阅读:0
听报道
推文人 | 张亦达
原文信息:
Ernesto Dal Bó, Pedro Dal Bó, Erik Eyster. The Demand for Bad Policy when Voters Underappreciate Equilibrium Effects[J] Review of Economic Studies, 2018, 85(2):964–998.
01 引言
毫不奇怪,大多数政治经济学文献将坏政策归咎于制度、特殊利益或政客的能力和动机。事实上,选民本身也要为此负责。Dal Bó et al. (2018) 通过行为经济学实验提供了一种解释:选民关于政策变化均衡效应的错误估计是引发坏政策的重要原因。那些产生直接收益但造成更高间接成本的政策得到拥护,而带来直接成本但创造更高间接收益的政策遭到反对。文章分别以囚徒困境(Prisoners’ Dilemma-PD)与和谐博弈(Harmony Game-HG)模拟坏政策和好政策,发现实验参与者关于对手行动的错误信念导致他们固守PD而拒绝向HG转换,或投票要求从HG转向PD。
02 理论
2.1两个博弈与政策优劣
考虑一个双人完全信息博弈,参与者只有合作(C)或背叛(D)两个策略,相应的净收益如表1左侧所示。给定b>c>0,(D, D)为该囚徒困境博弈的纳什均衡,净收益为(0, 0)。然后假定参与者行动空间不变,对合作行为征税tC,对背叛行为征税tD,并满足b>tD>tC+c。如表1右侧所示,此时合作成为理性参与人的占优策略,并形成纳什均衡(C, C),相应的净收益为(b-c-tC, b-c-tC),b-c-tC>0。我们称这个新的博弈为和谐博弈。显然,和谐博弈是比囚徒困境更好的政策。然而,我们并不能由此推断参与人一定支持好政策、摒弃坏政策,因为参与人未必足够理性。
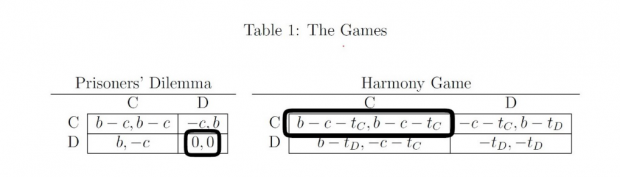
2.2两个博弈的转换
假定参与人关于自身在囚徒困境与和谐博弈中选择合作(概率)的信念为α、α`,关于对手在囚徒困境与和谐游戏中选择合作(概率)的信念为β和β`,则他从囚徒困境转向和谐博弈的净期望收益为:
G(α, α`, β, β`) = EU(HG|α`, β`) − EU(PD|α, β)
该式可以分解为三部分,即:
(1) DE = EU(HG|α, β) − EU(PD|α, β) = − (αtC + (1 − α)tD)
(2) IS = EU(HG|α`, β) − EU(HG|α, β)= (α` − α)(tD − c − tC )
(3) IO = EU(HG|α`, β`) − EU(HG|α`, β) = (β` − β)b
其中DE表示直接效应(Direct Effect),即假定博弈参与人行为不受博弈改变的影响。IS表示参与者只调整自身在和谐博弈中的合作信念(Indirect Effect by Self)而带来的收益变化。IO表示进一步考虑对手在和谐博弈中合作概率变化(Indirect Effect form Others)带来的净收益。当且仅当三式之和小于0时,参与人才会更偏好囚徒困境,即:
G = DE + IS + IO = − (αtC + (1 − α)tD) + (α` − α)(tD − c − tC ) + (β` − β)b < 0
转换为:
β` − β < αtC/b + (1 − α)tD/b − (α` − α)(tD − c − tC )/b
β` − β < tD/b − α`(tD − c − tC )/b − αc/b
上述不等式右侧定义了一个阙值。给定b > tD > tC + c,当α = α` = 0时,取最大值tD/b < 1;当α = α` = 1时,取最小值tC/b < 1。注意到,当参与人预期纳什均衡成立时,β` − β = 1,他不可能偏好囚徒困境。但当β` − β < tC/b时,参与者一定偏好囚徒困境。换言之,只要参与者关于对手合作信念的错误估计程度足够大(从而偏离纳什均衡更远,β` − β足够小),他一定偏好囚徒困境。尽管上述推理是就PD向HG转换而言,反过来也适用于HG向PD的转换,只不过后者施加的条件是补贴而非征税。
03 实验
3.1实验设置
为便于开展实验,作者们对一系列参数进行了赋值,令b = 6, c = 2, tC = 1, tD = 4,满足条件b > tD > tC + c,同时令受试的初始禀赋为5(类似于出场费),具体如表2所示。这些博弈收益点数可以在博弈结束后以3:1的比例兑换美元。

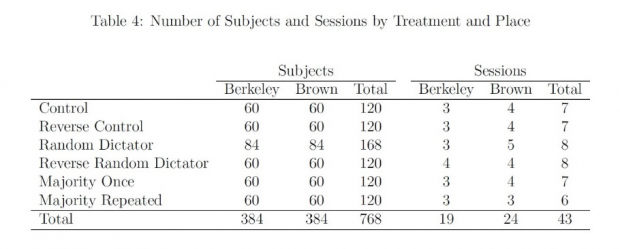
实验进行了43次,共包括384名UC伯克利的学生和384名布朗大学的学生。每次实验均分成两期(Part1和Part2),两期实验都将受试随机分成6人一组,每个受试都与组内其他人只进行一次博弈,即每期实验均开展5轮,两期共计10轮。如此可以避免重复博弈带来的声誉影响。在实验中,合作和背叛被称为行动1和行动2,以确保中性。一部分实验从PD开始,另一部分从HG开始,我们以前者为例说明实验过程。在第1期,受试与组内5个不同的对手依次进行博弈(共5轮),博弈前向受试说明博弈规则和表2左侧所示收益矩阵,每轮博弈后由计算机展示受试和对手的行动和收益。在第2期,受试依然被随机编成6人一组,并与组内5个不同对手进行博弈(共5轮),但在此之前,由不同机制决定是否按照新博弈(表2右侧所示)进行博弈,这里的机制与下文的分类处理有关。机制实施之后、决定生效之前,受试汇报他们关于对手在接下来博弈中(老博弈或新博弈)选择合作的概率估计β和β`。Part2结束后受试兑现两期博弈的收益。
3.2分类处理
按照第1期实验始于囚徒困境抑或和谐博弈,以及第2期进行何种博弈的机制,作者将实验处理分为6类。标记为Control(控制)、Random Dictator(随机独裁)、Majority Once(单次简单多数)和Majority Repeated(重复简单多数)的受试在第1期玩囚徒困境,标记为Reverse Control(反向控制)和Reverse Random Dictator(反向随机独裁)的受试在第1期玩和谐博弈。控制类Control和Reverse Control表示第2期进行囚徒困境博弈还是和谐博弈由电脑随机决定。控制组排除了其他人行为对第2期博弈选择的影响,便于证实和谐博弈与囚徒困境的差异是否符合理论预期。Random Dictator和Reverse Random Dictator表示每个受试都要就第2期进行囚徒困境博弈还是和谐博弈进行投票,然后随机选择某个受试的投票结果作为最终决定。Majority Once表示第2期的博弈类型取决于大多数人(超过50%)的投票,且该决定应用于整个第2期6-10轮博弈。Majority Repeated表示第2期(6-10轮)每轮博弈都按照简单多数原则重新确定博弈类型,用于考察重复投票的学习效应。
表3总结了处理分类。
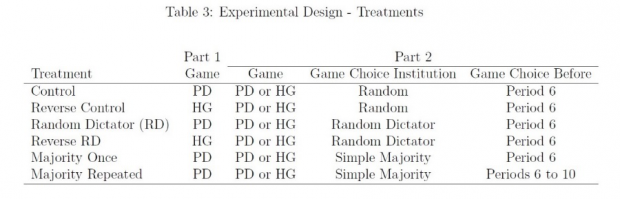
表4总结了样本分布,需要说明的是,每次实验仅使用一个分类。
04 实证
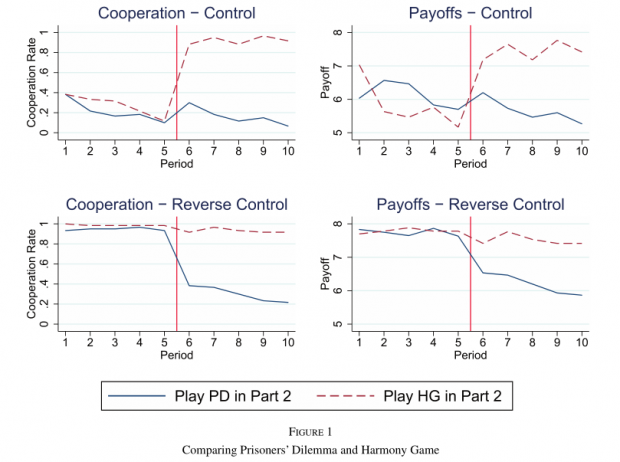
4.1和谐博弈带来更高的回报
Control和Reverse Control下,第2期进行何种博弈是外生随机决定的,足以反映和谐博弈与囚徒困境的差异。如图1所示,在第2期的全部5轮博弈中,受试在和谐游戏中的合作概率显著高于其在囚徒困境中的合作概率,同时在和谐博弈中获得了更高的收益。这种模式在第6轮中已经显现。
4.2低估均衡与坏政策需求
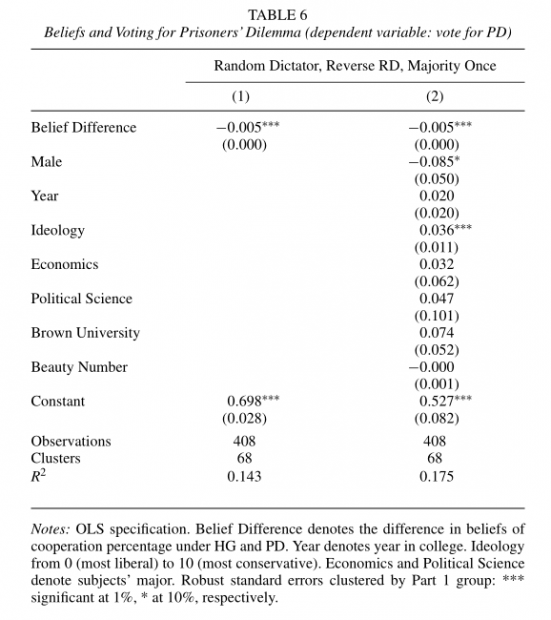
在Random Dictator、Reverse Random Dictator和Majority Once三个处理分类中,每个受试都要通过投票决定在第2期进行囚徒困境博弈还是和谐博弈,因此可以刻画他们对不同政策的态度,进而反映其对坏政策的需求。如表6所示,受试关于对手在和谐博弈和囚徒困境中合作概率的估计值差异(β` − β)与他自身投票支持囚徒困境的概率显著负相关。换言之,他关于对手均衡行为的低估程度与坏政策的需求显著正相关。人口统计学特征并不会影响这一结论。
4.3进一步分析
文章还从以下几个方面进行了深入分析。(1)通过附加实验构造工具变量,证实了低估均衡与坏政策需求的因果关系。(2)在Majority Repeated处理分类下,发现随着博弈轮次的增加,受试投票支持囚徒困境的概率明显下降。这意味着经验可以提高人们的均衡预测能力。(3)基于选美实验的研究表明,策略复杂度与投票支持囚徒困境的概率无关。(4)受试不仅会低估对手的均衡行为,还会低估政策变化对自身的影响。(5)排除了现状偏见、框架效应等其他解释。
05 结语
由于笔者能力有限,无法准确还原全文,强烈建议感兴趣的读者对照原文和实验附录反复阅读。
原文工作论文和实验附录:
链接:
提取码:511j
Abstract
Most of the political economy literature blames inefficient policies on institutions or politicians’ motives to supply bad policy, but voters may themselves be partially responsible by demanding bad policy. In this article, we posit that voters may systematically err when assessing potential changes in policy by underappreciating how new policies lead to new equilibrium behaviour. This biases voters towards policy changes that create direct benefits—welfare would rise if behaviour were held constant—even if those reforms ultimately reduce welfare because people adjust behaviour. Conversely, voters are biased against policies that impose direct costs even if they induce larger indirect benefits. Using a lab experiment, we find that a majority of subjects vote against policies that, while inflicting direct costs, would help them to overcome social dilemmas and thereby increase welfare. Subjects also support policies that, while producing direct benefits, create social dilemmas and ultimately hurt welfare. Both mistakes arise because subjects fail to fully anticipate the equilibrium effects of new policies. More precisely, we establish that subjects systematically underappreciate the extent to which policy changes will affect the behaviour of other people, and that these mistaken beliefs exert a causal effect on the demand for bad policy.
话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}