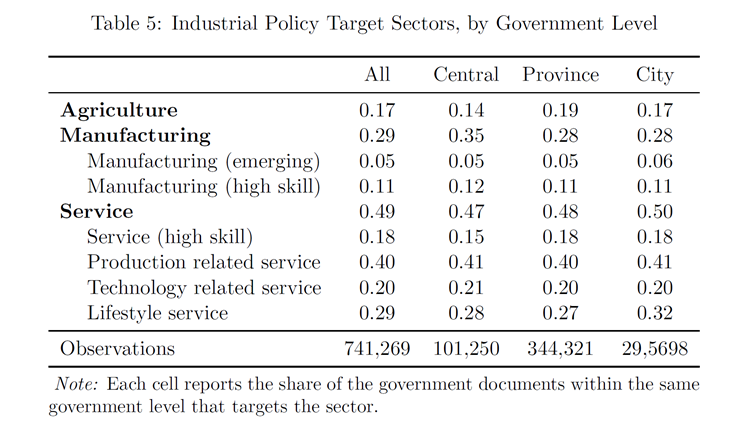
(集中于制造业和与生产相关服务业)
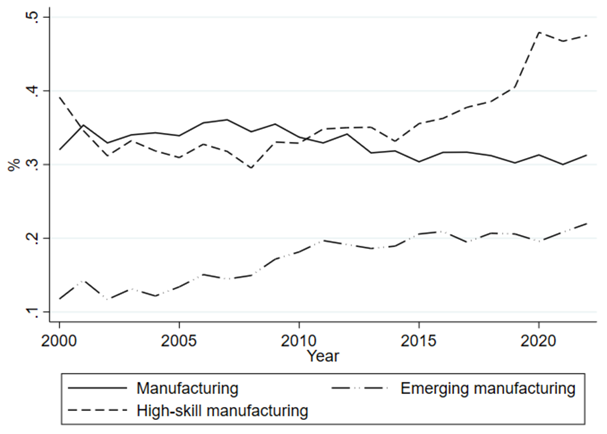
(新兴和高技能制造业占比不断提升)
(五)政策实施工具
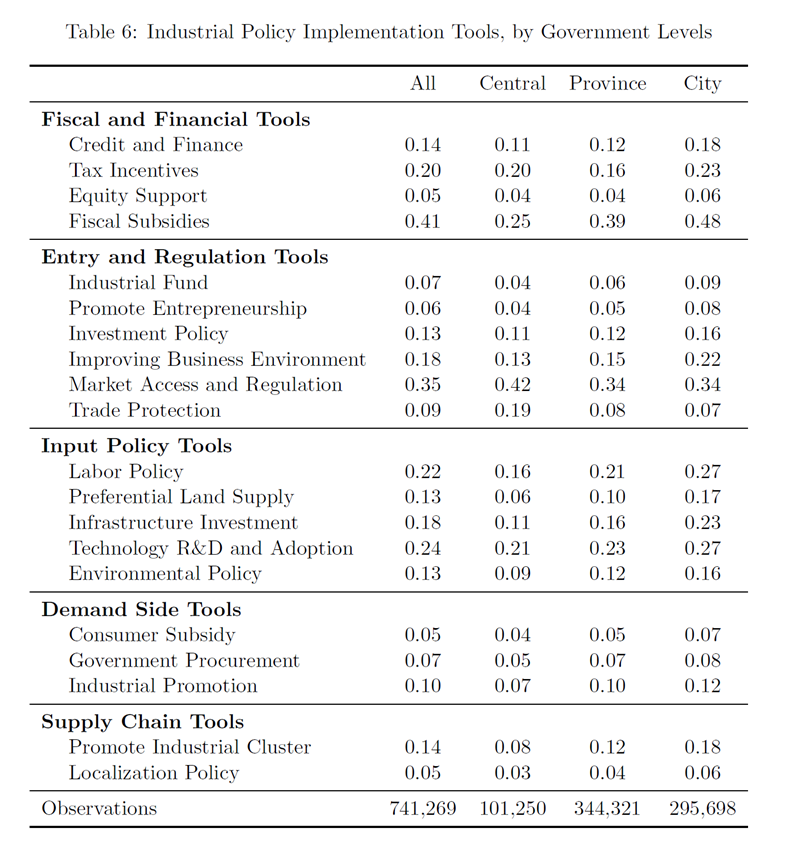
(财政补贴最为常见,超过40%)
(政策重点变化明显)
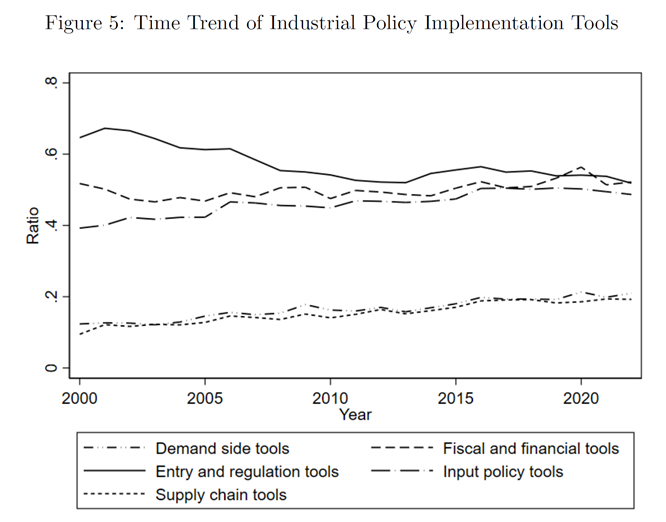
为了便于后续的经验研究,作者又另外设计了一套政策工具的分类标准(五种):
①新兴工具(快速增长型):例如产业基金、产业集群等。
②新兴工具(适度增长型):例如政府采购、本地化政策等。
③传统工具(强劲型):例如基础设施投资、劳动力政策、技术研发、财政补贴等。
④传统工具(稳定型):例如信用和金融、优惠土地供应、改善营商环境等。
⑤传统工具(式微型):例如市场准入和监管、税收优惠、贸易保护等。
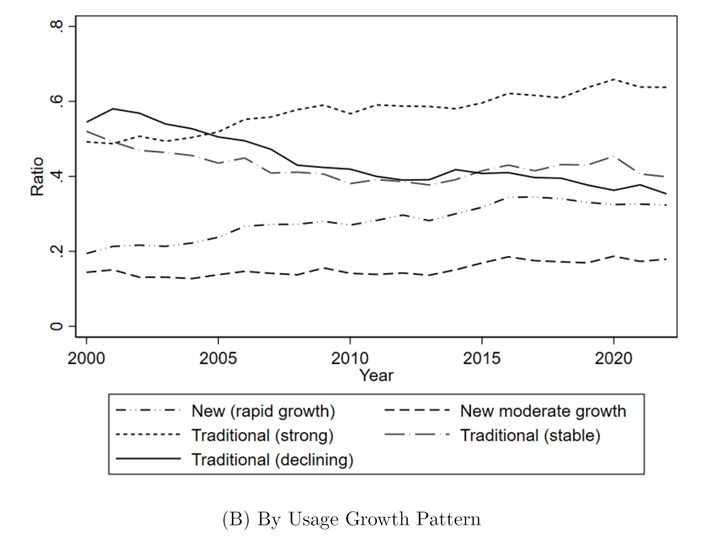
(政策重点变化明显)
(六)政策支持的条件
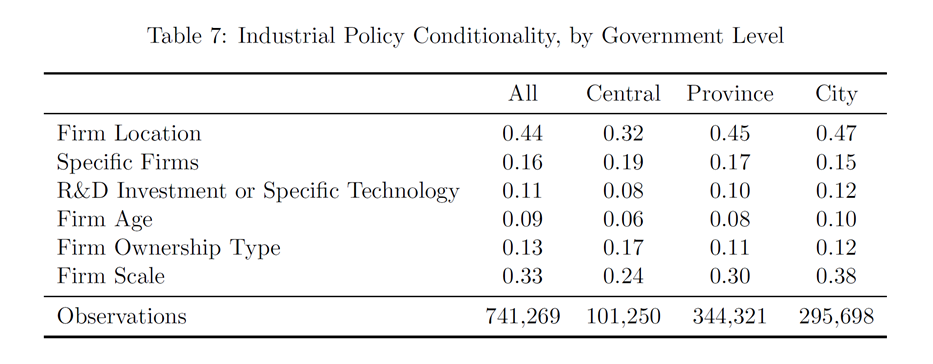
(地域性政策最为典型)
(七)政策实施的组织安排
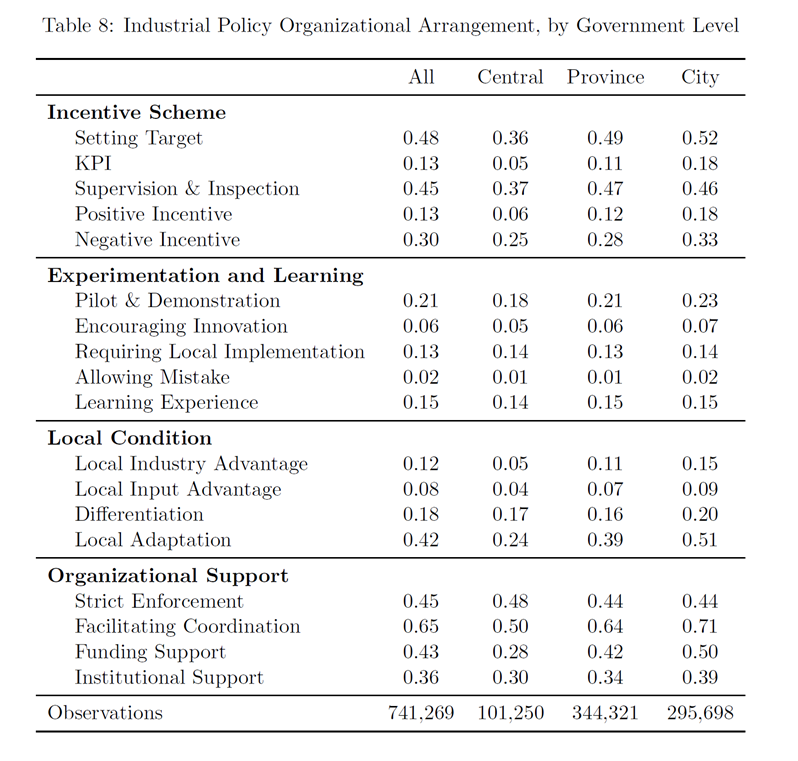
激励计划:目标设定、监督检查最为普遍,都接近一半。
试验与学习:试点和示范占比较高。
因地制宜:适合当地状况占比较高。
组织支持:促进协调发展占比较高。
(八)政府间关系(中央与地方、地方与地方)
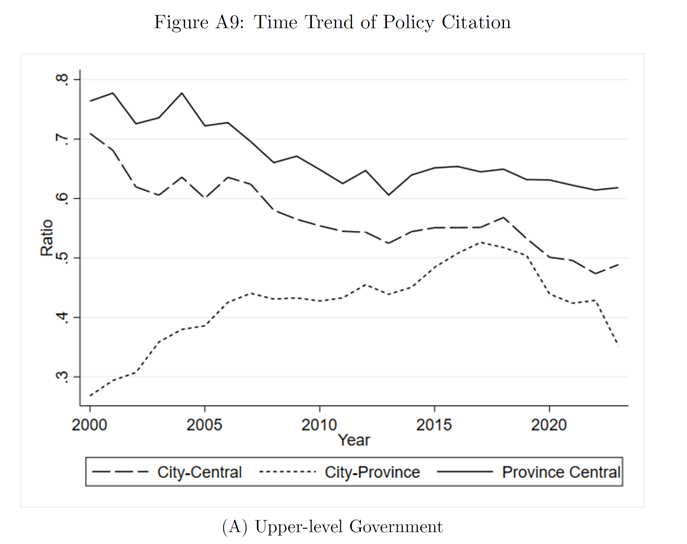
2000—2012年,省级和市级引用中央政策的占比都逐渐减少,地方政府的自主权显著上升。但是,市级引用省级的占比却显著增加,说明省级政府这一次级国家治理具有更强大的垂直整合能力。2013年以后,省级和市级引用中央政策的占比有上升趋势,并且市级引用省级的占比大幅上升。而到了2018年之后,对上级政府政策的引用占比又出现显著下降,这反映出地方政府开始向更加本地化、灵活性的政策回归。
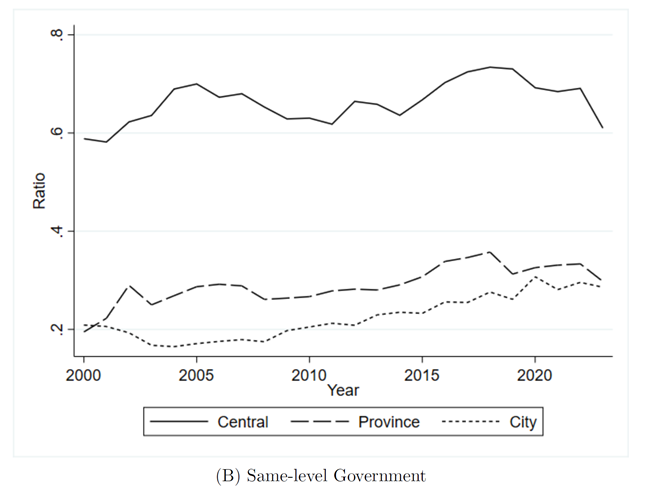
就同级政府而言,省级和市级政府的自引占比都呈现出稳步增长态势,这表明地方政府内部的协调程度有所改善,即地方政府更加依赖于内部一致的政策框架。而中央政府较高的内部引用则体现为各个部委在制定国家各类政策过程中的高度协同(当然也存在波动)。
(九)案例研究:半导体、电动汽车和太阳能
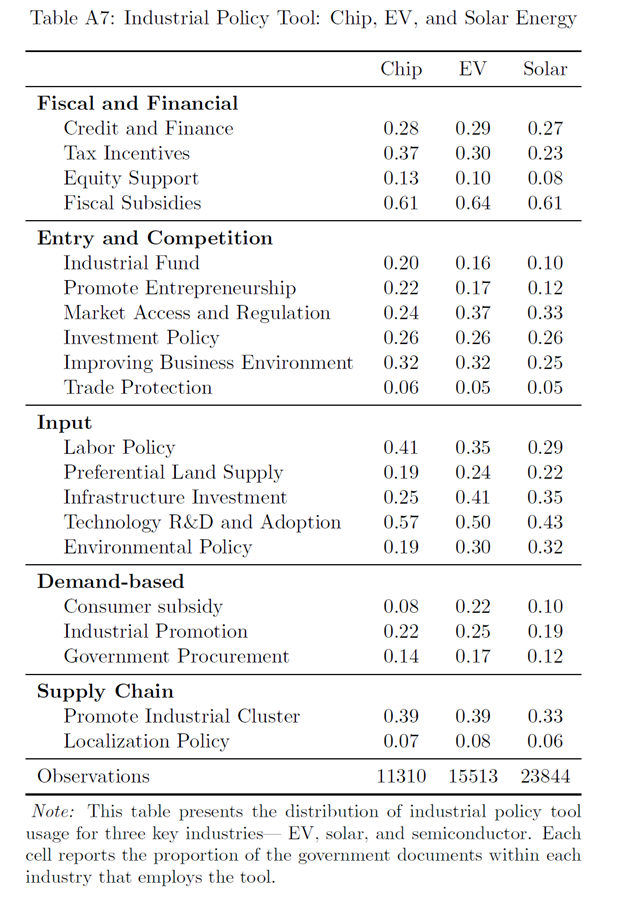
(三个行业的政策工具使用情况)
04
经验证据
本文在实证研究部分的呈现方式比较突破常规,基于四个主题一口气给出了15个“命题”,然后分别进行验证。从某种意义上说,每一个“命题”单拎出来都具备延展为一篇论文的潜质,这足以见得作者在该领域的研究功底。此外,作者也没有拘泥于特定的展现形式,表格和图片都有使用,更加符合读者的阅读习惯和经济直觉。当然,考虑到篇幅,推文只能“忍痛割爱”,在每个主题下仅选取最具代表性的内容进行介绍,对于其余内容感兴趣的读者可以查阅原文或者邮件交流。
需要注意的是,作者还明确指出,该部分关于中国产业政策的这些“事实”只是描述性的,并没有严格地解决政策的内生性问题,但是这并不影响我们认识过去二十年中国产业政策的历史进程。由此可见,一篇好论文,并不一定体现在计量分析技术层面,而应突出研究问题的重要性和研究结论与现实发展的一致性。作者坦诚地指出这一问题,对于青年学者和学生的科研工作大有裨益。
(一)目标产业的政治—经济决定因素
事实1a:城市对目标产业的选择与其基于资本的显性比较优势(RCA)和绝对优势(AA)呈正相关。
计量模型与变量构造:
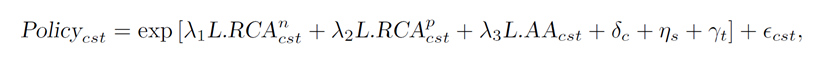
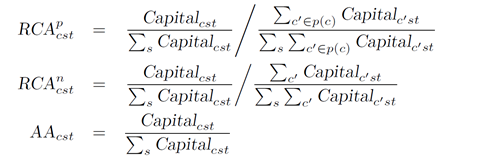
其中:c为城市,s为产业,t为年份,p为省级层面,n为国家层面,Policy为是否出台政策,RCA和AA体现城市专业化程度,使用滞后一期是为避免产业政策反向影响目标产业的企业进入。
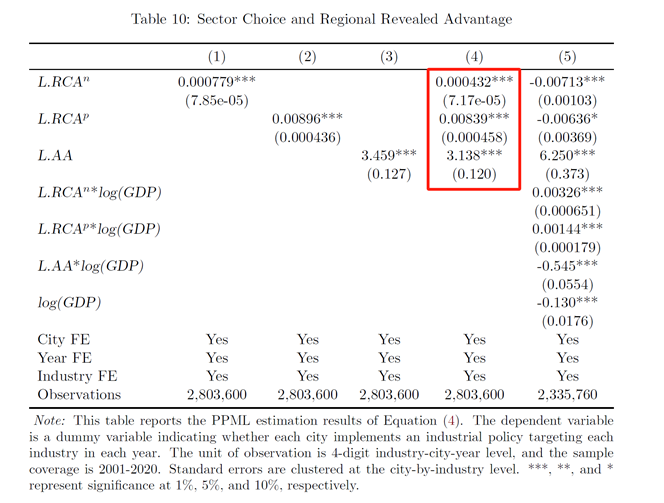
事实1b:市级政府在选择目标产业时遵循上级政府,但这种传递在不同城市之间具有异质性。
计量模型与变量构造:
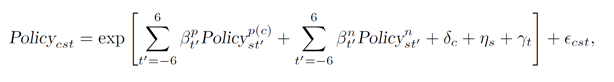
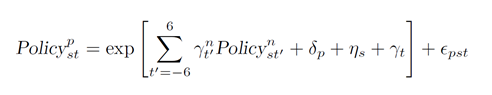
其中,核心解释变量的含义是,城市c所在省份p以及国家n在t年是否有针对s产业的政策,窗口期设定为前6年到后6年。回归结果如图所示:
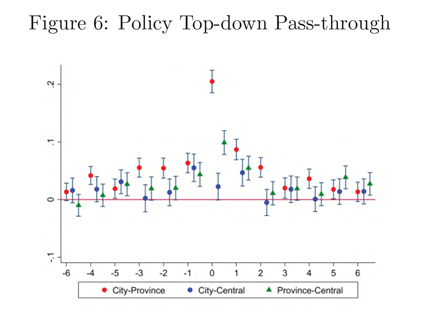
(同年相关性最强,序列相关性较弱)
(经济发达城市的自主权更大)
事实1c(详见原文):2013年以来,自上而下的政策传递方式再度兴起。
事实1d(详见原文):目标产业的选择是持久的,地方官员的调动会促进目标产业的转变。
(二)政策工具的区域和产业差异以及动态演变
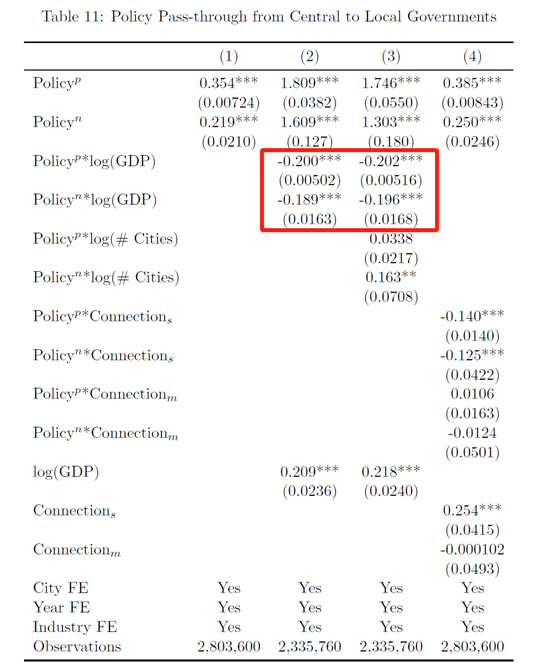
事实2a:地方政府是新政策工具的早期使用者,中央政府较多依赖传统政策工具,省级政府则介于二者之间。
计量模型与变量构造:
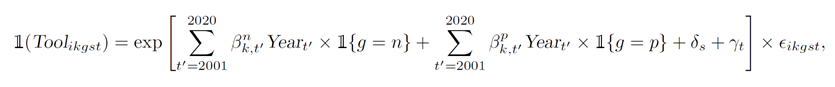
其中:Tool为使用某一种政策工具的虚拟变量,i为产业政策、k为工具类型、g为政府层级(n为国家,p为省级)、s为产业、t为年份;Year也为虚拟变量,1{g=n}和1{g=p}分别代表是否国家政策和是否省级政策。具体而言,k包括五类,即前文提及的新兴工具(快速增长型、适度增长型)和传统工具(强劲型、稳定型、式微型)。【更正:计量模型中残差项之前的符号应为“+”】
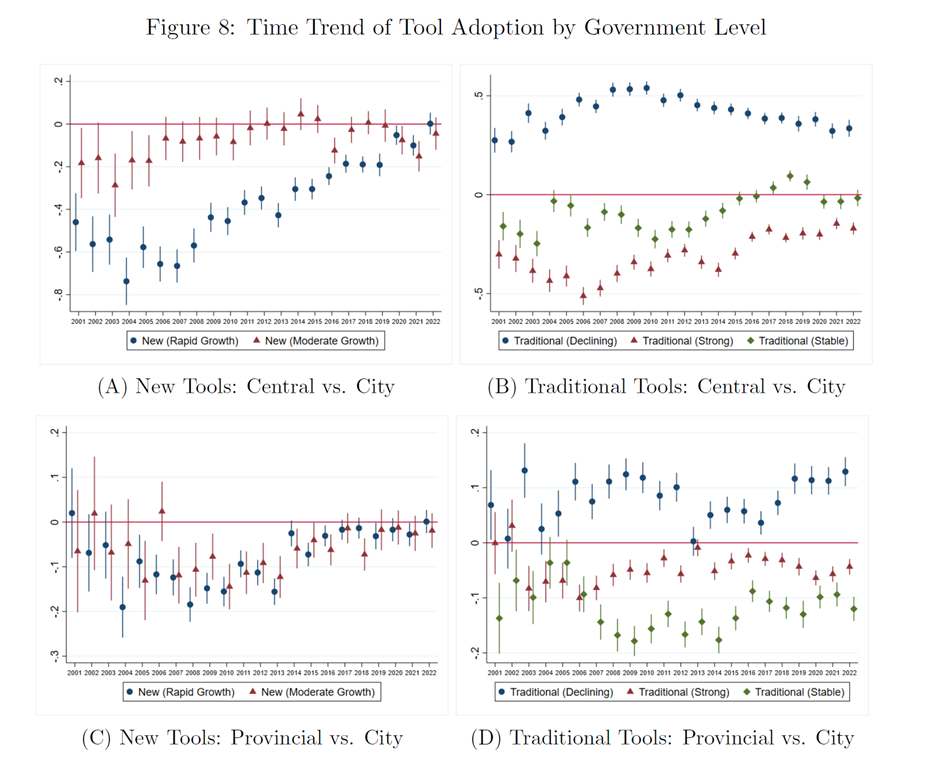
由(A)和(C)图可知,市级政府往往是新工具的早期采用者,其次是省级政府。而(B)和(D)图告诉我们,中央政府更倾向于使用传统工具,其次是省级政府。总体来看,地方政府在尝试新工具方面更具探索精神,且随着时间的推移,各级政府都在越来越多地采用新工具。
事实2b(详见原文):较发达地区会较早采用新的政策工具,新工具逐渐向欠发达地区扩散。较发达地区一直是财政成本较高工具的使用者。
事实2c(详见原文):政策工具的选择因目标产业而异。
事实2d(详见原文):对于一个特定产业,政策工具的选择会随着时间的推移而变化。
事实2e(详见原文):对于一个特定产业,政策实施的组织安排也会随着时间的推移而变化。
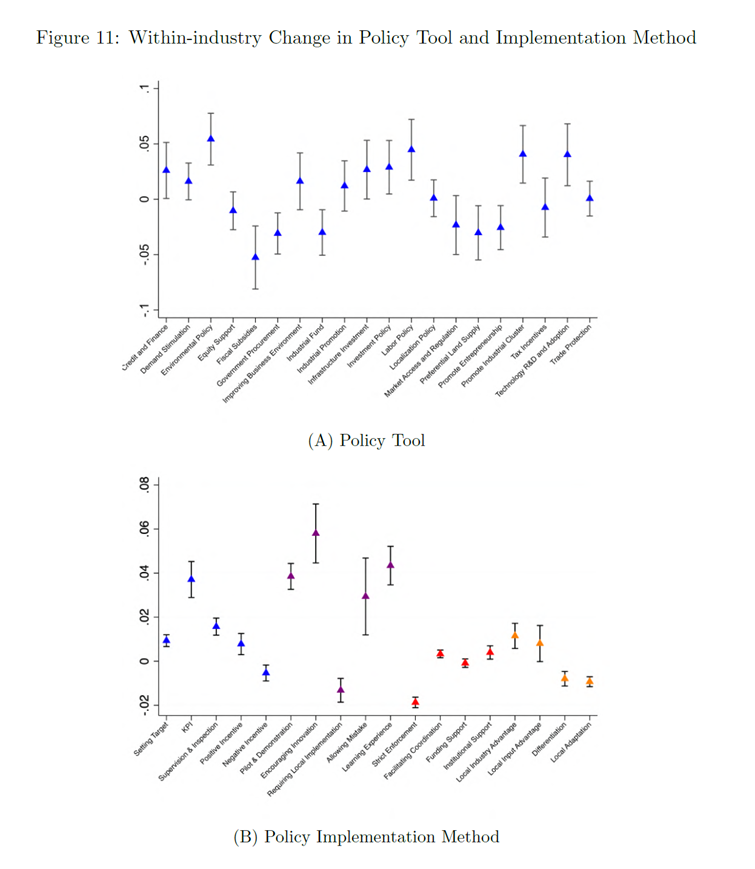
(系数越大意味着使用某种工具或方法的概率更高)
(三)产业政策的空间扩散与潜在低效
事实3a:区域间产业政策的相似性与地方保护主义呈正相关。
产业政策相似性如何测度:对每个城市构建一个由0-1指标组成的产业政策向量,即各个产业是否得到政策支持,然后在同一省份内部计算“城市对”产业政策向量的余弦相似度,最后再计算某一城市与省内其他城市(n-1个)余弦相似度的平均值。
地方保护如何测度:利用增值税发票数据库,将企业之间的交易信息汇总到城市层面,如果企业属于一个城市就是城市内贸易,如果涉及省内不同城市的企业,就是省内城市间贸易。本文以城市内贸易总额与全市贸易总额(或省内贸易总额)的比例来衡量地方保护程度。
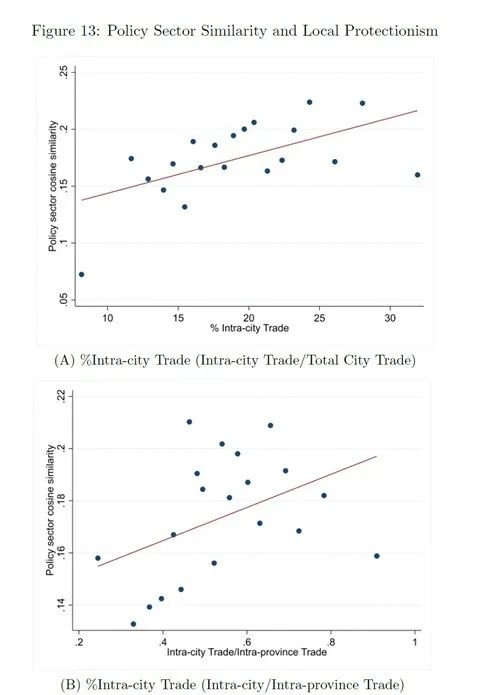
事实3b:政策跨地区扩散会降低有效性。
计量模型与变量构造:
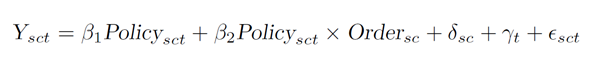
其中:Y是经济变量(包括新进入企业的数量、新注册资本总量和平均值等),Order为城市c的产业s第一次引入产业政策的时间(本文将数据标准化处理,该变量越大表示引入时间越晚)。
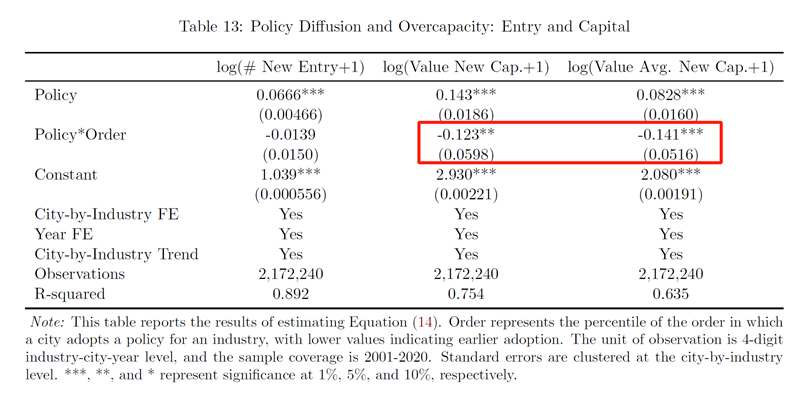
(追随者城市只能吸引规模较小企业)
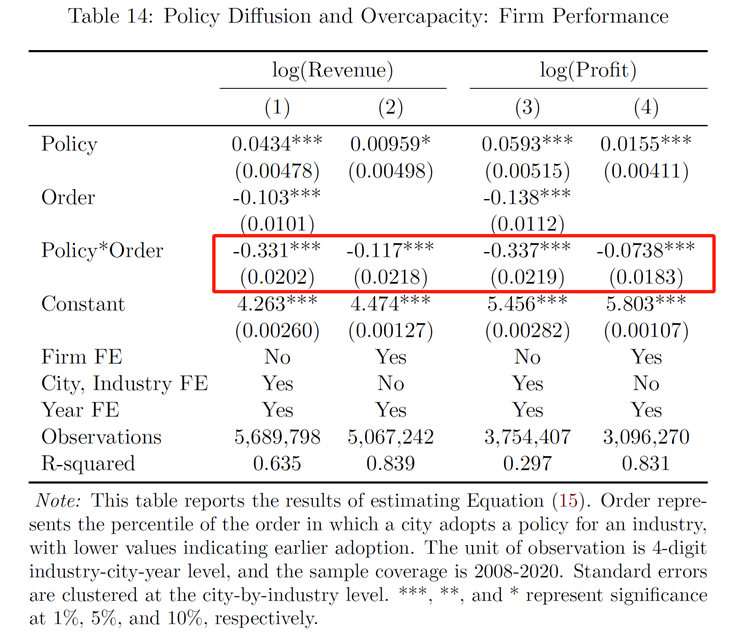
(企业层面的回归发现,追随者城市的企业收入和利润均更低)
事实3c(详见原文):在政策的跨地区扩散过程中,追随者在选择目标行业、政策工具和实施方法等方面缺乏现实考量(例如忽视比较优势,传统工具较多,以及对政策实施的包容性降低等)。
(四)产业政策对企业绩效的影响
事实4a(详见原文):支持性产业政策在降低税率、提供补贴和增加企业借贷渠道等方面是有效的,但是对不同规模的企业存在异质性影响。
事实4b(详见原文):支持性产业政策会增加新企业进入,其效果取决于不同的政策工具。
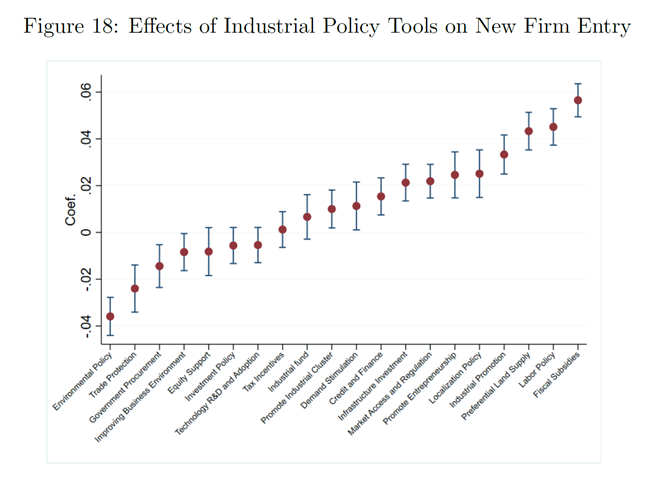
(财政补贴、劳动力政策、优惠土地供应等效果较好)
事实4c(详见原文):支持性产业政策会提升企业生产率,其效果取决于不同的政策工具。
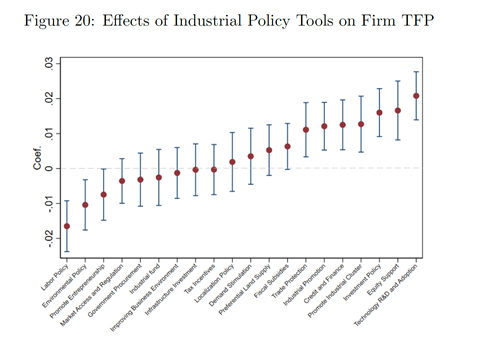
(技术研发、投资支持、促进形成产业集群等效果较好)
05
研究展望
本文最后,作者提出两点研究展望:第一,不同产业政策工具的异质性还需要深入讨论,可以通过结构模型来精准识别这些政策共同影响企业行为的作用机制,例如分析驱动生产率增长的不同政策的相对重要性就是一个很有前景的研究方向;第二,企业并购与破产对于化解中国的产能过剩至关重要,而探究阻碍这一进程的政治—经济壁垒也是未来的研究方向。
产业政策:Don’t Ask Why, Ask How!
抓好“十四五”圆满收官、做好“十五五”谋篇布局,是当前的一件大事。自1953年开始,14个历史单元串联起新中国波澜壮阔的发展进程,形成了“中国之治”的一个重要政治优势。展望未来五年的发展环境,一方面是逆全球化抬头、贸易摩擦频发,另一方面是人工智能等新兴技术成为国际竞争新焦点和经济发展新引擎。基于此,我们的产业政策必然会因时而变、随事而制!
Abstract
We decode China’s industrial policies from 2000 to 2022 by employing large language models (LLMs) to extract and analyze rich information from a comprehensive dataset of 3 million documents issued by central, provincial, and municipal governments. Through careful prompt engineering, multistage extraction and refinement, and rigorous verification, we use LLMs to classify the industrial policy documents and extract structured information on policy objectives, targeted industries, policy tones (supportive or regulatory/suppressive), policy tools, implementation mechanisms, and intergovernmental relationships, etc. Combining these newly constructed industrial policy data with micro-level firm data, we document four sets of facts about China's industrial policy that explore the following questions: What are the economic and political foundations of the targeted industries? What policy tools are deployed? How do policy tools vary across different levels of government and regions, as well as over the phases of an industry's development? What are the impacts of these policies on firm behavior, including entry, production, and productivity growth? We also explore the political economy of industrial policy, focusing on top-down transmission mechanisms, policy persistence, and policy diffusion across regions. Finally, we document spatial inefficiencies and industry-wide overcapacity as potential downsides of industrial policies.
推文作者:王奕,南开大学经济学院,政治经济学专业博士研究生
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}