阅读:0
听报道
推文人 | 朱晨
原文信息:Beauchamp, J.P., Cesarini, D., Johannesson, M., van der Loos, M.J., Koellinger, P.D., Groenen, P.J., Fowler, J.H., Rosenquist, J.N., Thurik, A.R. and Christakis, N.A., 2011. Molecular Genetics and Economics. Journal of Economic Perspectives, 25(4), pp.57-82.
推文简介
本次推送将介绍一个经济学交叉研究领域:遗传经济学(Genoeconomics)。它是在传统经济学原理的基础之上,结合现代遗传学、行为遗传学、表观遗传学等科学理论,利用日益丰富的人类基因数据库,研究社会经济现象和人类社会经济行为决策的一门新兴交叉学科。遗传经济学最早诞生于2007年(Benjamin et al., 2007),这篇2011年发表在Journal of Economic Perspectives的综述性论文对其早期发展进行了整理和回顾,能够帮助读者了解如何将基因数据运用于经济学研究当中。
自2001年人类基因组测序首次完成以来,不到二十年的时间里DNA分析技术已发生翻天覆地的变化。随着新一代测序技术的出现,基因测序成本大幅降低,个人全基因组的基因测序成本从2001年的9526万美元降低到2017年的1120美元(NIH,),且仍在持续下降中(2019年有望降至500美元左右)。测序成本以超摩尔定律速度的降低大大推动了基因和遗传数据在其他领域中的应用,美国、英国、冰岛等发达国家已逐步开始在大型社会经济调查中纳入遗传物标记检验,即基因数据的采集。如英国的Biobank项目,美国的The National Longitudinal Study of Adolescent Health,The Health and Retirement Survey等。这些项目不但收集了被访者的社会经济背景信息,还包括了每个个体成百上千的遗传标记(Genetic Marker)信息,为经济学家们提供了新的研究素材。
另一方面,自上世纪60年代产生以来,行为遗传学家们用一系列证据证明了父母基因对于子女性格、认知能力、经济行为和偏好的影响。近年来,越来越多的经济行为、偏好和特征被证实具有继承性。例如风险承受的遗传性可达20-30%,金融决策的继承度在25%-60%的范围内。正是在这样测序成本持续降低以及经济行为偏好继承性研究发展的双重背景下,遗传经济学应运而生。
目前遗传经济学主要有两个研究分支。一类是在分子层面上考察人类的经济行为和特征到底是不是受基因控制?如果是,受哪些基因调控,各自的影响大小是多少?比如国外研究者这两年已经相继发现了“风险偏好基因”、 “时间折扣基因”、“生育偏好基因”、“受教育程度基因”等(Rietveld et al.,2013;Okbay et al.,2016;Barban et al.,2016;Sanchez-Roige et al., 2018;Linnér et al.,2019)。“风险偏好”和“时间折扣”都属于传统经济学概念,而这些相关基因的发现颠覆了从前学术界认为“个体的经济偏好主要由外源成长环境或随机因素决定”的单一观念,表明了一个人的经济行为与特征很多时候都同时受到内在基因与外在环境(e.g.生活环境、成长环境)的共同作用。第二类研究则是在第一类研究发现的基础上,将基因数据直接运用到计量分析中,如“身高、肥胖会不会对一个人的就业和工资有因果影响?”等(Böckerman et al., 2019;Tyrrell et al., 2016;Norton & Han, 2008)。
基因信息在经济学中的应用将能够带来以下几个好处:首先,遗传经济学可以帮助经济学家获得更精准的因果推断。随着遗传禀赋数据获得难度的降低,实证经济学家们将能够更好的在模型中将遗传因素作为因变量进行控制,从而减少遗漏偏差造成的负面影响。同时,个体的遗传数据将有助于我们理解令人困扰的各种政策的差异性影响,为个体的异质性社会经济行为特征提供新的解释。第二,遗传标记数据可以作为工具变量直接应用于存在内生性的研究中。第三,遗传经济学的研究成果有可能“反哺”遗传学。由于基因-环境交互作用(gene-environment interaction)的存在,遗传学领域的研究者们同样面临着基因-表型影响机制难以识别的问题。而经济学家们长久以来已建立了一套评估和识别因果效应的强大方法库,若与遗传数据相结合,很可能会有助于识别经济行为的内在生物学作用机理,对当前遗传学界对基因-环境交互影响机制的认识做出贡献。毕竟在所有学科当中,没有任何一个学科的学者们比经济学家更为了解人类自身的社会经济行为和决策。
研究实例:“高学历” 基因的确立
Beauchamp et al.(2011)在综述中以学业成就相关基因为例,介绍遗传经济学研究中鉴定受教育程度相关联基因的一般性步骤。
1、数据获取
论文中采用的样本来自于美国Framingham心脏研究(Framingham Heart Study,FHS)。这一研究是世界上心血管防治研究的先锋,始于1948年,至今仍在进行。第一代参与者是美国麻省Framingham镇超过三分之二的成年居民。在漫长的70年岁月中,FHS分别于1971年和2002年将第一代参与者的第二代和第三代子孙扩充到研究对象中来,为人类对于心血管疾病的认识和斗争作出了杰出贡献。在全部14,531个参与者中,8,496人进行了社会经济背景和基因信息的收集。样本基因测序采用的是Affymetrix公司500K SNP基因芯片,能够检测500,568个SNP位点。Beauchamp et al.(2011)首先对原始基因数据进行了质量控制,在个体层面筛除了499个基因数据量缺失超过5%的样本;在SNP层面依据缺失数据不超过2.5%等标准保留了363,776个符合要求的SNP位点。接下来,Beauchamp et al.(2011)采用主成分分析法(Principal Component Analysis,PCA)以控制基因数据中的人群分层(population stratification)。
2、关联分析
全基因组关联研究(Genome-Wide Association Study, GWAS)是目前最流行的基因组学研究方法之一。其原理是在全基因组层面上通过对大规模人群DNA样本进行遗传标记分型,以寻找人类复杂疾病或特征的相关遗传因素;自2005年首次发表以来已帮助人们发现并鉴定了大量与复杂性状相关联的遗传变异,同时也是当前遗传经济学分析的最主要手段。Beauchamp et al.(2011)采用以下模型对每一个符合条件的SNP位点进行回归:
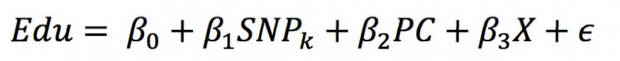
其中Edu为个体的受教育年份;SNPk是个体在第k个SNP位点拥有的次要等位基因个数(取值为0、1或2);PC是第一步中通过主成分分析得到的用于控制人群分层的主成分因子;X是一组个体的社会经济控制变量。在GWAS关联分析中,统计检验的显著性水平需要进行校正,一般采用更为严格的5×10^(-8)作为显著性水平(McCarthy et al.,2008),只有达到这些水平的SNP位点才被认为与受教育年份具有显著关联性。
3、稳健性检验
由于关联分析存在不可避免的假阳性,以上结果需要经过在独立样本中的验证才可确立SNP与学业成就的关联性。Beauchamp et al.(2011)利用鹿特丹研究(The Rotterdam Study)的数据进行了重复性检验。荷兰的鹿特丹实验在1990年/2000年/2006年分别进行了共3轮,收集了14,926个来自鹿特丹Ommoord区域的个体样本,其中9,535人提供了基因样本。在第2步中表现最为显著的前20个SNP位点被用于进行重复实验,步骤与第2步中类似。
4、结果解读
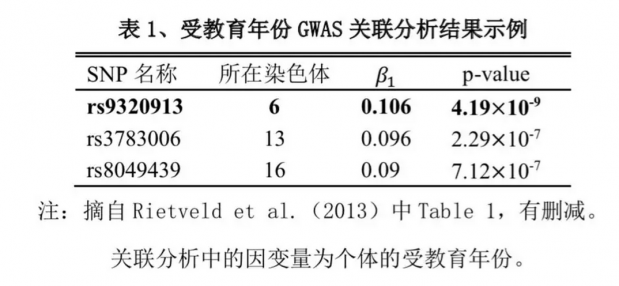
表1截取了Rietveld et al.(2013)研究中学业成就相关基因GWAS分析的部分结果作为说明。表1中第1列为SNP位点名称,即上式中SNPk;第2列是相应SNP位点所处的人类染色体编号;第3列是SNP的回归系数,即上式中β1;第4列是回归系数β1对应的p值。若以5*10^(-8)作为显著性水平界限,表1结果显示与学业成就显著相关的位点是rs9320913(p值为4.19*10^(-9))。(注:实际分析过程中还常以p值<10^(-6)作为建议相关位点的界限。表1中的rs3783006和rs8049439 SNP位点符合这一标准,可在后续分析中进一步验证。)
由于教育成就本身是一种受多基因影响的复杂行为特征,早期研究中利用小规模样本(几百-几千人)获得的关联分析结果往往容易出现在其他样本中重复失败的情况(Beauchamp et al.,2011)。跟随医学遗传学(Medical Genetics)的发展脚步,遗传经济学研究的最新趋势也开始将多个独立样本的数据进行整合并采用荟萃分析法(MetaAnalysis)寻找关联基因,目前已获得良好效果。例如Rietveld et al.(2013)整合了42个独立样本中126,559条个人数据进行荟萃分析,大大提高了统计效力以及关联分析结果的可靠性。
参考文献:
Barban, N., Jansen, R., De Vlaming, R., Vaez, A., Mandemakers, J.J., Tropf, F.C., Shen, X., Wilson, J.F., Chasman, D.I., Nolte, I.M. and Tragante, V., 2016. Genome-wide analysis identifies 12 loci influencing human reproductive behavior. Nature Genetics, 48(12), p.1462.
Benjamin, Daniel J., Christopher F. Chabris, Edward L. Glaeser, Vilmundur Gudnason, Tamara B. Harris, David I. Laibson, Lenore J. Launer, and Shaun Purcell 2007. “Genoeconomics.” In Biosocial Surveys, eds. Maxine Weinstein, James W. Vaupel, and Kenneth W. Wachter, 192–289. Washington: National Academies Press.
Böckerman, P., Cawley, J., Viinikainen, J., Lehtimäki, T., Rovio, S., Seppälä, I., Pehkonen, J. and Raitakari, O., 2019. The effect of weight on labor market outcomes: an application of genetic instrumental variables. Health economics, 28(1), pp.65-77.
Linnér, R.K., Biroli, P., Kong, E., Meddens, S.F.W., Wedow, R., Fontana, M.A., Lebreton, M., Tino, S.P., Abdellaoui, A., Hammerschlag, A.R. and Nivard, M.G., 2019. Genome-wide association analyses of risk tolerance and risky behaviors in over 1 million individuals identify hundreds of loci and shared genetic influences. Nature genetics, p.1.
Norton, E.C. and Han, E., 2008. Genetic information, obesity, and labor market outcomes. Health Economics, 17(9), pp.1089-1104.
Okbay, A., Beauchamp, J.P., Fontana, M.A., Lee, J.J., Pers, T.H., Rietveld, C.A., Turley, P., Chen, G.B., Emilsson, V., Meddens, S.F.W. and Oskarsson, S., 2016. Genome-wide association study identifies 74 loci associated with educational attainment. Nature, 533(7604), p.539.
Rietveld, C.A., Medland, S.E., Derringer, J., Yang, J., Esko, T., Martin, N.W., Westra, H.J., Shakhbazov, K., Abdellaoui, A., Agrawal, A. and Albrecht, E., 2013. GWAS of 126,559 individuals identifies genetic variants associated with educational attainment. Science, p.1235488.
Sanchez-Roige, S., Fontanillas, P., Elson, S.L., Pandit, A., Schmidt, E.M., Foerster, J.R., Abecasis, G.R., Gray, J.C., de Wit, H., Davis, L.K. and MacKillop, J., 2018. Genome-wide association study of delay discounting in 23,217 adult research participants of European ancestry. Nature neuroscience, 21(1), p.16.
Tyrrell, J., Jones, S.E., Beaumont, R., Astley, C.M., Lovell, R., Yaghootkar, H., Tuke, M., Ruth, K.S., Freathy, R.M., Hirschhorn, J.N. and Wood, A.R., 2016. Height, body mass index, and socioeconomic status: mendelian randomisation study in UK Biobank. bmj, 352, p.i582.
推文作者简介
朱晨,中国农业大学经济管理学院。研究方向:食物消费、健康经济学、人力资本。
Abstract
The costs of comprehensively genotyping human subjects have fallen to the point where major funding bodies, even in the social sciences, are beginning to incorporate genetic and biological markers into major social surveys. How, if at all, should economists use and combine molecular genetic and economic data from these surveys? What challenges arise when analyzing genetically informative data? To illustrate, we present results from a "genome-wide association study" of educational attainment. We use a sample of 7,500 individuals from the Framingham Heart Study; our dataset contains over 360,000 genetic markers per person. We get some initially promising results linking genetic markers to educational attainment, but these fail to replicate in a second large sample of 9,500 people from the Rotterdam Study. Unfortunately such failure is typical in molecular genetic studies of this type, so the example is also cautionary. We discuss a number of methodological challenges that face researchers who use molecular genetics to reliably identify genetic associates of economic traits. Our overall assessment is cautiously optimistic: this new data source has potential in economics. But researchers and consumers of the genoeconomic literature should be wary of the pitfalls, most notably the difficulty of doing reliable inference when faced with multiple hypothesis problems on a scale never before encountered in social science.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号