阅读:0
听报道
推文人 | 陈普
原文信息
A. Belloni, V. Chernozhukov and C. Hansen, 2014, Inference on Treatment Effects after Selection among High-Dimensional Controls, Review of Economic Studies 81(2): 608-650.
引言
利用普通回归估计因果效应,一个重要假设就是控制了其他因素后,感兴趣的变量是随机的。譬如,感兴趣政策对失业的影响,那么控制其他因素后,政策安排就要是随机的。但其他因素有很多呀,能控制得完吗?Belloni et al.(2014)以机器学习中的lasso模型为例提出了一种方法,该方法表明,你可以尽可能多地搜集变量,包括交叉项、二次项等,然后加入到模型中来,也不必担心变量个数超过样本个数,通过对这些海量自变量的某种选择,利用OLS一样可以实现对感兴趣变量的因果推断。
方法


这么做的直觉
为理解这种双重选择的重要性,作者通过将该估计量与后单一估计量(post-single-selection estimator)进行比较来获得一种直觉。所谓后单一估计量是仅仅利用下式进行变量选择,然后进行OLS:
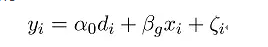
两种方法的比较涉及大量公式。但粗略地说,当通过筛选而去掉了某些自变量时,后单一选择估计量可能存在很大的偏误,而后双重选择估计量则不存在这个问题。
应用
作者最后使用他们的方法重新估计了Donohue III and Levitt(2001)的模型,发现Donohue III and Levitt(2001)的结果不再显著了。
Abstracts
We propose robust methods for inference about the effect of a treatment variable on a scalar outcome in the presence of very many regressors in a model with possibly non-Gaussian and heteroscedastic disturbances. We allow for the number of regressors to be larger than the sample size. To make informative inference feasible, we require the model to be approximately sparse; that is, we require that the effect of confounding factors can be controlled for up to a small approximation error by including a relatively small number of variables whose identities are unknown. The latter condition makes it possible to estimate the treatment effect by selecting approximately the right set of regressors. We develop a novel estimation and uniformly valid inference method for the treatment effect in this setting, called the “post-double-selection” method. The main attractive feature of our method is that it allows for imperfect selection of the controls and provides confidence intervals that are valid uniformly across a large class of models. In contrast, standard post-model selection estimators fail to provide uniform inference even in simple cases with a small, fixed number of controls. Thus, our method resolves the problem of uniform inference after model selection for a large, interesting class of models. We also present a generalization of our method to a fully heterogeneous model with a binary treatment variable. We illustrate the use of the developed methods with numerical simulations and an application that considers the effect of abortion on crime rates.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}