阅读:0
听报道

推文人 | 周广肃(南开大学经济学院讲师)
原文信息
Feenberg, D., Ganguli, I., Gaule, P., & Gruber, J. (2017). It’s good to be first: Order bias in reading and citing NBER working papers. Review of Economics and Statistics, 99(1), 32-39.
引言
在传统的经济学模型中,人们通常是从一个选择集合中进行最优化的选择,但是正如Rubinstein & Salant(2006)所强调的,大多数情况下人们面临的不是选择集合,而是一个选择列表。选择列表的一个重要的特点是有排序的区别,列表展示的排列顺序很有可能会对人们的选择结果产生重要的影响。Miller & Krosnick(1998)和Mantonakis et al.(2009)指出有时会存在选择的“初始效应”(primacy effect),即人们会倾向于选择列表中的排序第一的候选项,而有时候则会存在“最近效应”(recency effect),即人们也有可能倾向于选择列表中排序最后的选项。以往研究显示,两种效应均有存在的可能性。而在这篇文章中,作者在一种非常有趣的情境下研究了这一问题:NBER工作论文推送邮件中的论文名称的排序是随机排列的,作者利用这一自然实验来研究论文在列表中相应的排序对其点击阅读、下载和后续引用的影响。
NBER工作论文推送方式简介
每个周一的早上,超过23000名注册过“New this Week”(NTW)的用户将会收到上个星期的NBER工作论文的名单列表。邮件的顶端只会显示论文的题目、作者和链接,邮件的后半部分会显示论文的摘要和链接。尽管每个人都可以浏览工作论文主页上的摘要,但是完整的PDF版本的论文只对部分特殊读者开放下载,主要包括部分研究机构、公司、记者、公务人员、军队人员和发展中国家的居民。2013-2014年,每个星期通过邮件发布的工作论文数量在7-45篇之间,均值在20.3篇。
当一篇论文投到NBER工作论文发布办公室之后,相关工作人员将会检查这篇论文是否达到了NBER工作论文的发布条件,如果这些条件满足,那么论文将会被自动分配工作论文号。这一处理过程将会在周二到周四之间分批次进行处理,周五将会被正式发布,而接下来的周一将会通过邮件推送给相关注册人。由于这一检查过程的存在,使得论文的工作论文号和投递的顺序并不一定是相关的,而且投递和实际发布之间也常常存在着延迟。虽然下文的一些数据表明,论文在邮件中的排序确实和投递的日期以及延迟天数相关,但是没有证据表明投递日期和延迟是由NBER或作者可以安排的。
数据和实证策略
对于这篇论文来讲,作者收集了NTW过去三年的邮件推送论文列表数据,并且将这些列表中论文的三类结果变量进行了匹配。前两种结果分别是通过邮件的链接点击到论文的网络界面的次数,以及下载PDF全文的数量,这两类数据只有2013-2014年两年的数据。第三个被解释变量为论文的引用数量,引用数据来自于谷歌学术搜索,有关这一分析的数据采用2012-2013年两年的论文列表中的论文数据。论文使用的实证方法为OLS回归,具体方程如下:
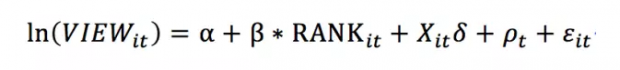
其中i表示论文,t表示星期,VIEW表示上面提到的三类结果变量,RANK表示用不同方式衡量的论文在邮件列表中的顺序,X是一系列和论文相关的控制变量,是星期的固定效应。其实这种模型设定,是利用同一个星期内推送论文的不同顺序的变化,来识别其对于结果变量的影响。
控制变量主要有,论文的作者数量,最高产作者工作论文发表数量的对数值,论文是否有star的合作者(定义为之前是否具有NBER前5%的高引论文),论文罗列的参与NBER研究项目数量以及一系列不同项目的虚拟变量。为了控制其他可能内生的有关论文排列顺序的设置,论文还加入了论文在星期几投递的虚拟变量,以及论文从投递到发布的延迟时间。
基准回归结果和稳健性检验
文章中的表2汇报了基准的回归结果(由于表格较长,我们只截取了主要变量结果),其中1-3列的被解释变量分别为点击链接数量、下载数量和引用量的对数值,关键变量“排序第一”使得点击量多33%,下载量多30%,引用量多27%。
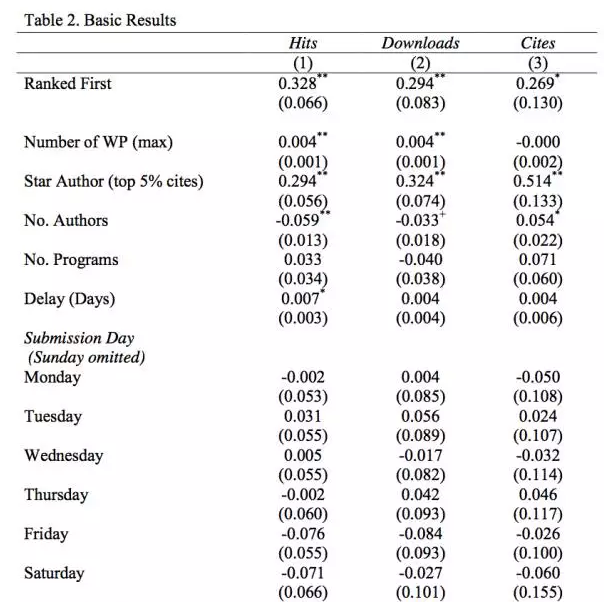
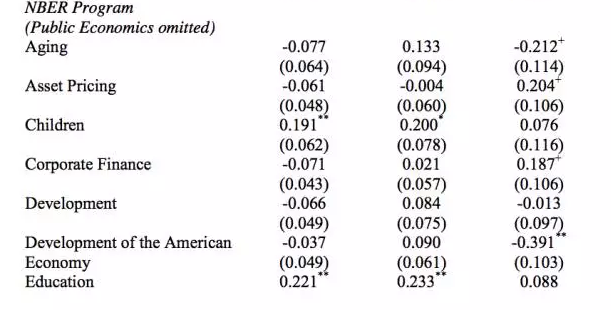
表3通过加入其他不同的衡量排序的变量,并且将点击量、下载量和引用量三个变量的结果分别进行了汇报,这里我们仅仅展示了有关点击量的结果,其他两个变量主要结论基本一致。第1列考察排序的线性作用效果,第2列同时加入了是否排序第一和排名顺序两个变量,第3列加入了是否排序第一和是否排序第二两个虚拟变量,第4列加入了是否排序最后变量,第5列加入了排名顺序和是否排序最后两个变量,第6列加入了排序的quantile的划分变量。所有的结果显示,在论文的推送过程中,不仅存在排序靠前所产生的primacy effect,而且存在排序最后的recency effect。

文章还进行了多种稳健性检验,来剔除其他因素的影响。例如表4探讨了论文推送列表排序的影响因素,发现论文延迟的天数和投递的日期确实有显著影响,但是这些变量却对论文的点击、下载和引用没有显著的影响,且不是人为操纵的。表5继续进行的稳健性检验包括:第1列将样本仅限定为与排名第1的论文同一天投递的论文,从而剔除投递日期的影响;第2列只保留排序第一或排序第二的论文样本,从而剔除质量好的论文被倾向于排序更高的质疑;第3和第4列加入了其他渠道产生的论文点击量,作为论文质量的代理变量。以上稳健性检验都显示了相似的结论。
影响机制的探讨论文提出并验证了三种影响渠道:
首先,一种可能的机制在于非专业阅读者没有足够精力和兴趣看完整个推送文章的列表,所以习惯性地点击第一个链接,但是我们利用邮箱后缀名为“”的读者作为专业读者,并且利用子样本的回归也得到了相似的影响结果。
其次,一种可能的机制在于只有对于那些推荐文章列表比较长的推送,读者才会展现出对于排序靠前的论文的额外关注。通过加入排序变量和推荐列表是否较长(定义为大于中位数的长度)的交叉项,但是没有发现特别一致的显著的影响效果。
最后,一种可能性在于读者是否关注排名靠后的论文,取决于第一篇文章的质量,如果第一篇文章质量较高,读者可能有兴趣继续关注后面的论文。通过加入排名变量和第一篇文章是否有star作者的交叉项,但是没有发现特别一致的显著结果。
Abstract
Choices are frequently made from lists where there is by necessity some ordering of options. In such situations individuals can exhibit both primacy bias towards the first option and recency bias towards the last option. We examine this phenomenon in a particularly interesting context: consumer response to the ordering of economics papers in an email announcement issued by the National Bureau of Economic Research (NBER). Each Monday morning Eastern Standard Time (EST) the NBER issues a “New This Week” (NTW) email that lists all of the working papers that have been issued in the past week. This email goes to more than 23,000 subscribers, both inside and outside academia, and the placement order is based on random factors. We show that despite the randomized list placement, papers that are listed first each week are about 30% more likely to be viewed, downloaded, and cited over the next two years. Lower ranking on the list leads to fewer views and downloads, but not cites; however, there is also some recency bias, with the last paper listed receiving more views, downloads and cites. The results are robust to a wide variety of specification checks and are present for both all viewers / downloaders, and for academic institutions in particular. These results suggest that even among expert searchers, list-based searches can be manipulated by list placement.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}