图片来源:Causal Reasoning: Fundamentals and Machine Learning Applications
文献信息:
Prashant Garg & Thiemo Fetzer, 2024. "Causal Claims in Economics," CESifo Working Paper Series 11462, CESifo.
01
引言
因果推断革命推动了经济研究范式在过去几十年中发生显著转变。自然实验(natural experiments)、断点回归(RDDs),工具变量(IVs)等方法的出现,增强了因果识别,在解决内生性问题的同时,提供了更可信的因果效应估计。主流期刊现在更倾向于录用这些使用因果推断的研究,而不是传统的相关性研究。尽管我们对方法的进步进行了深入的讨论,但始终缺乏对经济研究结构和复杂性的演变的量化研究,特别是对某些子领域中使用因果推断和叙述复杂性变化的研究。
为此,本文通过分析超过44,000篇NBER和CEPR工作论文,使用定制的大型语言模型(LLM)提取结构化信息,构建论文的知识图谱,包括用于证明每个经济学声明的方法(因果推断或其他方法)以及分析中使用的数据。通过这些知识图谱,本文能够定量评估经济研究中叙述的复杂性和结构随时间的变化,能够讨论研究的原创性、是否是核心议题等。
本文的分析揭示了几个值得注意的模式。首先,随着时间的推移,使用因果推断方法的比例显著增加,因果声明的平均比例从1990年的约4%上升到2020年的近28%,反映了经济学中可信度革命(credibility revolution)的影响。
其次,促进在顶刊发表的因素与提高饮用量的因素之间存在权衡。具体来说,使用因果推断方法、引入新颖的因果关系和涉及一些较为边缘概念,可以增加在Top 5期刊发表的可能性。然而,这些特征并不一定导致发表后引用次数更高。相反,关注广泛认可概念的论文一旦发表,往往会获得更多的引用,突出了发表成功和更广泛学术影响之间存在可能的取舍。
第三,叙述复杂性与在顶刊发表和增加引用次数呈正相关关系,尤其是在前5名和前6-20名期刊中。这表明复杂的因果叙述对于发表成功和学术影响力都是有价值的。
本文的发现也是当前关于经济研究的优先级的的体现。批评者认为,对特定实证方法和复杂叙述的强调可能导致对结果的过度自信和潜在的过度解释。方法的误用或过度解释也可能导致有问题的结论,即使使用RCT也可能存在局限性。此外,复杂叙述和框架可能以牺牲清晰度为代价,导致研究的故事和证据存在一定程度的割裂。
另一个困境是对显著性的过度强调。报告非期望结果(null results)的比例显著下降,研究者可能无意中通过探索各种模型规范并仅报告那些产生显著结果的规范,今儿实现p值操纵(p-hacking)。
本文通过提供关于实证方法演变及其在子领域中不同的普及程度的实证证据,为上述讨论做出了贡献。通过构建和分析经济学研究的知识图谱,本文提供了一个新颖的视角,来观察叙述的复杂性和结构如何随时间变化,以及它们如何影响研究结果的传播和认可。
数据
02
本文基于两个主要来源构建工作论文语料库(Working paper corpus):国家经济研究局(NBER)和经济政策研究中心(CEPR)。NBER数据集包含28,186篇工作论文,而CEPR数据集包括16,666篇论文,总共样本为44,852篇论文。这些论文跨越了几十年,涵盖了劳动经济学、宏观经济学、发展经济学和金融学在内多个子领域。
经过文本预处理之后,本文采用了一个多阶段过程,使用大型语言模型(LLM),特别是GPT-4o mini,从语料库中的工作论文中提取和分析信息。这种方法比较高效,能够迅速提取出结构化信息。
具体而言,第一阶段提取定性摘要,获得研究问题,关于论文中使用的因果识别策略的信息和有关数据使用、可访问性和致谢的详细信息;以及作者姓名、机构隶属、研究领域和使用方法等元数据。第二阶段提取因果声明,识别作者描述的源变量(source variable)和汇变量(sink variable),确定了关系类型(如直接因果效应、间接因果效应、中介、混杂、等),并记录了用于建立每个链接的实证方法(如RCT、IV、DiD、OLS、模拟)。第三阶段提取数据使用和可访问性,获得文章使用数据的所有权(如私人公司、公共部门、研究者)、可访问性(自由可访问、受限)以及数据粒度、分析单位、时间和地理背景等信息。随后利用AI将每一个变量映射到到JEL代码进行标准化。
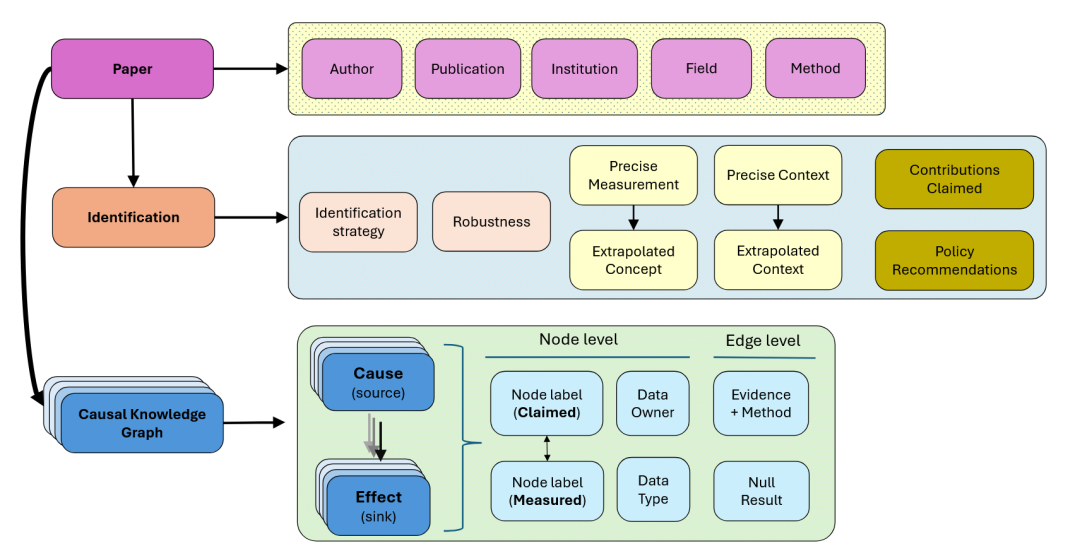
本文从NBER官方元数据、LLM搜索、OpenAlex仓库和Baumann & Wohlrabe(2020)四个渠道获取工作论文最终的发表数据,从RePEc的CiteEc服务、Baumann & Wohlrabe (2020)和OpenAlex仓库三个渠道获取引用数据。
03
经济学的知识图谱
对于每篇论文p,本文定义了一个有向图 Gp=(Vp,Ep),其中Vp是代表经济概念的节点集合,这些概念使用JEL代码进行分类,而Ep是代表从一个源节点到一个汇节点的声明的有向边集合。一个声明是否被解释为因果声明取决于连接节点的边的属性。对于边e∈Ep,如果这个声明是使用因果推断方法证实的,则将其分类为因果边。根据这个定义,数据集中大约19%的所有声明被分类为因果边。
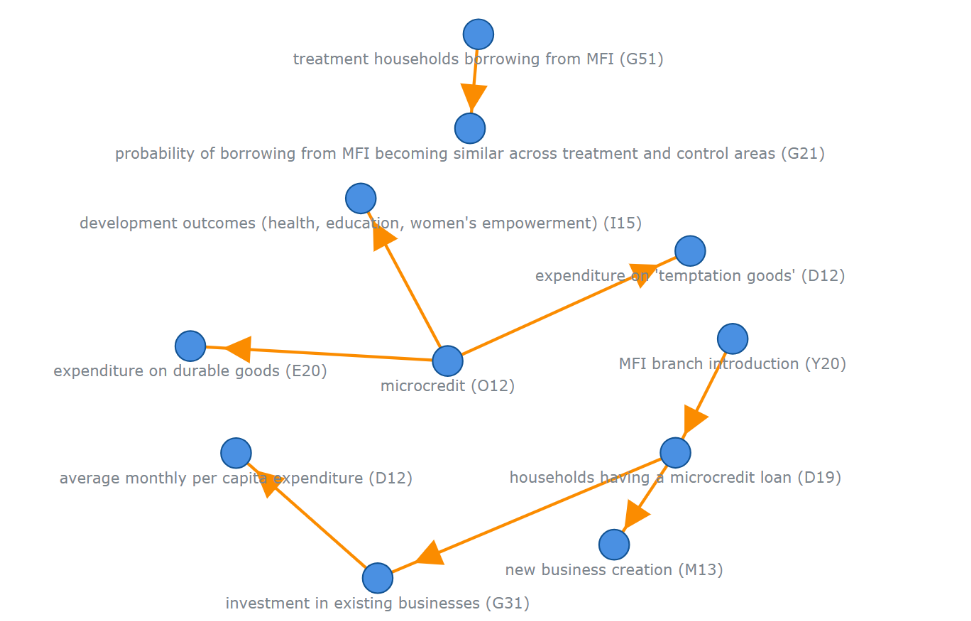
本文考虑了几个派生出的关键度量。边的数量,记作∣Ep∣,表示论文中讨论的声明总数,反映了叙述的广度。∣Ep∣越大说明叙述更广、更复杂。因果边的数量,记作∣Epcausal∣,表示使用因果推断方法证实的声明总数,表明了论文中因果分析的深度。Pp表示Gp中的唯一路径数量,捕捉论文中叙述的相互关联性;Pp越高,表示论证结构更交织。Lp表示Gp中的最长有向路径长度,反映论文的推理深度。因果子网络对应的变量可以被记作Ppcausal和Lpcausal。下图为Banerjee et al.(2015)的知识图谱。
 本文还使用源-汇比率Rp衡量Gp唯一源节点和唯一汇节点之间的平衡。Rp=1表示唯一的源节点和汇节点数量相等,反映了论文中关系的平衡探索。Rp大于1的值表明论文关注多个源导致较少汇,而Rp小于1的值表明少数源导致多个汇。
本文还使用源-汇比率Rp衡量Gp唯一源节点和唯一汇节点之间的平衡。Rp=1表示唯一的源节点和汇节点数量相等,反映了论文中关系的平衡探索。Rp大于1的值表明论文关注多个源导致较少汇,而Rp小于1的值表明少数源导致多个汇。
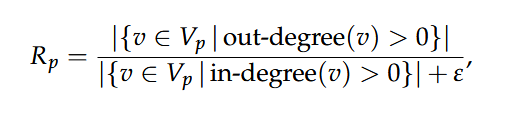
新颖边的比例Up,衡量论文声明的原创性。较高的Up表示论文引入了更多之前未记录的新关系,为研究的原创性做出了贡献。
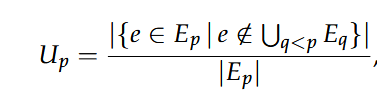
平均特征向量中心性Cp,捕捉了论文知识图谱中节点的影响力或重要性。对于知识图谱Gp中的每个节点v,计算特征向量中心性c(v),论文的平均特征向量中心性由下式给出:
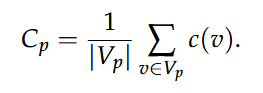
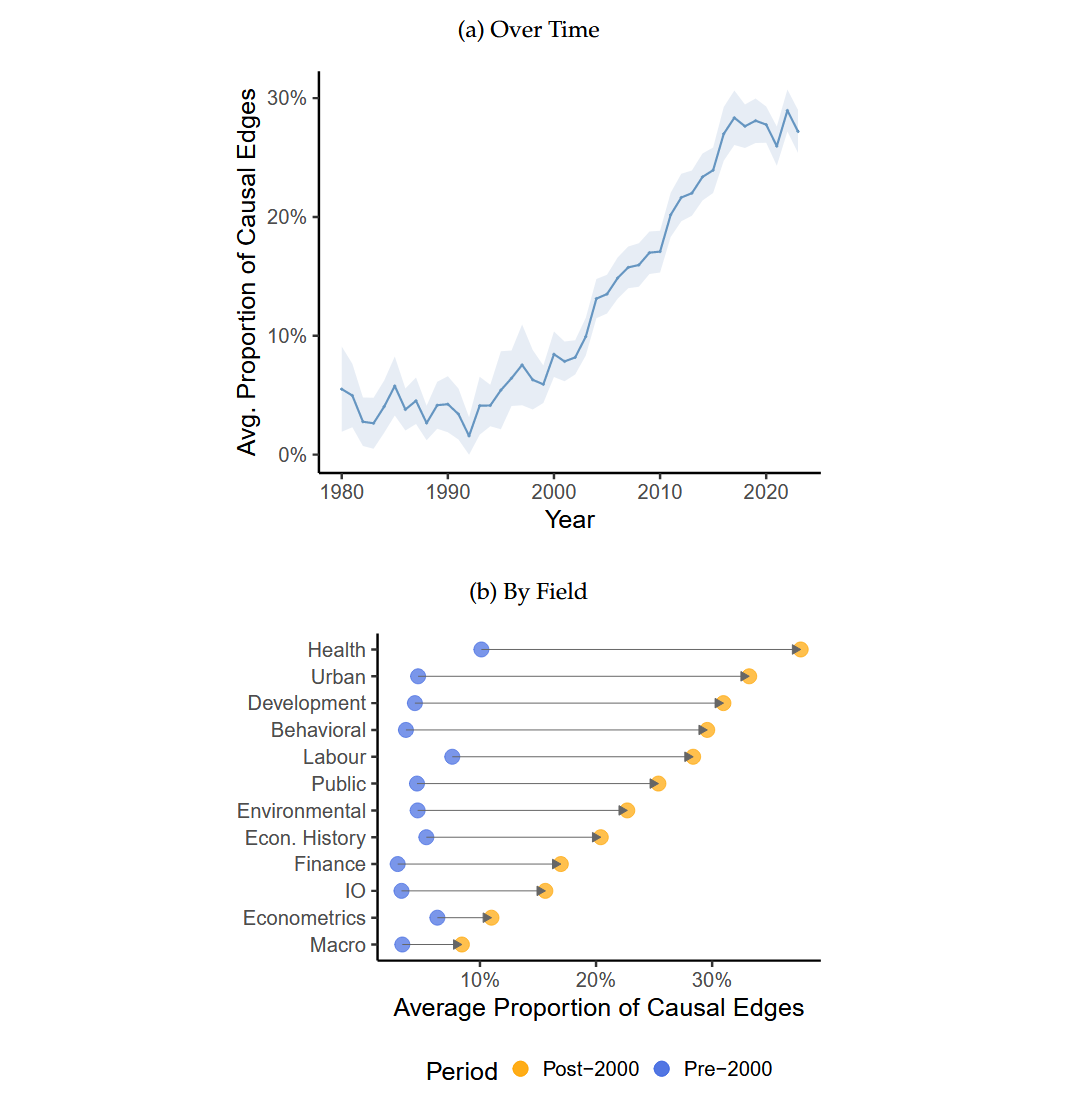
可信度革命的证据
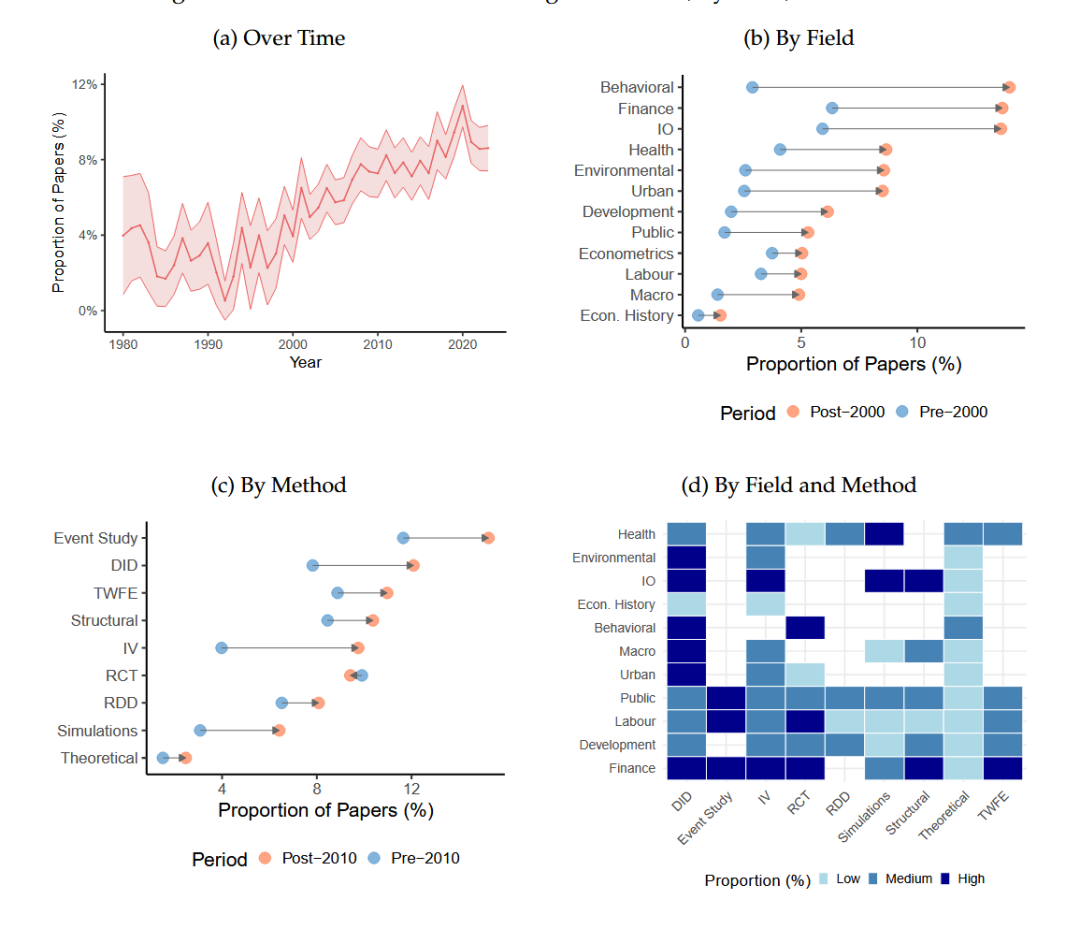
本文将论文中因果边的比例随时间的变化作为反映可信度革命的度量。下图显示了从1980年到2023年的变化,在1990年,因果边的平均比例大约是4.2%。到2000年和2020年,这一比例分别上升到大约8.4%和大约27.8%。这一上升趋势表明,经济论文越来越多地纳入因果推断方法来证实其假设。
分领域来看,城市、健康、发展和行为等领域显示出最大的增长。城市经济学领域增长最大,从2000年前的大约4.7%增加到33.2%。健康领域从10.1%增加到37.6%,成为所有领域中2000年后水平最高的。这些领域通常涉及政策相关的问题,并且受益于自然实验或有助于因果分析的数据,因此能够更广泛地采用因果推断方法。相比之下,宏观、计量等领域的增长较小或保持较低水平。这表明因果推断方法的采用在不同领域之间有所不同,受到每个领域内研究问题的性质、数据可用性和方法论传统的影响。
经验研究方法变迁
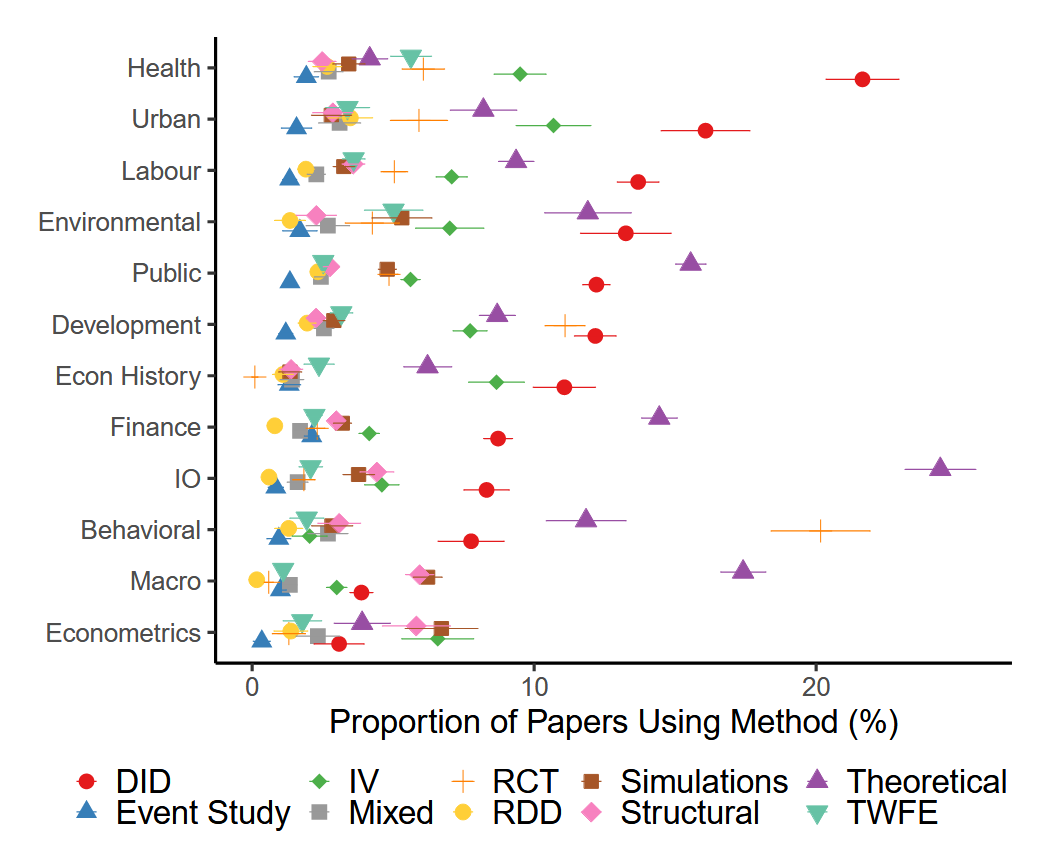
本文进一步展示了1980年至2023年实证方法的时间趋势。DiD、IV、RCT和RDD等方法的使用显著增长,反映了学科向更严格识别策略的转变。特别是DiD的使用变得越来越普遍,从1980年的大约4%上升到近年的超过15%。这一增长强调了DiD在利用政策变化和自然实验识别因果效应中的实用性。IV方法也稳步增加,突出了它们在通过外生工具解决内生性问题中的作用。随着实验设计在经济学中的可行性和接受度增加,RCT的使用自2000年代初以来加速增长。
相反,理论和非实证工作的占比显著下降,从1980年的约20%下降到2023年的不到10%,表明学科更广泛地强调实证分析。模拟的使用也有所减少,可能是因为目前可使用的数据集更丰富、实证方法变得更加复杂。
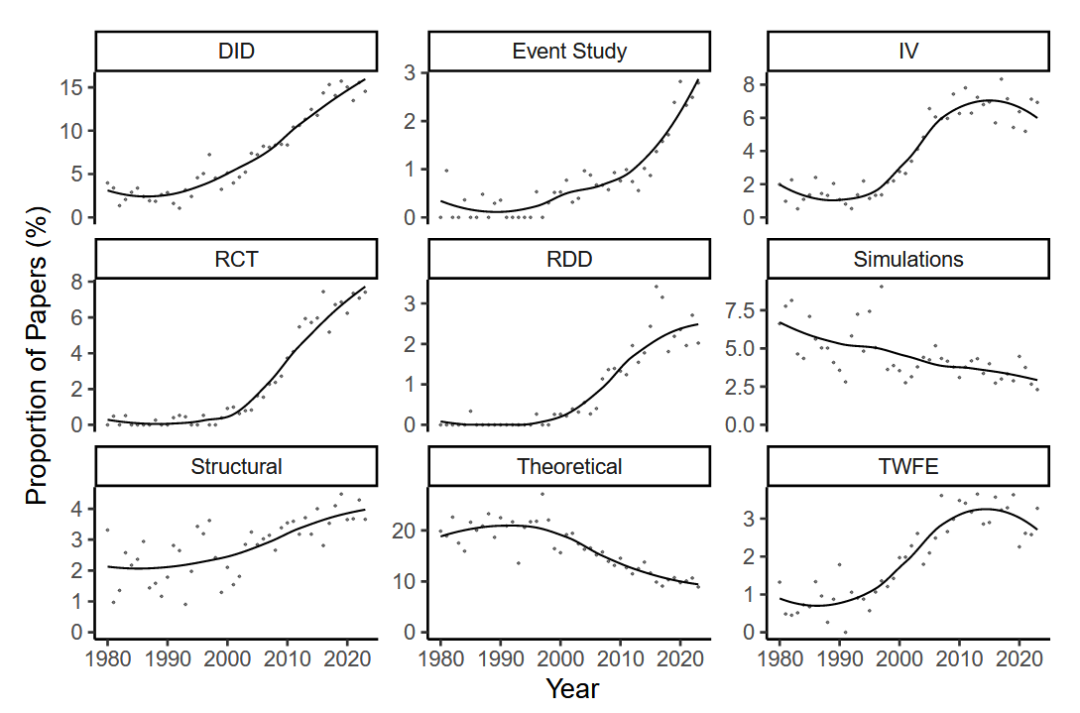
这些趋势在不同子领域中并不一致。下图展示了不同领域中实证方法的分布。劳动、公共和城市领域大量使用DiD。RCT在行为和发展领域尤为突出,分别有超过20%和11%的论文使用这种方法。相比之下,宏观、产业组织和金融等领域更多地依赖理论模型和模拟。理论方法在宏观经济学和金融学中占比较大,分别为18%和12%。结构估计和模拟在宏观经济学和产组中仍然很重要,其中复杂的理论模型对于理解总体现象和市场动态至关重要。
对于发表和引用的预测
04
对于发表
本文使用固定效应模型分析知识图谱对发表的影响。重点关注:论文是否发表在Top5、是否发表在Top 6-20期刊,以及是否发表在Top 21-100。核心自变量是之前定义的知识图谱度量,包括完整知识图谱(All)和仅包含因果边的子图(Causal)的度量,分别是唯一路径的数量、最长路径长度、源-汇比率、新颖边的比例、平均特征向量中心性、边的数量,以及边中因果边的比例等。加入年份固定效应以控制时间趋势。回归结果如下图所示。
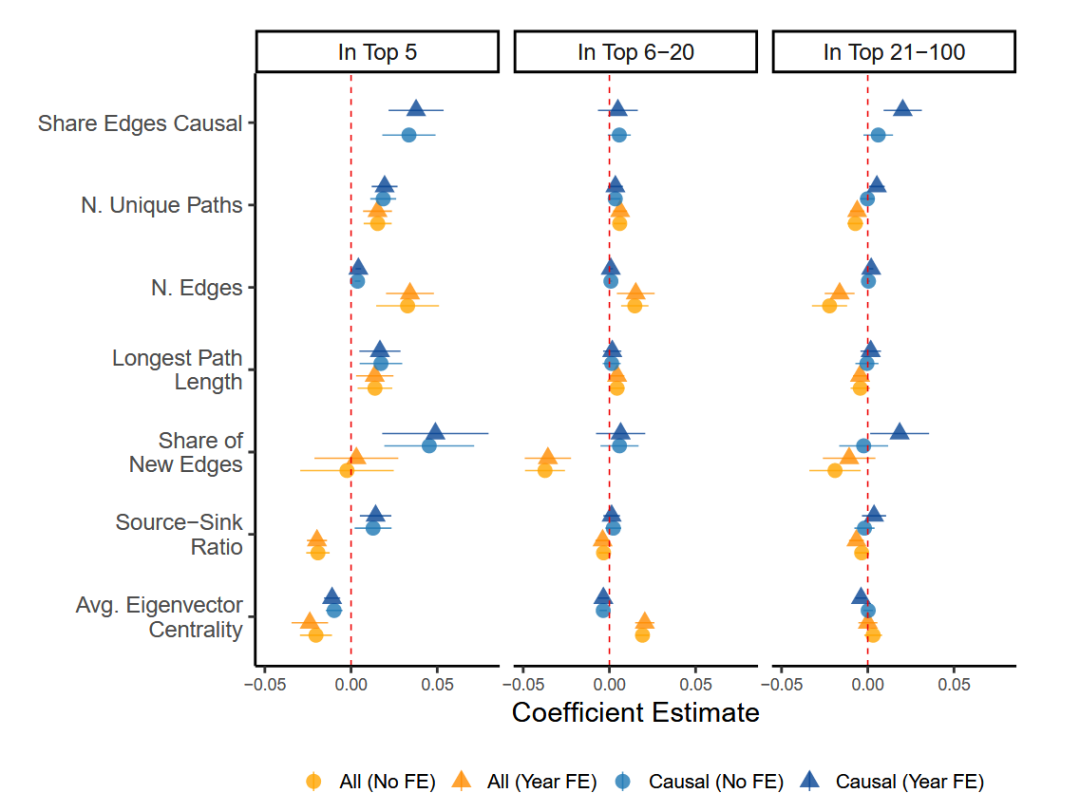
由模型揭示了几个值得注意的模式。首先,具有更高比例因果边(Share Edges Causal)的论文更有可能在Top 5期刊上发表。
其次,叙述复杂性(由唯一路径的数量和最长路径长度描述),通常与更高的发表结果相关,即具有更复杂叙述的论文,更受高排名期刊的青睐。但有意思的是,当仅考虑因果子图时,因果边的数量并不表现出与发表结果相同的正向关联。这暗示期刊更青睐对少量因果命题进行深入分析的论文。
第三,复杂性的类型很重要。对于完整知识图谱,更高的源-汇比率与Top5的发表负相关,表明关注少数原因导致多个效应的论文更受青睐。而对于因果子图,结果却是相反的。
第四,引入新的因果关系的论文更有可能在Top 5上发表。然而,这种模式在前6-20名期刊中并不成立,其中系数既不显著甚至为负。
第五,涉及较不中心或更专业概念的论文更有可能在Top 5上发表。相反,对于前6-20名期刊的发表结果,关注学科内更中心概念的论文更有可能被发表。这种差异表明顶级期刊可能更偏爱探索较少研究领域的创新研究,而其他期刊(field top)可能更倾向于关注特定领域内更中心主题的贡献。
对于引用
进一步考察知识图谱结构属性与论文引用影响之间的关系。由于样本中的引用次数分布高度偏斜,采用log(citations+1) 来规范化分布。回归的设置与前文一致,得到结论如下图。
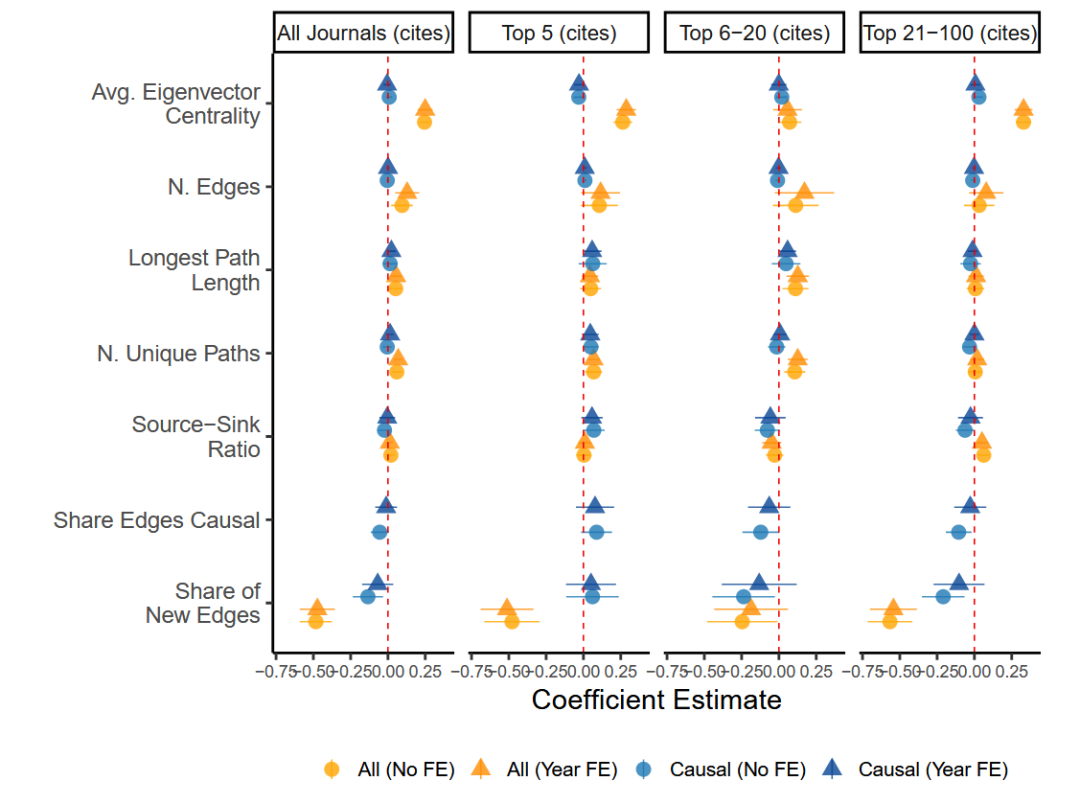
类似地,本文发现,探索复杂因果叙述、涉及多个路径和更深层次因果链的论文,关注更中心概念的论文倾向于获得更多引用;而引入新的非因果关系可能不会增强,甚至可能降低论文的引用影响。此外值得注意的是,对因果关系的原创性研究和对专业化领域的研究,可能可以更容易在顶刊发表,但并不一定带来以引用衡量的更大的学术影响。
总而言之,这些结果反映了当前学术界对严格因果推断的强调,特别是在排名更高的期刊中。然而,关于过度强调方法论而牺牲理论创新的担忧仍然存在;在方法严谨性与实质性贡献之间保持平衡,对于目前的经济学来说仍然是一个关键挑战。
05
来自数据的挑战
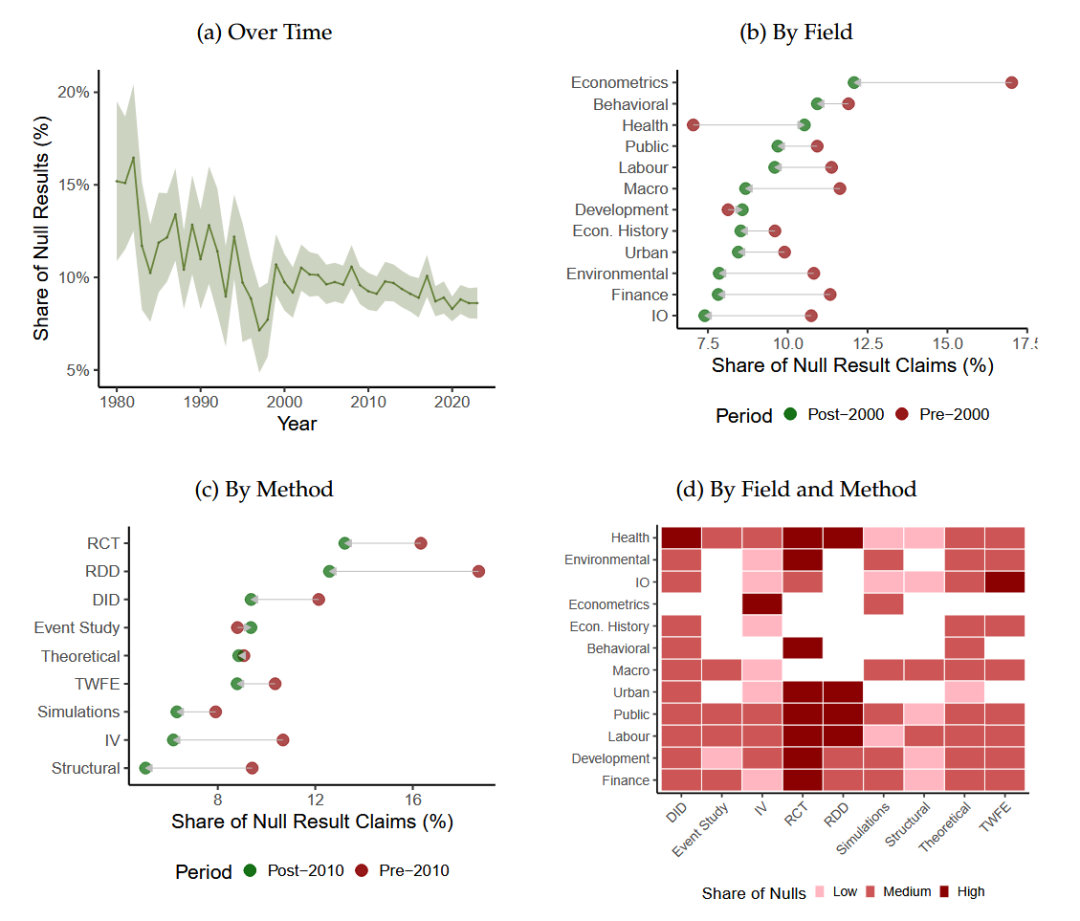
本文随后关注了显著性和数据可获得性这两个关键问题。本文指出,每篇论文中非期望结果声明的平均比例,从1980年的15%下降到2023年约8.6%。这种下降可能是由于出版过程偏爱显著的结果。在不同领域中,大多数领域在2000年后显示出下降,金融和产组的下降更为显著,可能是因为这些领域面临更强的发表偏见。计量经济学和行为经济学报告了更高比例的非预期结果(即不显著的结果)。在不同方法中,因果推断的方法报告了更高比例的非预期结果,结构估计和理论研究报告了较低的比例。本文进一步发现领域和方法会发生相互作用,在劳动经济学中的RCT(16.07%)和发展经济学(16.16%)以及健康经济学中的RDD(18.27%)观察到高比例的非预期结果。在金融中的结构方法(5.46%)和工业组织(3.20%)观察到较低的比例。
当前的研究越来越强调“独特的数据”,这一点在量化分析中得到印证。使用私营公司数据的论文比例从1980年的大约3.97%上升到2023年的约8.61%,2000年后有显著增加。这反映了私营公司更细粒度数据的可用性增加,以及研究人员与私营实体之间合作的增加。从领域上看,金融、产业组织和行为经济学等领域在2000年后显示出更高比例的私营公司数据使用。方法上看,事件研究、DiD和IV等方法与更高的私营数据使用相关,这些方法通常需要详细的公司事件、政策变化或工具变量数据,这类数据往往是非公开的。从领域和方法组合上看,在行为经济学中的DiD(28.85%)和金融(20.06%)以及工业组织中的结构估计(27.50%)观察到高使用率。在经济史和计量经济学中的RCTs观察到较低的使用率。
对非公开数据的日益依赖引起了我们对于可复制性和透明度的担忧。在数据可访问性与隐私和所有权问题之间进行权衡是当前经济学发展所面临的另一个关键挑战。
Abstract
We analyze over 44,000 economics working papers from 1980–2023 using a custom language model to construct knowledge graphs mapping economic concepts and their relationships, distinguishing between general claims and those supported by causal inference methods. The share of causal claims within papers rose from about 4% in 1990 to 28% in 2020, reflecting the “credibility revolution.” Our findings reveal a trade-off between factors enhancing publication in top journals and those driving citation impact. While employing causal inference methods, introducing novel causal relationships, and engaging with less central, specialized concepts increase the likelihood of publication in top 5 journals, these features do not necessarily lead to higher citation counts. Instead, papers focusing on central concepts tend to receive more citations once published. However, papers with intricate, interconnected causal narratives—measured by the complexity and depth of causal channels—are more likely to be both published in top journals and receive more citations. Finally, we observe a decline in reporting null results and increased use of private data, which may hinder transparency and replicability of economics research, highlighting the need for research practices that enhance both credibility and accessibility.
推文作者信息:
王奕东,中国人民大学统计学院2021级本科生
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}