阅读:0
听报道
推文人 | 冯显骏
原文信息:Andrew J Tiffin. (2010). Machine Learningand Causality: The Impact of Financial Crises on Growth. IMF Working Paper No.19/228.
——用机器学习方法估计金融危机的负面效应
凭借其强大的预测能力,机器学习方法近年在各个学科、各个行业得到广泛应用。但在实证经济学领域,由于经济学家更注重政策的“因果效应”而非模型的预测能力,机器学习方法并未成为主流。尽管如此,大量尝试使用机器学习进行因果推断研究的论文正在快速涌现。本文是一篇IMF工作论文,作者首先普及了以预测能力为目标的机器学习与以估计因果效应的实证经济学之间的区别与联系;其次介绍了一个将机器学习经典的随机森林算法应用于因果推断后形成的新算法(Causal Forest algorithm),并给出了这一算法的一个应用案例;最后对这一算法的可能应用领域进行讨论并总结全篇。
机器学习与因果推断的区别与联系
实证经济学因果推断所探究的问题是“如果某事件发生,结果会有什么变化”,它的核心在于反事实情形的构建。因果推断关心的是一个事件发生或不发生对我们关心的个体的影响,比如一个人上大学相比不上大学,他的收入能提高多少。因果推断的难题在于“历史无法重演”,如果我们有时光机器,就可以在这个人高中毕业后先让他直接去工作,记录他的收入,然后用时光机器送他穿越回高中毕业的时间点,让他完成大学学业后再去工作,并记录他的收入。这样,两个收入的差就是上大学对他收入的影响。然而,我们无法操控时间,并且经济学所讨论的绝大多数话题也无法进行随机实验(我们不可能随机指定一些高中生去上大学,而不让其他高中生去)。因此,实证经济学者们必须绞尽脑汁,利用给定的观测数据人工构造出一个对照组(比如用没上过大学的人作为大学毕业生的对照组)。
机器学习所探究的问题是“如果一切按部就班地进行,结果会是怎样”,它的核心在于模型样本外预测能力。机器学习关心的是给定个体特征的前提下,预测个体的结果,比如给定一个人的学历、行业等因素,我们多大把握能猜出他的收入。机器学习的难题在于如何提升模型在新数据上的适应能力,防止过拟合情况的出现。因此,我们要权衡模型在样本内的拟合能力与模型复杂度。一些机器学习模型比如随机森林,就具有筛选自变量的能力,能够有效控制模型复杂度。
当前一些经济学家正在尝试将机器学习方法引入到实证研究中。很多估计因果效应的研究具有多个步骤,而其中某些步骤是单纯的预测问题。比如在工具变量方法中,一阶段回归就是一个简单的预测问题,可以使用LASSO回归的方法来进行工具变量选择。再比如,一些经济学家使用机器学习模型来估计样本的倾向得分,为使用倾向得分匹配方法做准备。
用随机森林进行因果推断:算法
因果森林算法(Causal Forest)是机器学习中经典的随机森林算法在因果推断中的应用。它们都是由基本的决策树模型集合而成。经典的决策树模型是不断根据自变量把样本进行“分组”,以使得不同组样本之间的因变量差异最大。最终,同一分组内全部样本因变量的平均值就是这些样本的预测值。因果森林算法中的决策树的不同在于,它使得每个组中都有实验组个体与对照组个体,因此每个分组都构成了一个人为构造的实验,都可以计算出一个处理效应。组内的个体要尽可能相似,而不同组之间的处理效应的差异要尽可能大。最终,组内个体的平均处理效应就是该组个体的处理效应的预测值。
用随机森林进行因果推断:案例
作者将因果森林算法应用于评估金融危机对一个国家经济增长的影响。案例中的处理变量为发生金融危机,结果变量为危机后两年的累积经济增长。作者构建的数据集包含46个变量,囊括了107个国家在1985年至2017年的实体经济、进出口、财政、金融等方面的特征。根据模型预测结果,作者计算了每个国家金融危机的潜在损失。这一损失不考虑每个国家发生金融危机的概率,而是一种国家经济脆弱性的衡量,代表假如一国发生金融危机,会拖累GDP增速多少个百分点。一些代表性国家的结果如下图所示。
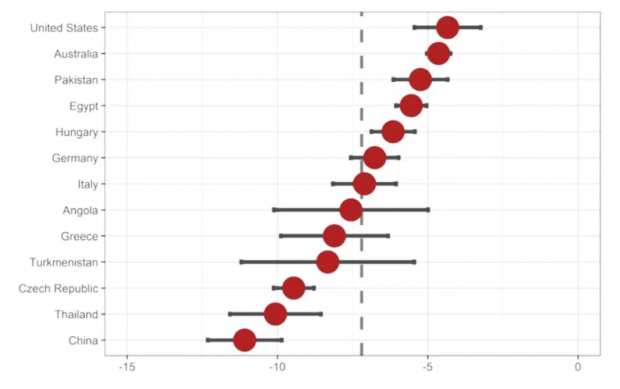
样本中所有国家效应的平均值为7.2%,即金融危机平均而言会拖累国家未来两年累积GDP增速7.2个百分点。这一结论与之前的研究相吻合。值得注意的是,根据作者的计算结果,中国经济的脆弱性较高,金融危机的潜在负面影响达到了11.1%,远大于平均水平。作者还使用了shapley value方法,将效应进行归因分解,其中中国的分解结果如下图所示。我们发现,相对于平均水平,中国由于具有更高的制造业比例、更高的经济增速、更大的对外贸易规模以及更低的通胀波动水平,因此具有更大的负面效应。
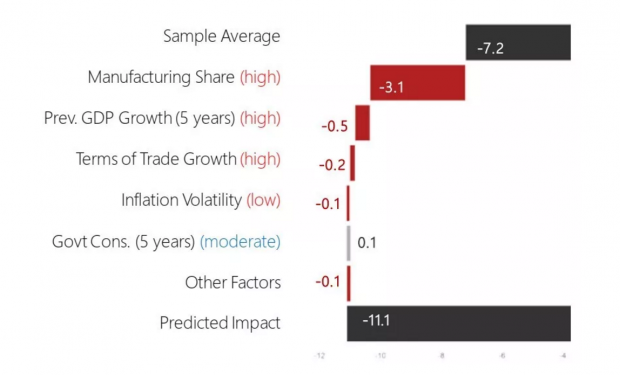
为了改进传统机器学习模型类似于黑箱的不可解释性,作者在文章中详细讨论了不同因素对总效应的贡献,以及不同变量之间的交互效应,对细节感兴趣的读者可以直接阅读原文。此外,作者使用的可视化技术也非常值得我们参考。
结论与展望
因果随机森林算法不仅能用于评估金融危机的影响,还可以应用于各种宏观与微观经济数据集,如劳动市场改革,税收制度改革等等。同时,它也可以扩展到处理变量为连续变量的情形,并能与工具变量的方法相结合,处理内生性问题。
本文给出了一个将机器学习应用于实证经济学因果推断的示范性案例。作者使用机器学习估计出的金融危机对经济增长的负面效应与前人通过传统计量经济学方法得出的效应相一致。同时,作者发现外汇制度与金融发展程度是影响这一效应的关键因素。相对传统计量经济学方法,机器学习方法在讨论交互效应、非线性效应、异质性效应上更具优势。因此,这一方法值得得到实证经济学者的更多关注。
Abstract
Machine learning tools are well known for their success in prediction. But prediction is not causation, and causal discovery is at the core of most questions concerning economic policy. Recently, however, the literature has focused more on issues of causality. This paper gently introduces some leading work in this area, using a concrete example—assessing the impact of a hypothetical banking crisis on a country’s growth. By enabling consideration of a rich set of potential nonlinearities, and by allowing individually-tailored policy assessments, machine learning can provide an invaluable complement to the skill set of economists within the Fund and beyond.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}