阅读:0
听报道
推文人 | 吴进进
推文信息:Jacob Abernethy ., (2016). Flint Water Crisis: Data-Driven Risk Assessment Via Residential Water Testing.
一、弗林特铅水危机事件
半个多世纪以来,美国密歇根州弗林特市的饮用水一直由底特律供排水部(DWSD)统一提供和处理,弗林特每年需要向他们支付一笔高昂的费用。2013年弗林特市陷入财政危机,市议会为了节省供水成本,决定将淡水供应商更换为Karegnondi Water Authority,其水源为“五大湖”之一的休伦湖。随后,DWSD决定在2014年4月终止向弗林特市供水。然而从休伦湖取水的供水管道还要两年多才能修建完成,在这期间弗林特市只能暂时把弗林特河(Flint River)作为临时水源。但是没过多久,很多弗林特市民就发现家里的自来水变成了黄褐色,还伴随着刺激性的味道。紧接着,很多人出现了掉发、皮疹和过敏反应。在此后长达一年多的时间里,弗林特市政府和密歇根州政府一直对市民对水质污染的抱怨和投诉置若罔闻、百般推脱,一再声称水质符合标准。但是事后检测表明,弗林特河河水曾长期承接工业化学废水,具有非常高的腐蚀性,对铜和铅管等金属的腐蚀性比休伦湖的水要整整高出19倍。历史上弗林特市有很多铅制水管,弗林特河河水腐蚀了弗林特市老旧的自来水管,铅因此进入自来水系统形成严重铅污染。尽管认识到问题的弗林特市政府从2015年10月份重新和底特律水务局签署了一年1200万美元的供水合同。但是,由于自来水管已经遭到不可比转的侵蚀,即使水源本身没有问题,但流过水管之后仍然会有大量的铅进入。
2015年底,弗林特市不得不启动城市自来水管更换计划(Fast Start项目),每更换一户水管的成本高达5000美元。由于时间和经费的紧张,必须尽快找出那些最有可能有铅制水管的住户。由于没有人知道铅管的确切位置,如果要对所有房屋水管进行挖掘检查的话,就意味着大量的时间、工程量和经费被浪费。另外,除了铅管线路外,很多其他因素也可能是这次铅污染的成因。为了找到解决问题的办法,Fast Start项目联合密歇根大学弗林特校区的一些专家开发了若干机器学习模型,用于预测铅制水管的位置和导致铅污染的关键因素,从而有针对性的采取水管更换和其他治理措施。本推文的原文作者就来自于密歇根大学机器学习项目团队,相信此文对机器学习在公共危机治理和城市公共决策的运用具有一定的借鉴意义。
二、机器学习模型的数据来源
构建机器学习算法模型的前提是需要作一套为训练集和测试集的数据集,即城市住户自来水铅污染样本。然而,该城市房屋建设以及住户水管构造信息十分不完善,缺乏现成的完整的数据。为了获取数据库,FAST Star 项目多方搜集数据,最终得到的数据集来自以下几个途径:
第一块数据集是居民自愿送检的水质数据(Residential Lead Tests data)。2015年底,费林特市允许居民自愿送检自家饮水样本,获得了25000份数据,根据这一样本可以检测住户家庭饮用水是否出现铅污染。但这个数据集是高度偏差的,因为送检的水大部分是有铅污的,这样的样本会使模型预测高估污染概率。
第二块数据集是当地水务部门保存的超过14万份手写的水管工程记录旧卡片(Service Line data)和55893个房屋建设信息数据(Parcel data)。这两类数据包含了房屋年龄、地址、价值、水管材质等信息。但是这一数据集质量也很差,如Service Line data中大量水管材质信息遗失或者模棱两可。作者把房屋建设数据和送检的水质铅污染样本进行匹配,但是由于很多空房子住户没有送检,部分房屋数据无法与水质数据匹配。
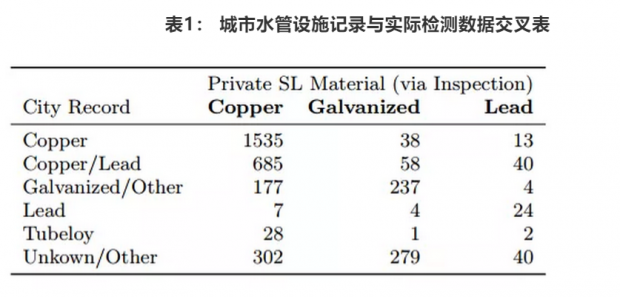
第三块数据来自2016年初步的水管监测、替换所产生的水管数据集。在2016年2月,密歇根大学团队的Martin Kaufman利用水管工程记录信息建立了部分铅制管道的标示地图。研究团队决定利用这些地图,再基于房屋建筑年限和环境质量局对水污染的粗略估计,从而初步确定水管开挖的先后次序。由于年幼的、年老的和免疫系统较差的人群受铅污染影响最严重,因此他们同时也优先考虑开挖家中有5岁以下小孩和70岁以上老人的房屋水管。本文作者把Service Line 的卡片数据和实际监测和替换的数据进行比对,验证Service Line data的准确率,他们发现部门记录的数据并不准确,一部分铅管被记录为铜管(表1)。
最后一块数据是城市消防栓数据。城市水设施年龄和水污染存在很大的相关性,而水设施年龄和消防栓年龄也是高度相关的,因此研究者搜集了城市消防栓的材质和年龄作为地下自来水设施年龄的替代指标。
三、机器学习模型构造
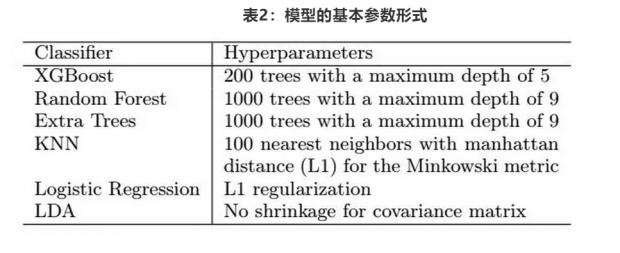
利用上述数据集,作者构建了多个机器学习模型,用以预测住户水质铅含量是否超过官方规定的最高含量(15ppb)。机器学习模型包含两个阶段,第一阶段的模型包括集成算法模型XGBoost、随机森林Random forest、极端随机树,logistic回归、KNN近邻,以及线性判别(LDA)模型。第二阶段的模型只有一个独立的集成XGBoost模型。数据集中有35个特征变量用于建模,这些因素也都是铅污染的风险因素,其中响应变量(标签)是水的铅含量是否高于15ppb的二分虚拟变量(Lead(ppb))。上述模型除了XGBoost外,都由python的专门的机器学习模块scikit-learn 程序构造。模型的每个参数都经过50折交叉验证来确定,从而保证了模型的对数损失值(LogLoss)最小化。经过调整,上述模型的基本参数如下表所示,如随机森林模型由1000个深度最高为9层的决策树构成,而logistic模型则是L1正则logistic模型。上述模型经过第一阶段构造后,其预测结果又经过第二阶段集成模型XGBoost处理,形成最终的预测模型。
四、比较机器学习模型的预测效果
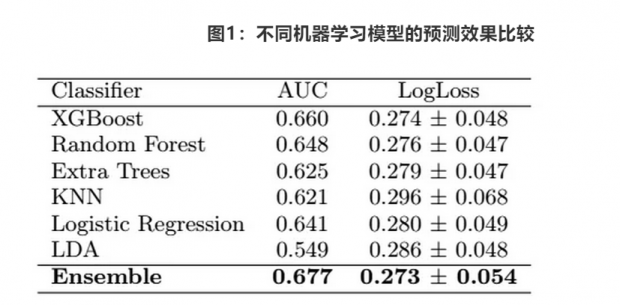
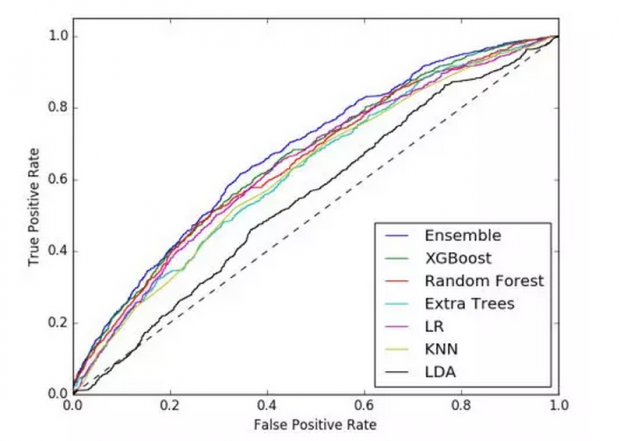
第一阶段各个模型预测结果和第二阶段的最终集成模型效果的AUC值和对数损失LogLoss值在表3中展示。在所有分类器模型中,最终的集成模型效果最好,表现为AUC值最大、LogLoss值最小,而且集成模型的正确分类率(True Positive Rate)也是所有模型中最高的(如图1右侧的ROC曲线所示,集成模型的ROC值最大)。
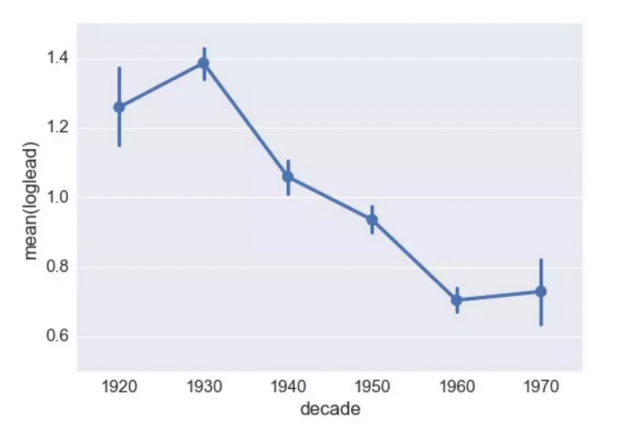
接下来,作者比较了各个预测因子的预测力,比较上述三十几个因素中哪些因素对自来水铅污染的预测力最强。通过识别这些关键的高风险因素,市政部门可以基于这些风险因素预测哪些房屋自来水最有可能存在铅污染,从而更有效率地采取更换水管等治理措施。弗林特水污染事件的主要原因就是铅制水管受腐蚀后所释放的金属铅。因此,铅管应该是铅污染的主要风险因素。如下图所示,铅制水管家庭的自来水铅污染水平是所有材质水管中最高之一,远高于铜制和其他未知材质的混合水管。除水管材质外,房屋年龄也是铅污染的重要预测因素,20世纪30年代前建造的房屋平均铅含量很高, 30年代到60年代建设的住房自来水铅含量显著降低,60年代以后铅含量又开始增加。

五、不同预测模型中的风险因素
在不同机器学习模型中,不同的因素有着不同的预测力。在第一阶段的XGBoost模型中,可以识别10个影响力最强的预测因子,通过在模型中逐个拿掉一个预测因子,看看AUC值下降的情况,从而识别哪个预测因素预测力最大。结果发现,预测力最强的预测因素依次为:经度(Longitude)、房屋土地编码(PID)、水管材质(SL Type)、房屋用途(Owner Type)(居家、商业用途、工业用途)、房屋邮政编码(Property Zip Code)、房产所处的投票地(PRECINCT)、房产的州政府估值(HomeSEV)、消防栓材质(Hydrant Type)、第二条水管线材质(SL Type2)、住房翻新价值(Land Improvements Value)。
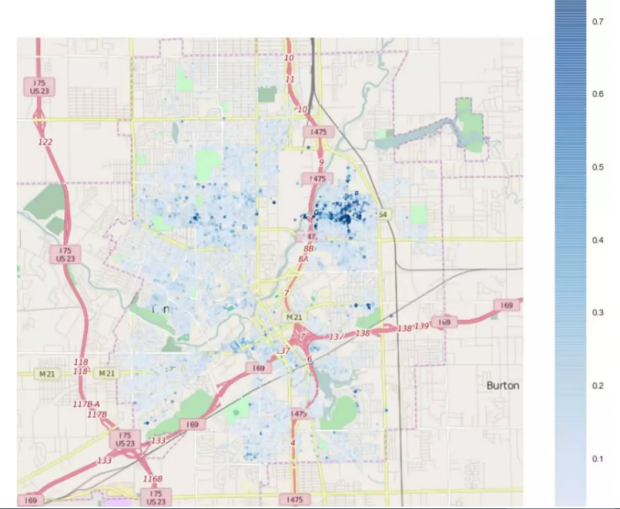
首先,在前十大风险因素中,房屋土地编码和房屋邮政编码高度相关,都是地理位置因素,这也说明地理位置是铅污染最重要的预测因素之一,某些位置是铅污染的热点区域。其次,房产特征,如房屋价值是铅污染的另一个重要预测因素,这可能是因为房产价值较低的老房子高度聚焦,而这些房子的铅制水管较多,因此出现铅污染的可能性也较大。再次,水管材质也是重要的风险因素,但是作者也发现很多没有铅制水管的家庭也检测出了铅污染,这可能是因为市政水管主管道的铅污染传递到房屋水管。作者最后利用上述机器学习模型预测了那些样本之外区域的铅污染风险,铅污染区域可视化图表明,铅污染呈现明显的聚类特征,呈现块状分布(如下图所示,蓝色越深表示铅污染可能性越大)。
六、结语
作者在文中一再强调,该机器学习模型仅用于预测铅污染的关键风险因素,并不涉及,也无法确定各因素与铅污染之间的因果关系。尽管机器学期模型有此局限,但是在公共政策决策和公共风险治理上,预测能力强大的机器学习模型仍然具有很大的运用空间。本文所述的机器学习模型对成功识别弗林特市饮用水铅污染区域和铅管房屋的准确率很高,能够有效帮助城市政府确定水管更换和污染治理的先后次序,从而在时间和经费约束下最有效地治理铅污染,避免污染损失进一步加剧。到2017年年底,密歇根大学团队开发的机器学习模型预测正确率达到了80%以上,随着样本数的增多并被补充进数据集,预测模型最终达到了94%的准确率。相比盲目的挖掘寻找铅管,基于机器学习的预算挖掘铅管可以节省约1000万美元的成本,相当于多保护了2000户房屋免受铅污染的毒害。
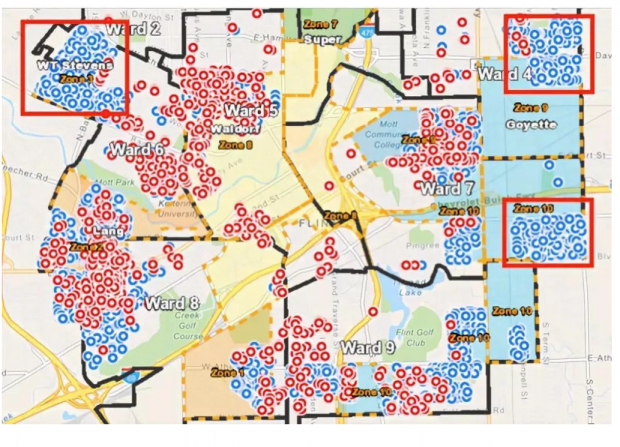
但是,在2017年年底,弗林特市终止了和密歇根大学团队的合作,把城市铅管更换工作转包给了AECOM公司。AECOM接管后就废止了密歇根大学的机器学习预测模型,他们的做法是在弗林特市每个街区都选择数百个住房开挖搜寻和更换水管,但是这样的做法是低效的,开挖后发现铅管的准确率从2017年的80%降低到20%,2018年有8046个房屋水管被挖掘,但只有1036个实际上是铅管。忽视机器学习模型的预测结果而茫无头绪地到处开挖不仅增加了工作量、浪费了经费,而且使得本来可以及时更换铅制水管的家庭不得不继续遭受铅污染的毒害。如2018年管道挖掘活动的地图所示,没有铅污染风险的铜管显示为蓝色,污染性的铅或不锈钢管为红色(机器学习算法预测区域)。在框出的三个区域内,AECOM公司挖掘了大量的房屋,却几乎没有发现铅管。据估计,该市有18000个铅制水管,目前还有约12000户家庭仍然受到铅污染的威胁。
附录:
最后,随文附上机器学习模型学习和R/Python的若干教材书籍,供有兴趣的朋友学习:
1. AshishSingh Bhatia, Yu-Wei, Chiu (David Chiu). Machine Learning with R. Cookbook. 此书完整的介绍了用R构建主要机器学习模型的代码和简略原理。
2. Brett Lantz. Machine Learning with R. Packt Publishing.
3. 统计学习导论:基于R应用,加雷斯·詹姆斯、丹妮拉·威滕、特雷弗·哈斯帖 著;王星 译 / 机械工业出版社。
4.机器学习实战(Machine learning in action)/(美)Peter Harrington著;李锐[等]译.北京:人民邮电出版社,2013.(基于python的机器学习教材)
5.视频学习资源,个人推荐
前两本英文书的电子版,有需要者可联系推文作者(微信号:washwujj)。
Abstract
Recovery from the Flint Water Crisis has been hindered by uncertainty in both the water testing process and the causes of contamination. In this work, we develop an ensemble of predictive models to assess the risk of lead contamination in individual homes and neighborhoods. To train these models, we utilize a wide range of data sources, including voluntary residential water tests, historical records, and city infrastructure data. Additionally, we use our models to identify the most prominent factors that contribute to a high risk of lead contamination. In this analysis, we find that lead service lines are not the only factor that is predictive of the risk of lead contamination of water. These results could be used to guide the long-term recovery efforts in Flint, minimize the immediate damages, and improve resource-allocation decisions for similar water infrastructure crises.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}