
图片来源:AI生成
原文信息:
Sun, T., Yuan, Z., Li, C., Zhang, K., & Xu, J. (2024). The value of personal data in internet commerce: A high-stakes field experiment on data regulation policy. Management Science, 70(4), 2645-2660.
01
引言
个人数据已成为数字经济的关键投入,能够促进用户和商家之间的匹配,实现内容和服务的个性化分发,并刺激广告、健康和金融等一系列领域的创新。尽管其具有巨大价值,但在隐私和个人数据的正确使用方面仍存在重大担忧和讨论。为了解决这些问题,各国和地区制定或提出了各种类型的数据监管政策,包括欧洲的《通用数据保护条例》(GDPR)和美国加州等州的《消费者隐私法》等。已有研究讨论了隐私监管问题对在线广告等的影响,然而目前还没有系统研究来衡量数据监管对电子商务的影响,关于个人数据如何在这一领域创造价值的见解也相对较少。在设计个人数据规管机制时,政策制定者和公众仍然缺乏经验证据,因而其在决策时可能就会面临如何平衡数据价值和数据隐私之间关系的挑战。
本文通过大规模随机现场实验,模拟阿里巴巴电子商务平台关闭基于个人数据的算法推荐的情况,考察了数据监管对互联网商务的经济影响。具体而言,作者与阿里巴巴电子商务平台合作,并实施大规模随机现场实验,涉及555,800名打开淘宝移动应用并接触主页推荐的用户。其中大约一半的使用者被随机分配到处理组,他们的任何个人数据(例如人口统计数据、过去的点击和购买行为)都不会被包含于主页推荐的算法中,而控制组中的用户将体验个性化算法驱动的正常商品推荐。
研究背景
02
作者与阿里巴巴电子商务平台(淘宝移动应用)合作进行大规模随机实验,模拟平台上个人数据监管对互联网商务中用户、商家和市场结果的影响。阿里巴巴拥有超过1000万卖家和6.5亿买家,以及超过20亿的商品列表。每天有数千万笔交易和18.5亿美元的GMV。截至2018年,淘宝占据中国电子商务市场份额的70%,占据中国经济零售总额的18%。凭借其重要地位,阿里巴巴基本上可以在规模和种类上代表互联网商务。
鉴于平台拥有数以百万计的商家和种类繁多的商品,阿里巴巴平台通过个性化推荐将其商品与数亿用户相匹配。本文重点关注电商平台的主页推荐,这是电商平台最重要的个性化推荐模块,旨在降低搜索成本,促进用户和商家的匹配。
用户在线购物过程受益于个性化推荐体现在如下几个方面:首先,个性化推荐能够降低用户搜索成本,更快帮助用户发现与其偏好一致的商品。第二,个性化推荐会促使用户在平台的停留时间更长,从而提升其参与度。
03
研究设计与数据
作者及其研究团队选择在2019年夏天一个没有重大促销等活动的普通工作日展开实验,并随机抽取一部分打开淘宝移动应用并接触到主页推荐的用户加入实验,然后将这些用户随机分为控制组和处理组。控制组算法的输入数据包括商家数据、商品数据和个人数据(基本信息,如人口统计数据和个人行为信息,如过去的浏览、点击和购买记录)。处理组则禁止使用个人数据,因此其算法仅包含商品数据和商家数据,处理组本质上模拟了数据监管下互联网商务的极端情况。两组均遵循最大化匹配度的目标。该随机实验持续大约7小时,且共有555,800个用户接触了主页推荐。
研究团队记录了每一个用户的相关信息,包括用户的唯一标识符、测试组别、推荐商品、浏览商家、注册日期、历史点击和购买信息及其在实验期间的点击和购买信息,购买数据包括购买商品、商家、购买价格、商品利润以及具体时间。此外,作者团队还进一步用丰富的商品特征(类别、品牌)、商家特征(年营业收入、信用等级)和用户特征(人口统计资料)来扩充数据集。由此产生的数据集能够使研究团队能够在总体水平及更细微的水平上分析不同干预措施的效果。
除随机产生的异质变化外,该数据集还有其他优势。首先,记录了每个用户浏览过的详细商品推荐,因此可以在测试组水平和个人水平上描述推荐商品的变化。其次,收集了每个用户的详细行为数据,包括历史点击和购买信息,因此作者可以推断每个用户的偏好,并描述商品推荐与其偏好之间的匹配程度。第三,收集了主页以外的用户行为,因此可以获取用户主动搜索的信息并理解数据监管的间接影响。变量定义如下:
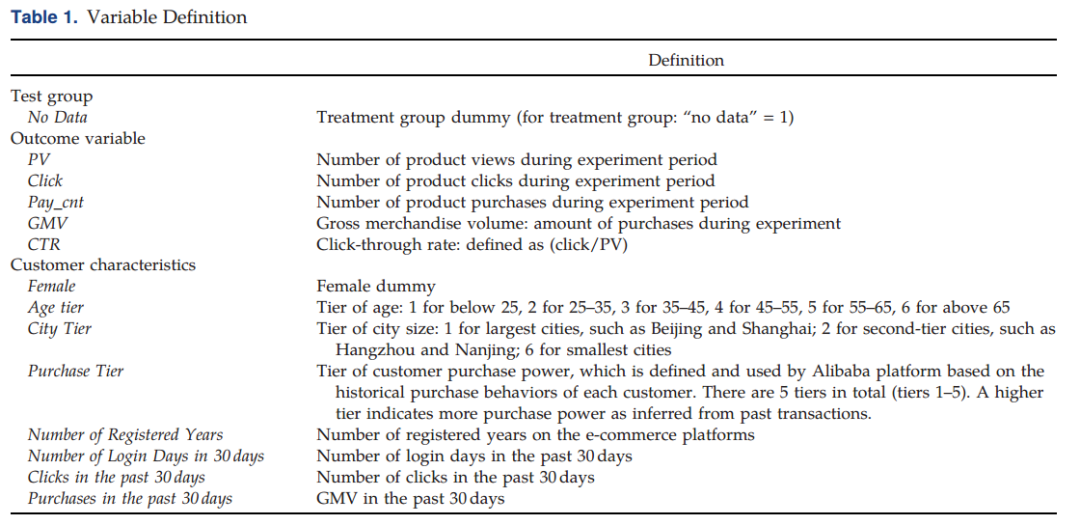
下图为描述性统计。可以发现控制组和处理组的用户信息之间没有显著差异,表明了实验的随机性。其中,PV为商品浏览量,Click为商品点击量,Pay_cnt为商品购买量,GMV为交易总额,CTR为点击量与浏览量的比值,以上变量数据均为该实验期间记录。
研究结果
04
4.1 对商品推荐的影响
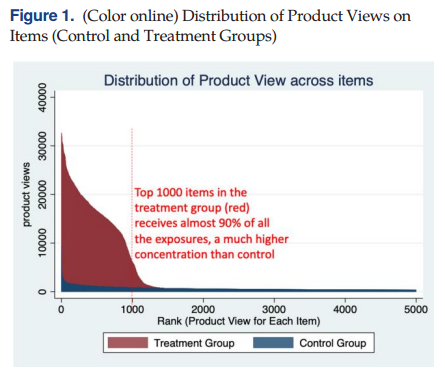
作者首先检验了允许使用个人信息数据(C,控制组)和禁止使用个人数据(T,处理组)时商品推荐的差异。如图1所示,作者绘制了控制组和处理组中不同商品的PV数量分布,发现当电商平台主页关闭基于个人数据的算法推荐时,商品推荐的集中度显著增加。
首先,在控制组用户的主页,超过400万个商品被推荐,且其分布较为均匀,即使是展示量最高的商品也仅有数百次展示,排名前1000的头部商品的浏览量也仅占主页推荐所有商品浏览量的4%。而在处理组中,商品推荐聚焦在较少的头部商品上,最受推荐的商品推荐次数超过3万次,排名前1000的头部商品浏览量几乎占据主页推荐中所有商品浏览量的90%。
此外,处理组关闭基于个人数据的算法推荐所出现的集聚现象会导致推荐商品的种类数量显著减少(从400万减少至28万),并使得平台无法识别每个用户的偏好从而只能推荐符合普通用户偏好的大商家的主流产品。
4.2 对匹配度(点击率、浏览量和购买量)和消费多样性的影响
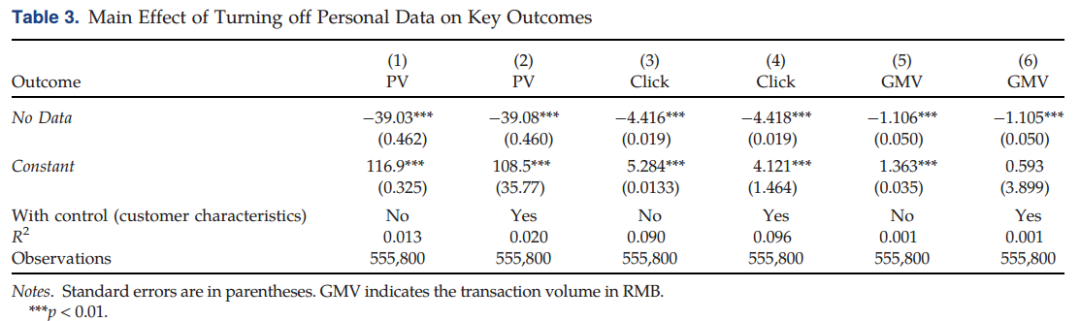
作者跟踪了用户对推荐产品的点击率(CTR)并基于表3发现处理组点击率骤降75.3%(计算过程详见原文阐释),原因可能是关闭基于个人数据的算法导致相关有效推荐减少。其次,处理组中用户的主页推荐商品浏览量(PV)减少33.6%,表明用户对电子商务平台交易的参与度显著下降。结合点击率和参与度的两重消极影响,处理组的商品交易总额(GMV)相比于控制组下降约81.1%,交易数下降约86%。
此外,作者分别在总体水平和个人水平上研究了关闭基于个人数据的算法推荐对用户消费多样性和集中度的影响。研究发现关闭后用户消费多样性显著下降,用户浏览、点击和购买过程中的消费集中度显著上升(基于总体水平衡量的基尼系数),与4.1的实证结果保持一致(该部分详见在线附录E及文献综述部分的详细讨论)。
4.3 对不同类型商家和商品的影响
作者进一步研究了关闭基于个人数据的算法推荐对商家和其商品销售的影响。阿里巴巴主要采用两种评价商家的指标:年营业额和信用等级,作者采用这两类指标对平台商家进行分类。
首先,文章根据过去12个月(2018年7月至2019年6月)的年营业额将商家分为大型商家和小型商家(big seller),年营业额在120万元以下的商家被视为小型商家(small seller),超过120万元的商家被视为大型商家。其次,文章根据阿里巴巴的商家评级分级系统对商家进行分组,商家评级是平台用户在每笔订单完成后给出的评价,可以体现商家的声誉表现。信用等级很大程度上取决于商家的销量。“红心”(hearts)层级代表该商家信用等级较低(low tier),“蓝钻”(diamonds)、“蓝冠”(crown)、“金冠”(golden crown)则代表商家信用等级较高(high tier)。此外,文章还采用其他的分类标准检验对不同商家的处理效果,例如用500万GMV作为大型商家和小型商家的分类标准、“红心”和“蓝钻”层级为信用等级较低的商家,回归结果依旧稳健(详见附录C)。
如下表4所示,对于小型商家和低信用等级的商家,关闭基于个人数据的算法推荐对于其商品浏览量和销量的负向影响更大。“数据禁令”对小型商家商品的PV产生了54%的负向影响(有的商家的PV甚至会降至0),而对大型商家则仅仅产生了27%的负向影响。同样地,小型商家销量下降幅度也更大,甚至在实验期间没有获得收入。此外,低评级商家的PV下降了92%,而高评级商家仅下降了33%。
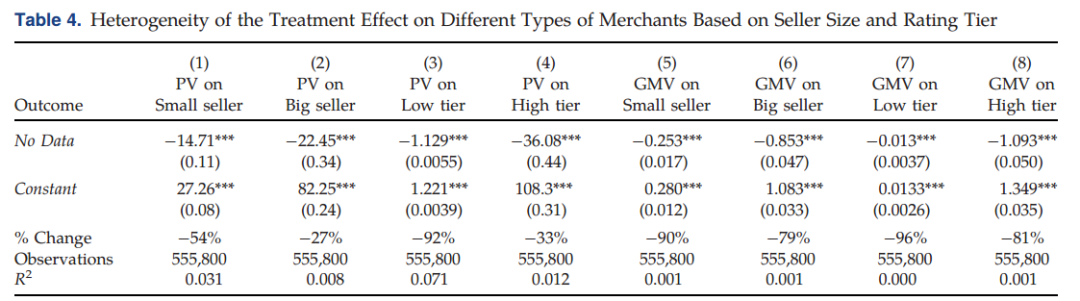
该研究结论与关于隐私监管对市场结构影响的理论预测一致(Campbell et al.,2015),但也揭示了一种不同的机制:个人数据的缺乏会使得个性化匹配失效,从而导致商品分销的集中。电子商务中规模较小或相对较新的商家更容易受到数据监管的影响。作者指出,这种由数据监管造成的不平等现象可能值得政策制定者关注。
而在商品层面,如下表5所示作者观察到与头部商品相比,长尾商品的PV和GMV下降幅度更大,与图1一致。其中,指标排名前1000名的商品定义为头部商品,其他则为长尾商品。研究发现,处理组相较于控制组,头部商品PV增加了448%,长尾商品PV减少了55%,而长尾商品销售额下降了83%,头部商品销售额下降了49%。有趣的是,尽管头部商品在处理组中获得了更高的曝光度,但其销售额仍下降了49%,因而大多数商品的推荐和PV被“浪费”,它们被推荐给了对其不感兴趣的用户。这说明,“数据禁令”下,平台的努力与用户的注意力均被“浪费”了。
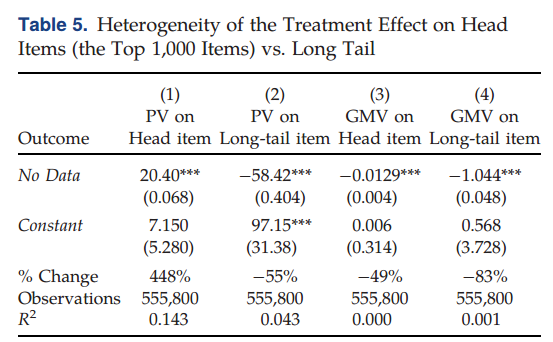
4.4 对用户端的异质性影响
由表6可得,在关闭基于个人数据的算法推荐后,新用户、购买力较低的群体、女性用户和来自三线城市及以下的用户受到的影响更大。具体而言,对于最近注册的消费者,PV和销售额的下降幅度更大(由交互项No Data×RegisterYear的显著正系数可得);对于购买力较弱的用户,浏览量和购买量显著减少;与男性用户相比,“数据禁令”后,女性用户浏览的商品数量和购买量要少更多。
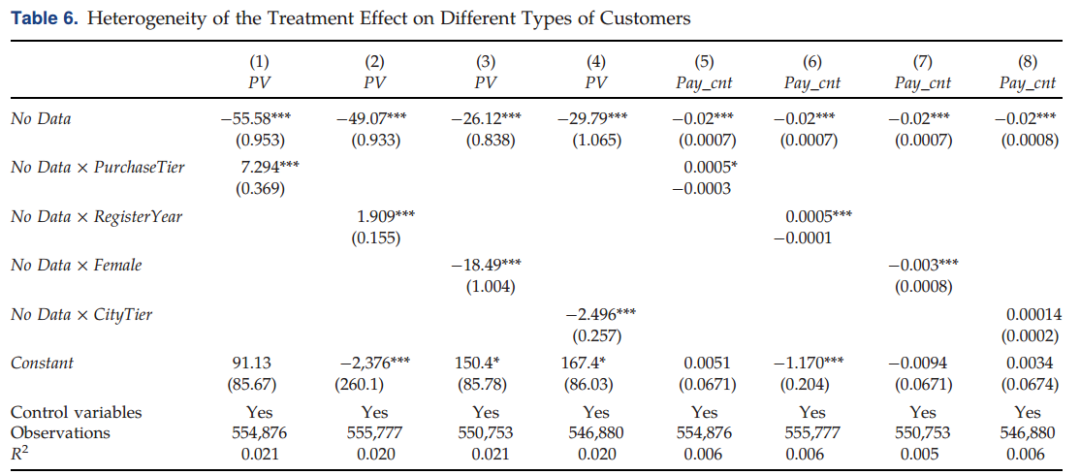
进一步地,作者利用用户过去30天的点击行为构建了累积意义上的“数据量”变量(data volume),并发现了异质性的处理效果。与数据量较少的用户相比,数据量较多的用户会经历更大程度的主页推荐质量下降,浏览次数也显著减少(详见附录图表F1)。而在控制数据量的异质性后,所有用户特征的调节效应仍保持显著(详见附录表C4)。此外,作者用过去30天的点击商品数量衡量其偏好多样性,其实证结果与上述数据量相关的实证结果均类似。
由以上的实证分析,作者假设可能有两种相互“竞争”的力量潜伏于用户的异质效应之下:数据量和用户弹性,每个用户的选择都隐含着两种力量的对比。一方面,经验更丰富、购买力层次更高的用户通常会在平台上积累更多的行为数据,因而会更应受到数据监管的影响,因为对于他们来说,“数据禁令”的推荐算法会删除更多的数据量;另一方面,此类用户也更加具有弹性,因而即使算法推荐质量严重恶化,对他们的影响也微乎其微,他们对于平台推荐可能更加宽容,参与的兴趣度及与平台的链接可能更深。而对于新用户和较低购买层次的用户行为数据较少,其消费行为对于数据驱动的推荐变化更为敏感,且其不熟悉数字平台和移动购物体验,对于推荐质量稍有下滑便会挫败其参与热情。
而从实证结果来看,第二种力量“用户弹性”似乎较为重要。数据监管对某一用户群体的影响可能取决于哪一种力量占据主导地位。
4.5 潜在机制:个人数据使用的限制恶化了商品推荐与用户偏好之间的匹配
基于个人数据的算法推荐能够提升消费者与推荐产品的匹配度,因为平台能够依据消费者的历史行为推断消费者偏好并具体推荐商品。因而,作者在个人层面(区别于4.1的分布层面)检验了推荐质量的变化,并发现:(1)个人数据的使用对于确定用户偏好与推荐商品之间的匹配至关重要;(2)匹配可以解释处理组和控制组之间客户浏览、点击和购买(PV、CTR和GMV)的很大一部分差异。
具体而言,根据推荐系统(recommender systems)相关文献,本文使用用户显示偏好(由用户历史点击产品类别向量衡量)和主页推荐(由该类别的推荐商品向量衡量)之间的余弦值来定义算法推荐的“匹配分数”。研究发现,如图3所示与控制组相比,处理组的匹配分数显著降低,分布更接近于0;控制组的分布则更接近于1。控制组的匹配分数中位数为0.81,均值为0.75;而实验组匹配分数中位数则仅为0.17,均值为0.25。
消费者在接触不匹配的商品推荐时通常会有更少的商品浏览量和购买量。以控制组为例,当匹配度较好(定义为匹配分数大于0.8时),客户在主页的平均商品浏览次数为146次,消费金额为1.55元。然而,当匹配不太理想(定义为匹配分数<0.2)时,客户平均会浏览24次产品,仅花费0.49元。
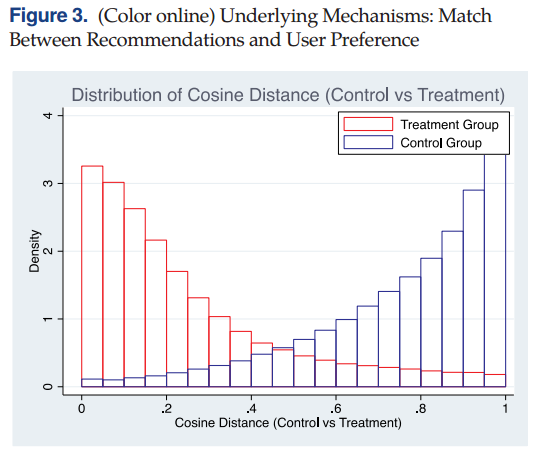
综上所述,限制个人数据的使用可能会显著恶化产品推荐与用户偏好之间的匹配,从而降低电子商务的经济价值。通过对个人数据的使用,电商平台可以显著提升对消费者偏好的推断,并据此推荐相应的产品。这类数据驱动的推荐可以促进匹配并在大范围的商家和产品之间实现有效而均匀的分布。通过这种方式,个人数据可以通过扩大市场规模和培养小众商家来提升电子商务的经济价值。通过个性化分销,商家就会有更强的动力去创新,因为长尾商品能够拥有相对更多的曝光度,即主页推荐的机会。
4.6 数据监管对用户主动搜索的影响
消费者可能采取其他方式来寻求商品信息,主动搜索是消费者当其存在特定需求时在电子商务平台上识别商品最突出的方式。具体而言,在阿里巴巴的APP中,用户可以在关键字栏中输入任何字词并进行后续搜索。当主页推荐与他们的兴趣不匹配时,用户可以进行主动搜索。作者收集了实验对象的所有搜索活动,并检验了数据监管对其主动搜索行为的影响。
研究发现,由于处理组消费者收到的相关推荐较少,他们在搜索栏中搜索的次数明显增加。具体而言,处理组的消费者在实验期间的搜索查询次数增加了7%,在搜索引擎上的浏览次数(PV)增加了7%,来自搜索引擎的产品浏览量的增加弥补了来源于主页推荐减少的PV。此外,平均而言消费者还点击了更多的商品(增长6.3%),通过搜索进行了更多的购买(增长7.1%),从而弥补了推荐带来的部分损失。有趣的是,搜索处理的增加主要集中在有关长尾商品的小众关键字上,与控制组的关键词查询相比,作者观察到处理组用户使用小众关键词的数量增加了7%。与此同时,消费者通过小众关键词查询浏览的PV增加了12%。
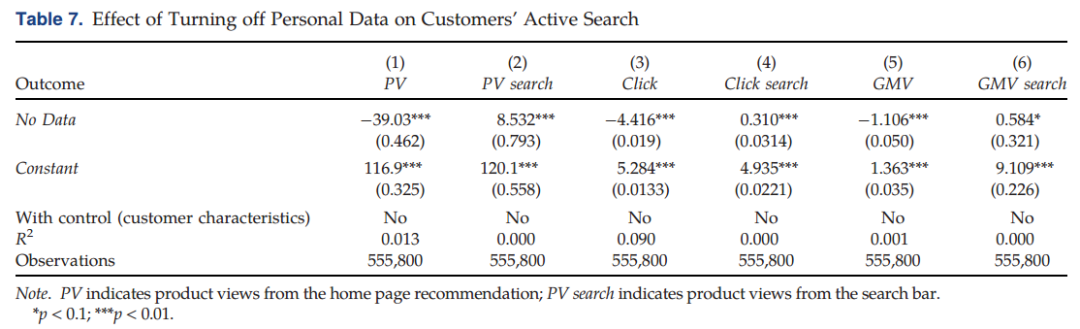
综上所述,一部分用户可以适应监管变化并在监管后进行主动搜索,这可能会部分补偿推荐导致的匹配损失(主要是对长尾商品需求)。然而,在匹配结果(PV和购买量)上仍然存在净损失。由此可得,个人数据的使用能够潜在实现更为相关的推荐,并促进用户和商品之间更好的匹配,并可能会降低用户主动搜索特点商品尤其是长尾商品的必要性,即降低其搜索成本,从而促进长尾商品的创新。
05
总结与讨论
文章结论总结如下:
(1) 当电商平台主页关闭基于个人数据的算法推荐后,商品推荐的集中度显著增加,主页推荐商品种类数量显著减少,且聚焦在较少的头部商品上,长尾商品曝光度急剧下降。
(2) 当电商平台主页关闭基于个人数据的算法推荐后,用户的点击率及对平台交易的参与度显著下降,导致商品交易总额显著下降;用户消费多样性显著下降,用户浏览、点击和购买过程中的消费集中度显著上升。
(3) 当电商平台主页关闭基于个人数据的算法推荐后,小型商家和低信用等级商家商品浏览量和销量下降幅度更大;在商品层面,长尾商品浏览量和销售额下降幅度更大,头部商品浏览量显著提升但销售额显著下降,说明大多数商品的推荐和浏览被“浪费”。
(4) 当电商平台主页关闭基于个人数据的算法推荐后,新用户、购买力较低的群体、女性用户和来自三线城市及以下的用户浏览次数、购买量下降幅度更大。
(5) 当电商平台主页关闭基于个人数据的算法推荐后,用户偏好与主页推荐商品之间的匹配度显著下降,并会降低电子商务平台的经济价值。
(6) 当电商平台主页关闭基于个人数据的算法推荐后,一部分用户会进行主动搜索代替主页推荐的方式,这会部分补偿推荐导致的匹配损失(尤其是对长尾商品的需求上),然而最终匹配度仍存在净损失;即基于个人数据的算法推荐能够促进用户与商户之间的更优匹配,降低用户搜索成本,促进长尾商品的发展与创新。
基于个人数据的算法推荐塑造了互联网商务。2018年,阿里巴巴平台的市场交易额为4.8万亿元人民币(约合7680亿美元),占据中国电子商务市场份额的70%,个性化匹配占了其中的主要份额。而个人数据监管可能会导致GMV的重大损失和数字经济的衰落,并可能会对互联网商务所带动的就业和创业行为产生重大影响,商家尤其是小众商家可能不得不承受收入的损失并改变其经营与创新策略。该实验结果可能会对中国、美国和欧洲的政策制定和电子商务平台的发展产生影响,数据监管的制度设计应当平衡好数据价值和数据隐私之间的关系。
此外,作者也指出本文研究存在一定的局限性,并可以在某些方面加以拓展。
(1)本文着重关注个人数据在互联网商务中的应用价值,此外个人数据还可能以其他方式为经济发展做出贡献,例如应用于在线广告、搜索引擎、金融科技以及数字媒体、娱乐平台等方面。
(2)未来研究可采用实地实验测量的方法,根据具体实践或法律等测试更多政策变量来检验其有效性。例如,研究人员可以运行随机实验来模拟不同保留期限的数据保留策略等。
(3)本文的现场实验侧重于短期数据监管对平台的直接影响。因而,从长远来看,平台可以战略性重新设计搜索界面,以在新的数据监管制度下重新优化匹配算法。
(4)未来研究可结合对数据价值的测量以及对用户隐私选择的研究构建用户的数据价值和隐私成本,以更进一步探索用户异质性从而确定对隐私和数据价值重视程度不同的用户子群体,这类综合考量能够为用户、政策制定者以及平台提供更多信息并帮助其做出更为明智的选择。
Abstract
Personal data have become a key input in internet commerce, facilitating the matching between millions of customers and merchants. Recent data regulations in China, Europe, and the United States restrict internet platforms’ ability to collect and use personal data for personalized recommendation and may fundamentally impact internet commerce.
In collaboration with the largest e-commerce platform in China, we conduct a large-scale field experiment to measure the potential impact of data regulation policy and to understand the value of personal data in internet commerce. For a random subset of 555,800 customers on the Alibaba platform, we simulate the regulation by banning the use of personal data in the home page recommendation algorithm and record the matching process and outcomes between these customers and merchants. Compared with the control group with personal data, we observe a significantly higher concentration in the algorithmic recommendation of products in the treatment group and a very sharp decrease in the matching outcomes as measured by both customer engagement (click-through rate and product browsing) and market transaction (sales volume and amount). The negative effect is disproportionate and more pronounced for niche merchants and customers who would benefit more from e-commerce. We discuss the potential economic impact of data regulation on internet commerce as well as the role of personal data in generating value and fostering long-tail innovations.
推文作者:丁培桓,北京大学经济学院博士生 邮箱:
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}