
论文:Jens Ludwig, Sendhil Mullainathan, Machine Learning as a Tool for Hypothesis Generation, The Quarterly Journal of Economics, 2024,
01
导读
一直以来,经济学的论文套路,都是根据过去文献或者某个理论框架提出假设,但人的认知毕竟有限,能不能把“提出假设”这一步交给算法呢?
要知道,现在,计算机也可以思考,机器学习算法也能认知,特别是那些人类自己可能没注意到的,过去只存在于心理层面的数据,现在越来越多地变成了实际的、可以读取的数据。
因此,本文的目标是提出一种新套路,让计算机算法可以对我们的某个经济现象直接挖掘出研究假设,并且,力图解决现在的算法的不可解释性问题,把“建立解释”这件事交给计算机算法,并应用于经济学中,生成既新颖又可测试、且人类能够理解的假设。如果本算法可以推广,未来的经济学研究将可以关注更多我们平时关注不到的假设。
具体地,本文关注审前司法决策(大概相当于犯罪嫌疑人能不能保释)这一案例。通过构建一个深度学习模型来预测法官的“拘留决定”,算法挖掘发现,被告的面部特征对法官的决策有显著影响,这是以往文献忽略的。紧接着,我们进行实验室实验,验证算法挖掘的正确性,要求受试者在模拟情境中扮演法官并做出拘留决定,观察他们的决定和算法一致性。最后,我们让受试者识别和命名变形图像,来确定影响法官决策的关键面部特征:面部整洁程度和面部饱满程度。
本研究的发现揭示了一个令人惊讶的事实:被告的外观与法官是否决定将其监禁之间存在强烈的关联。例如,面部照片在预测模型中排名较低的被告被监禁的可能性比排名较高的被告高出20.4个百分点,这一差异甚至超过了暴力犯罪与非暴力犯罪被捕者之间的监禁率差异。这一发现不仅对司法决策的理解具有重要意义,而且展示了算法在经济学领域,在揭示人类行为预测中隐藏的复杂模式方面的潜力。通过这种方法,我们可以从丰富和高维的数据中,挖掘新颖且有意义的假设,为科学研究提供新的视角和工具。
在开始本文之前,我必须强调,本文更多地集中在探索相关性,而非深入到因果机制的解析。被告的外观与法官的拘留决定之间存在相关性,但这种关系是否具有因果性尚未得到证实。现在,让我们开始吧。
假设能不能用算法来提出?
02
2.1. 计算机提出假设的标准是什么?
计算机怎样才能有效地提出新的研究假设,并且这些假设应该满足哪些标准?
其一,提出的假设必须是新颖的。必须是一些之前未被注意到的因素,传统的用新方法造老车是没意义的。比如法官如何决定是否将被告拘留,被告的外观,特别是他们的面部特征,就是以前极少被涉及到的假设。
其二,我们必须能够通过实验或其他方式来检验这些假设是否正确。例如,作者们进行了一个实验室实验,让人们在模拟情况下扮演法官,做出关于是否拘留被告的决定。这就是一种测试他们假设的方法。
另外,还有两个额外的标准:可解释性和经验上的可信度。可解释性是指假设应该能够被人们理解和解释。例如,如果有一个假设只是说“这组被告比那组更可能被监禁”,但我们不知道为什么,这样的假设就没什么用。但如果假设是“肤色影响拘留”,这就更容易理解和解释,而且可以应用于更广泛的情况,比如探索肤色是否影响警察的执法决策。
最后,经验上的可信度指的是假设与实际情况之间应该存在某种相关性。虽然相关不等于因果,但解释伪相关也是在推动研究的进步。
2.2. 为什么要让计算机提出假设?
人类构思出的想法本质上是人类能理解的。但作为生成新想法的过程,人类的创造力往往具有个性化特征,因此不一定具备可复制性。一个新颖的假设之所以新颖,是因为有人注意到了许多其他人没有注意到的东西。不同的人从同样的观察中得出不同的结论,甚至同一个人在不同时间也可能注意到不同的事物。人类判断存在很大的“噪音”(Kahneman等,2022年)。而算法产生的假设,在经验上是可行的,在经验上是可行的。例如,算法可以注意到,牲畜都倾向于朝北(Begall, Červen`y, Neef, Vojtěch和Burda,2008),根据心电图中的微妙迹象预测某人是否即将心脏病发作(Mullainathan和Obermeyer,2022),或者预测某个机器设备即将故障(Mobley,2002)。
本文的难度在于,怎么解释算法。这是所有算法在经济学上应用的难题。要知道算法可不是简单的OLS,如果 x 是图像、文本或时间序列,估计的模型(如卷积神经网络)可能有数百万个参数。
03
数据
3.1.司法决策数据
本文使用的数据,来自美国刑事司法系统。包括判刑的决策者、逮捕记录(美国每年有超过1000万人被逮捕)以及其他高维数据,如面部照片、警察佩戴的摄像机和逮捕报告或法庭记录的文本等。
我们重点关注审前听证这个环节。在这个环节中,法官需要在被告被逮捕后的24至48小时内做出决定,即被告在审判前是应该待在监狱还是在家中。这是一个重要的决定,因为案件的处理通常需要数月时间,而且监禁对被告的家庭、生计以及认罪的可能性都有显著影响。此外,被释放的人也可能存在再次犯罪的风险。
根据法律,审前决定应该基于被告如果被释放的逃跑风险或再次被捕风险(Dobbie和Yang,2021),但实际上,法官的决定是随机的。比如:法官的决定也可能取决于种族(Arnold等人,2018, 2020)、法官喜欢的足球队输了(Eren和Mocan,2018)、天气(Heyes和Saberian,2019)、听证会是否在被告的生日那天(Chen和Philippe,2020)等非法律因素。(听起来一个比一个离谱,但这确实是现实。)
3.2. 行政数据
本文的行政数据来自北卡罗来纳州梅克伦堡县,这是该州人口第二多的县(超过100万居民)。选择该地区的原因是,该县在经济条件上与美国其他地区相似(2021年贫困率分别为11.0%和11.4%)。
本文获取的数据,基本就是审前听证会时法官可用的大部分信息。数据主要包括:
1. 梅克伦堡县警长办公室(MCSO)过去三年的逮捕数据,包括被告的人年龄、性别和种族,以及逮捕的指控等。
2. 北卡罗来纳州行政法院办公室(NCAOC)法官审前决策(拘留、释放等)的记录。
3. 北卡罗来纳州公共安全部的数据,包括被告定罪和监禁的信息。
4. 被告的照片,这些照片从肩膀以上捕捉了每个人的正面视图,背景统一是灰色的,如图2所示:
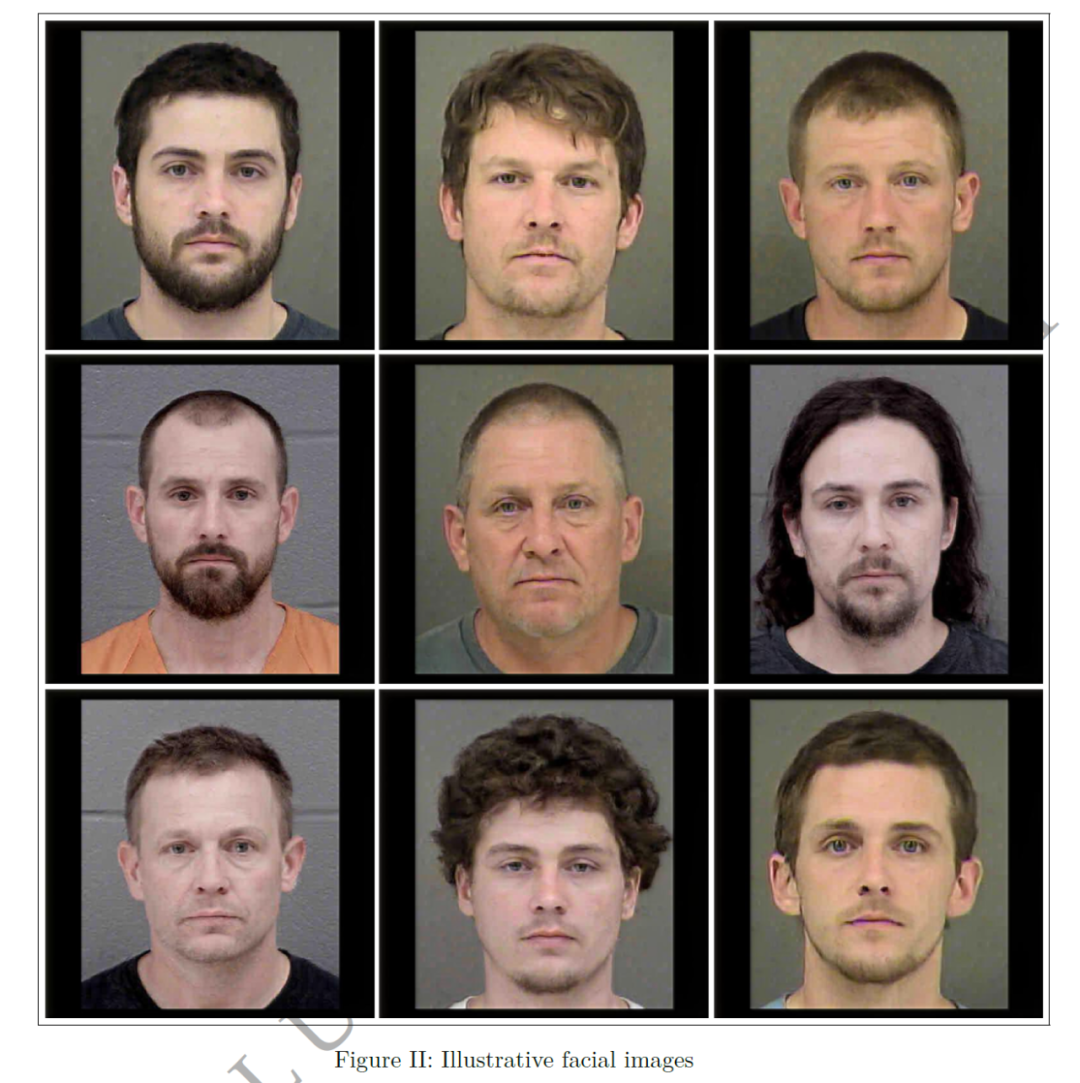
本文使用的数据,时间范围是2017年1月18日至2020年1月17日之间,涉及81,166次逮捕,42,353名不同的被告。经过数据处理,有51,751个观察数据。具体如附录表A.I所示:
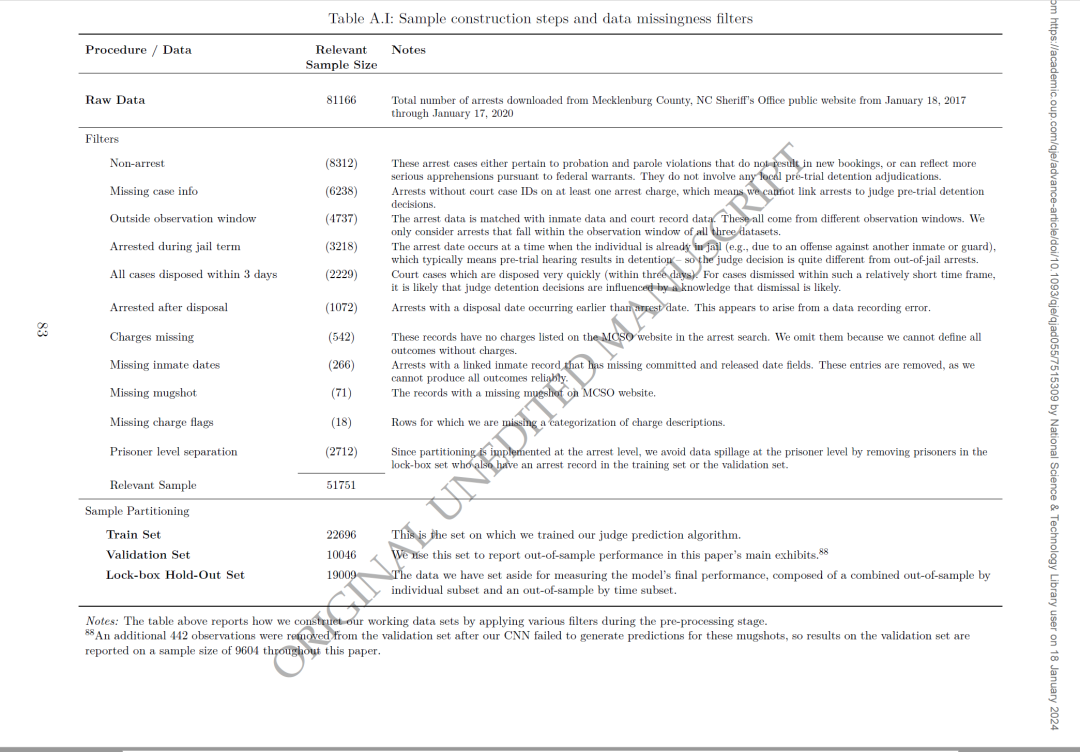
本文的数据进行了如下拆分:(1)训练集:22,696个案件。(2)验证集:9,604个案件,用于报告论文主要展示中的样本外性能。(3)锁箱保留集:19,009个案件,用于最终发表前的验证,避免研究人员过度拟合。
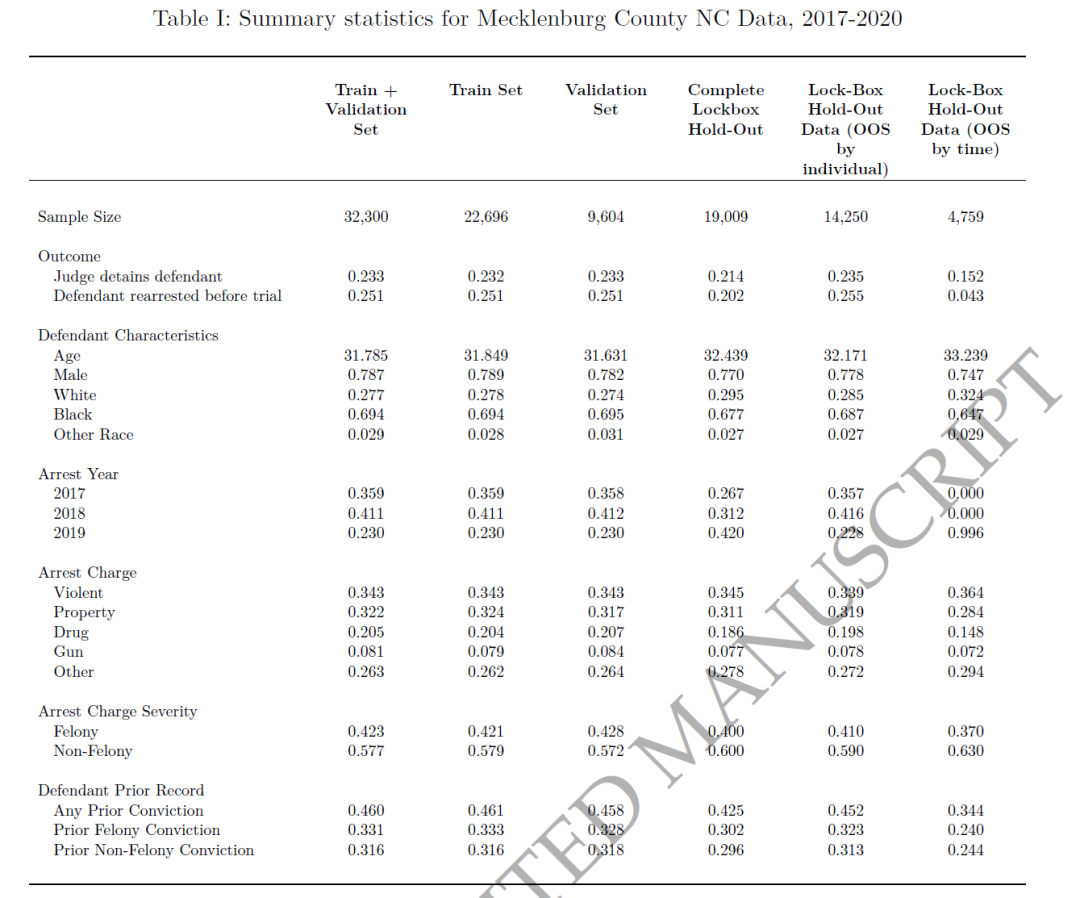
描述性统计结果如表1所示,可以看到,被逮捕的人群在性别和种族方面与整个县的人口结构有所不同,例如男性和黑人居民的比例较高,被捕者的平均年龄为31.8岁,男性占78.7%,黑人居民占69.4%。
3.3.人类标注
为了补充和丰富行政数据中缺失的信息,并评估算法预测与人类决策制定的已知决定因素之间的关系。本文通过在Amazon’s Mechanical Turk或Prolific平台上的研究对象的帮助,对每个案例的面部照片进行标签分配。标签主要有种族、肤色、被告的典型黑人特征程度,以及年龄等,用于与行政数据进行对比和标签质量检查。
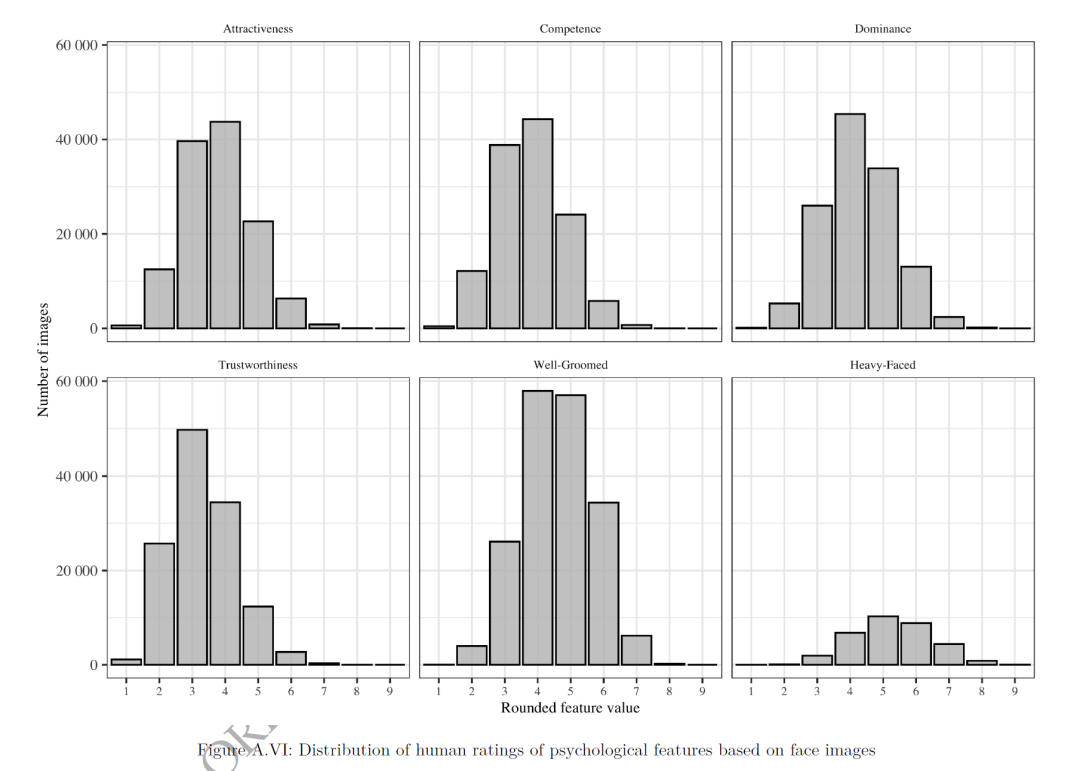
本文还受试者在9点量表上为这些心理特征的图像进行评分。受试者需要对被告的面部照片进行了心理特征的评估,包括可信度、支配力、吸引力和能力等。还要预测预测在给定的一对面部照片中哪一张更可能被拘留,以此来捕捉人们对法官决策影响因素的隐性或直观理解。
面部特征影响法官拘留决定吗?
04
4.1.是什么驱动了法官的决定?
我们使用所有可用的输入数据(x)来预测法官的审前拘留决定(y)。他们构建了两个独立的模型来处理两种类型的数据:一种是使用结构化行政数据(如当前指控、以往记录、年龄、性别)的梯度提升决策树模型,另一种是使用面部照片的原始像素值的卷积神经网络(CNN)模型。这两个模型的信号被汇总,形成一个单一的加权平均模型,用于预测拘留概率。
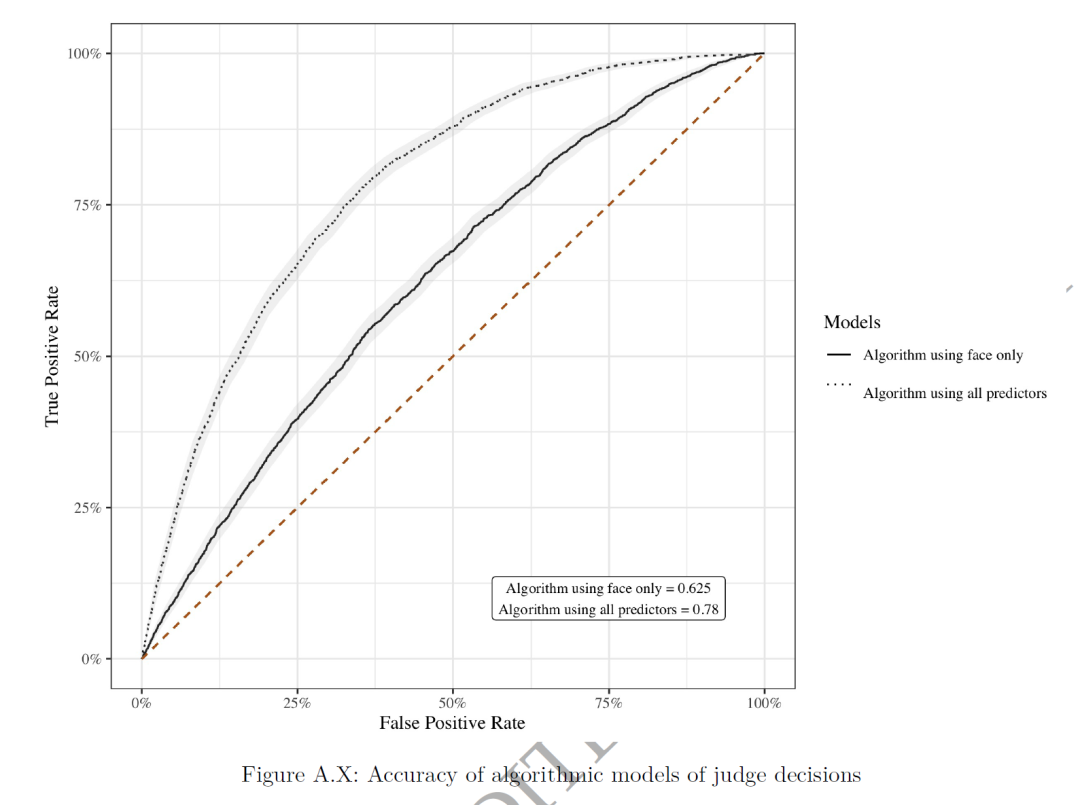
如图A.X所示,算法对法官决定的预测表现通过接收者操作特征(ROC)曲线下的面积(AUC,简单理解,AUC就是机器学习的R方)来衡量,其中,输入数据(X)如果包含所有参数,则算法 mp(x) 的 AUC 为 0.780。而仅使用面部照片构建的算法 mu(x) 的 AUC 为 0.625,这表明面部照片占据了法官决策预测信号的44.6%。即,法官判案,真看脸。
进一步的,对不同特征(如性别、种族、肤色等)的平均拘留率进行比较,发现面部照片算法的预测在底四分位与顶四分位之间的平均拘留率差异为 20.4 个百分点,这一差异相当显著。
4.2.法官会不会误判?
这里的“误判”不是指法官种族歧视,而是说法官看到的面部特征,和他心里理解的面部特征可能不是一个特征。比如,我长得黑,我就危险吗?这是可能造成误会的。
通过回归分析(表3),仅用面部照片的回归系数(及标准误差)为0.6127(0.0460),而使用所有解释变量时(如表3最后一列所示)为0.5735(0.0521)。但是,因为作者只有被释放的被告的犯罪数据被测量,没有被拘留的被告的数据,这会导致面部照片对再逮捕风险的影响相对于其他被告特征的影响大小不切实际地大,这种回归并不可靠。
4.3.算法有没有发现什么新东西?
算法是否只是重新发现了已知的影响人们决策的因素,还是发现了新事物?
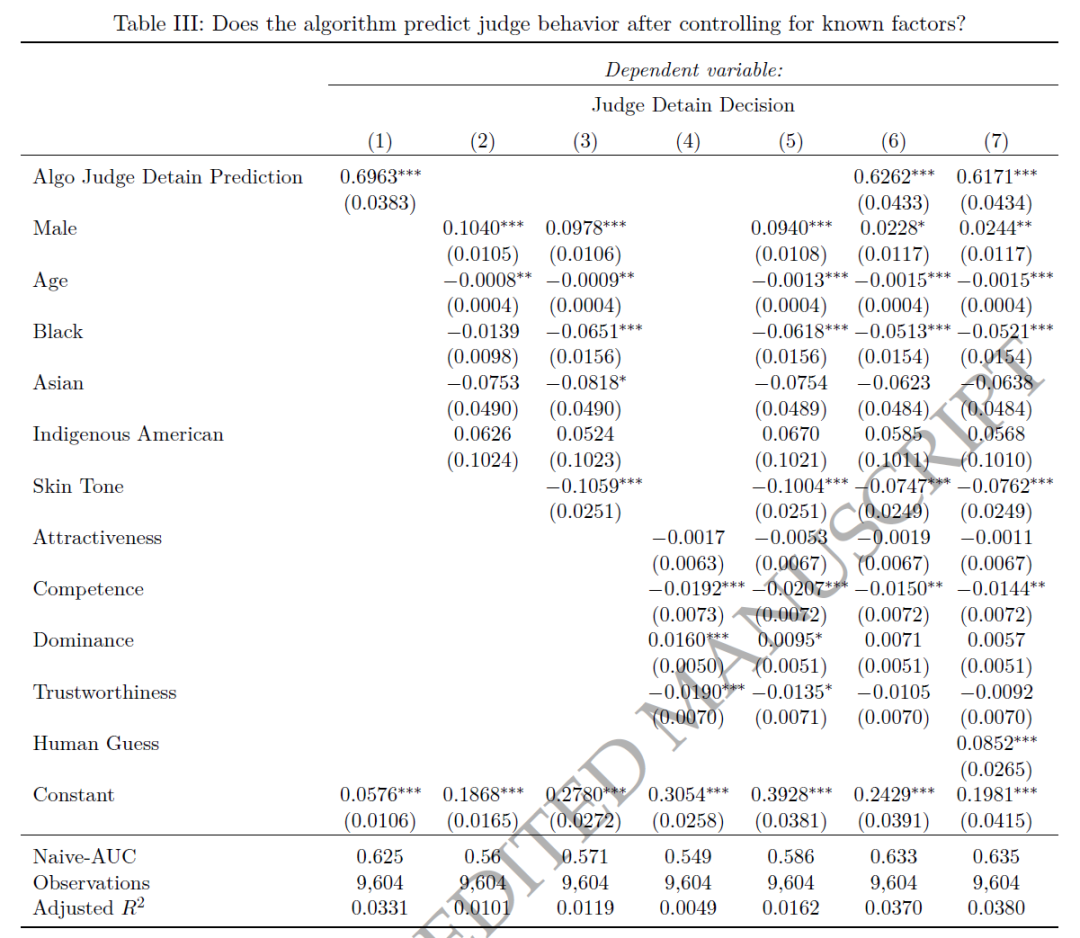
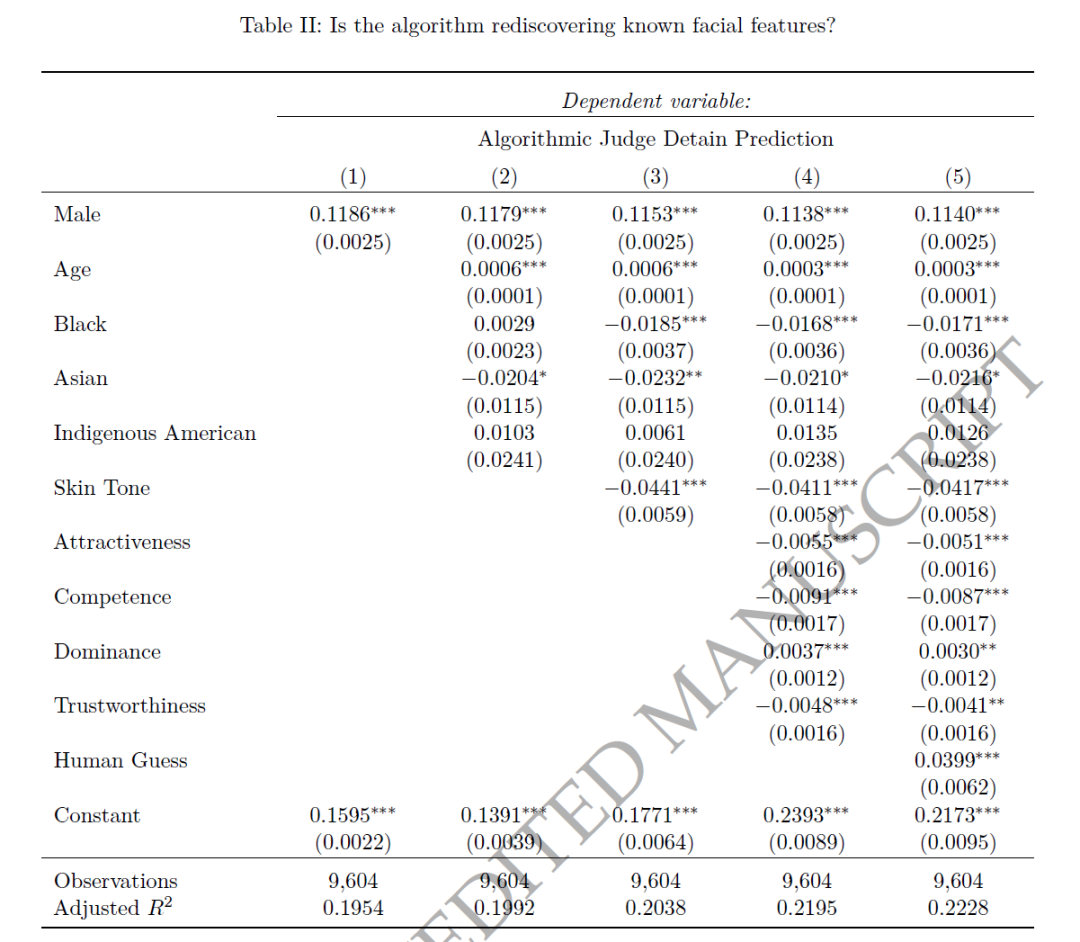
本文进行了两组回归,考虑:(i)人口统计特征,(ii)心理特征,和(iii)人类激励。其中,表2报告了算法的预测中有多少可以被已知特征解释。表3报告了当我们控制已知因素时,算法在解释实际法官决策的预测能力减少了多少。
表2的第(1)至(3)列展示了算法预测与人口统计的关系。预测结果在性别方面差异巨大(男性比女性的预测拘留可能性高出11.9个百分点),年龄影响较小,种族或民族指标不同。以0-1连续量表评分的肤色中,独立评估者判断的肤色最浅的被告比评为肤色最深的被告的预测拘留可能性低4.4个百分点(第3列)。在考虑肤色的条件下,黑人被告与白人相比,预测的拘留可能性降低了1.9个百分点。第(4)列展示了算法预测与以往心理学研究中涉及的影响人们对他人判断的面部特征的关系。这些特征也有助于解释算法对法官拘留决策的预测:独立评估者认为比平均水平更具吸引力、能力或可信度的人的预测拘留可能性分别低0.55、0.91和0.48个百分点,或分别占基准率的2.2%、3.6%和1.8%。受试者认为看起来更具支配力的人的预测拘留可能性更高,增加了0.37个百分点(或1.5%)。
总的来说,算法在预测法官决策方面显示出额外的有效性。算法单独产生的R2(0.0331)明显高于所有已知特征的综合R2(0.0162),以及人类猜测产生的R2(0.0025),表明算法可能发现了一些新的影响法官拘留决策的信号。算法不仅重新发现了以前的研究发现和人类的直觉,还可能识别出了先前研究中未涉及的新信号。
05
怎么解释算法的结果
5.1.解释的挑战在哪?
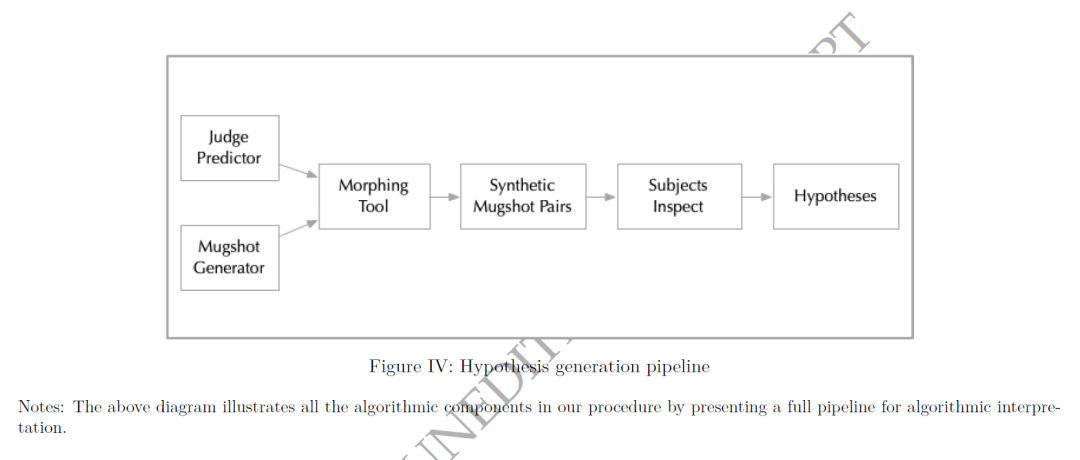
算法(m(x))作为一个复杂的预测器,无法直接观察其内部运作,即所谓的“黑箱”问题。在计算机科学中,一种常见的解决方法是使用梯度。梯度 ∇m(x) = dm/dx (x) 让我们能确定在任何给定输入值下,哪种输入向量的变化最大地改变预测。“saliency maps”算法使用梯度信息来突出显示对预测结果最重要的特定像素。这种方法在诸如动物识别等许多应用中效果良好,因为它可以告诉我们哪些像素值最重要。图IV解释了这种半自动算法的逻辑。
我这里举了个“saliency maps”算法的例子:图III展示如何使用显著性地图来识别影响算法预测(如预测年龄)的关键像素。这个图的左上角展示了一个人的面部照片,这是原始的输入图像。图的右上角展示了同一张面部照片,但这次有些像素被特别突出显示了。这些突出显示的部分是算法认为对预测年龄最重要的像素。换句话说,这些区域对算法判断被照片中的人的年龄起着关键作用。

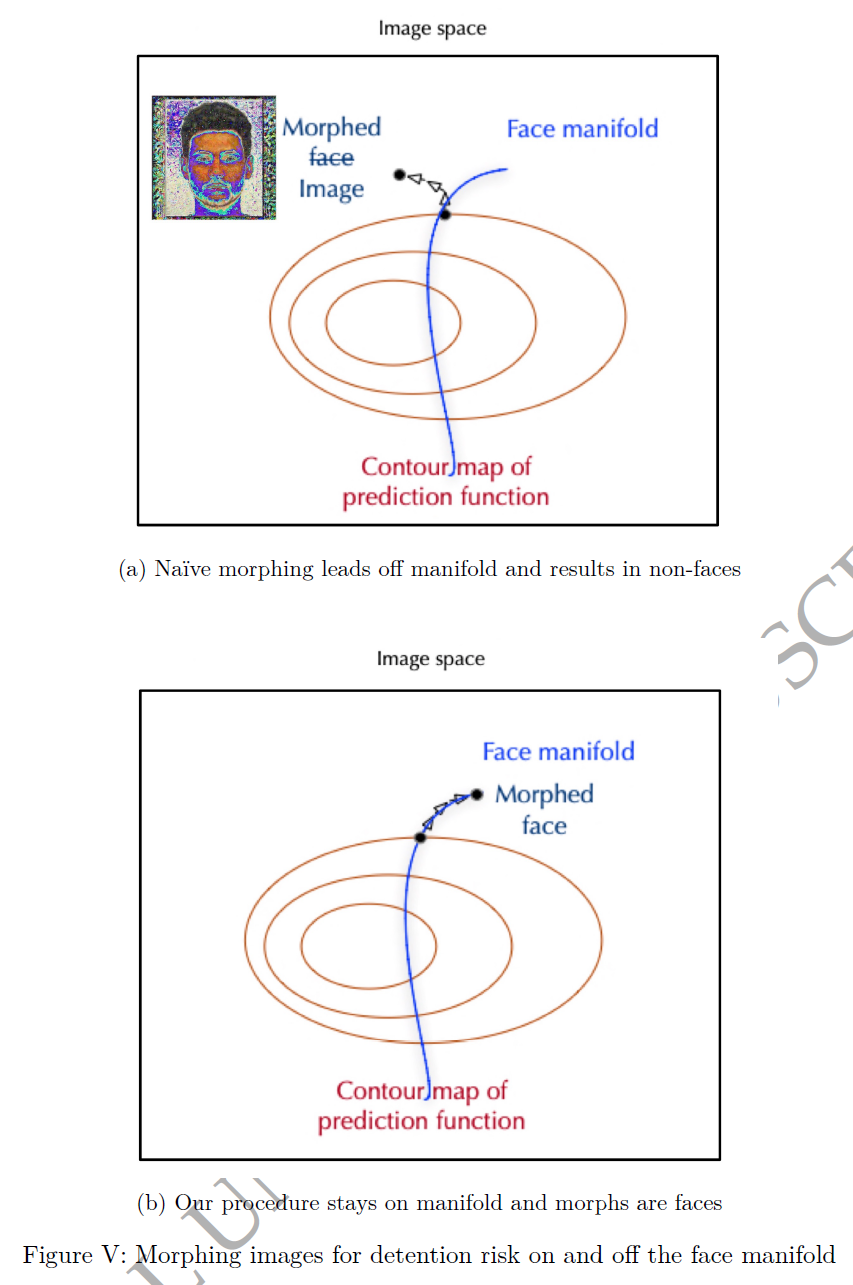
换句话说,我们看图V,这张图更抽象,主要是为了帮助我们理解在图像空间中进行算法变化的概念。图V的面板(a)的框代表所有可能的图像组合的空间。这里的每一个点都代表一个可能的图像,例如一个512×512像素的图像。通过应用基于面部照片的预测器,我们可以在这个空间中识别出具有相同预测特征(如年龄)的所有图像。这就像是在图像空间中绘制出一系列等高线,每一条等高线上的所有图像都有相同的预测年龄。
然而,挑战在于,这个空间中的大多数点并不是真实的面部图像。如果我们仅仅按照算法的梯度变化,我们可能会得到一个不再像真实面部的图像,因为这个变化可能会带我们离开真实面部图像的数据分布范围。这就是图V面板(a)中抽象表示的内容。
在实践中,这意味着通过这种“天真”的变形方法可能得到的图像(如图III左下角所示)可能具有不同的预测结果(如预测年龄不同),但它不再看起来像一个真实的面部图像。这表明需要一种方法来确保新的图像仍然对应于一个真实的面部图像。
5.2.使用生成对抗网络(GANs)来解释
生成对抗网络(GANs)是一种无监督学习,具体的概念这里就不解释了。简单来说,通过使用GANs,我们可以生成真实且具有说服力的面部图像,这些图像不仅仅是简单的复制,而是通过算法预测和数据分布的理解来变形和调整的结果。这样的图像变形能够展示出对结果影响显著的特征变化,例如面部表情、肤色或其他面部特征的微妙变化。通过GAN变形后的图片如图3的右下角d图所示。
5.3.对变形后的图像进行验证
为了验证算法的效果,作者进行了一项实验来验证他们的算法变形过程,让Prolific的工作人员参与验证。受试者需要做以下事情:
1.观察经过年龄变形的图像对:受试者被要求观察由算法生成的50对经过年龄变形的面部图像。这些图像对是从100对中随机选取的,每对图像在某个隐藏维度(在这个实验中是年龄)上有所不同。
2.猜测隐藏特征:受试者被告知每对图像在某个未知的隐藏维度上存在差异,但没有被告知这个维度是什么。他们的任务是猜测哪个图像更多地表达了这个隐藏特征。
3.提供反馈并学习:实验提供了关于哪个图像正确表示隐藏特征(即哪个图像更老)的反馈。前10对图像被视为学习示例,而在剩余的40对图像上测量受试者的准确率。
4.准确度测试:受试者在正确选择年龄较大的图像方面表现出了极高的准确度(97.8%的时间选对了)。
5.描述观察到的差异:最后一步是要求受试者描述他们在图像对中观察到的差异。为了理解和分类这些回应,研究助理将回应分组到语义类别中。
通过这种方法,研究者可以测试算法是否成功地在图像上表达了预期的年龄变化,以及这些变化是否被人类观察者以一种可靠和一致的方式识别和描述。结果表明,Prolific的工作人员有97.8%的正确率。
5.4. 什么面部特征会影响法官的拘留决策?
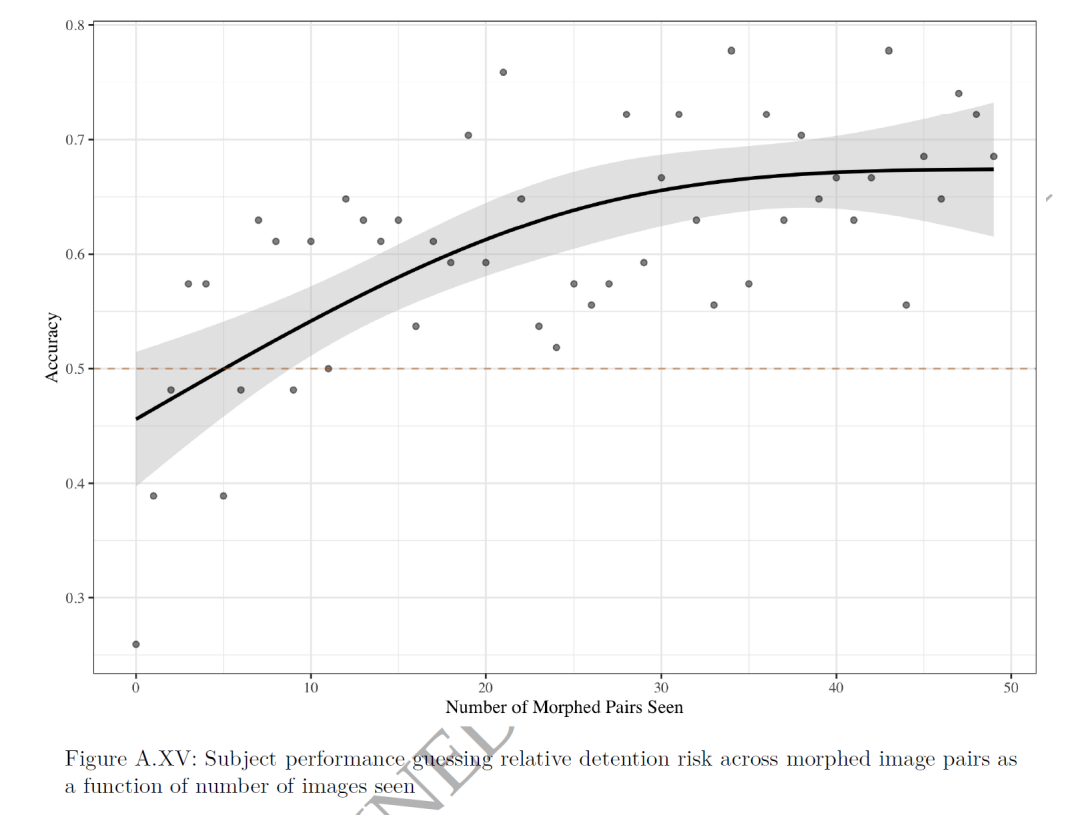
作者让54名受试者观察被GAN处理过的50对变形的图像对,每对图像显示不同的被拘留风险,并让受试者预测哪位被告更可能被拘留。受试者在最开始时准确率不高,但随着时间的推移,他们学会了识别算法试图传达的内容,准确率显著提高。在第20对变形图像对之后,准确率提高了超过10个百分点,并在30对图像对之后达到了67%(准确率曲线如图A.XV所示)。
最终,作者发现,被告的整洁程度是影响法官拘留与否的关键因素。作者又让另一组人对大量面部照片进行整洁度评分,发现整洁度确实与法官的拘留预测有关。
5.5.算法迭代
只发现一个“整洁度”肯定不够,因此本文继续探索,看看是否还有其他面部特征影响法官的决策。受试者在观察新一轮变形图像对时,指出了第二个关键特征,即被告的 “面部饱满程度”。“面部饱满程度”的一标准差变化(1.1946点)与预测的拘留风险降低2.17个百分点相关
检验计算机生成的假设
06
这些面部特征不仅在科学文献中是新的,而且对刑事司法从业者也是如此,这些相关性是否可能反映了一些潜在的因果关系?
6.1.这些假设是否预测了法官实际所做的事情?
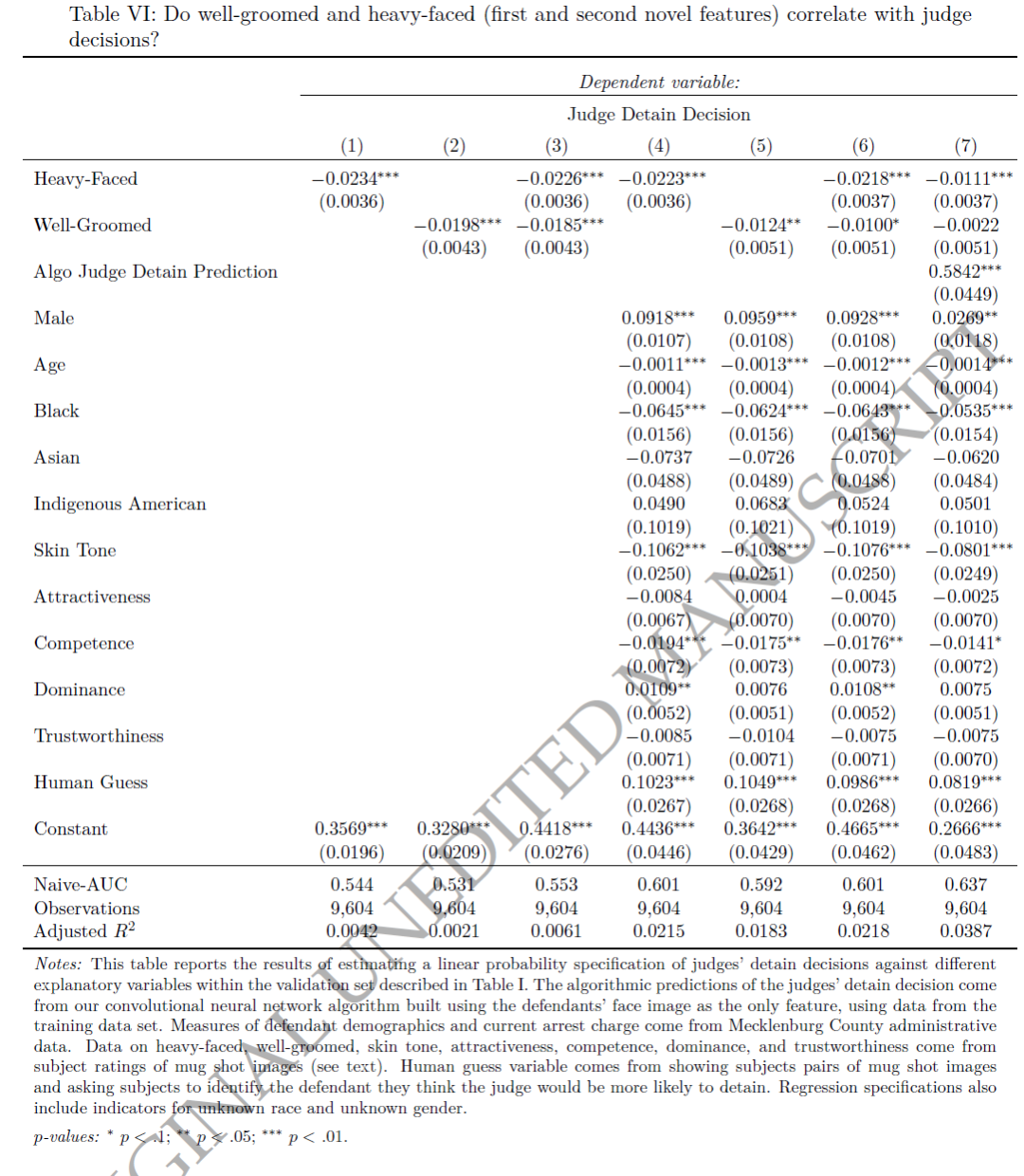
结果如表VI所示。将法官的决定对面部饱满程度进行回归,调整后的 R2 为 0.0042(第1列),而对于整洁程度,这个数字是 0.0021(第2列),两者加在一起的数字等于 0.0061(第3列)。加入所有变量,调整后 R2 等于 0.0218(第6列)。我们两个新假设单独的解释力约为我们从所有变量共同得到的解释力的28%。
第1列中面部饱满程度的系数为−0.0234(0.0036),第2列中整洁程度的系数为−0.0198(0.0043),每个变量一标准差的变化与减少的拘留率相关,分别为2.8和2.0个百分点,或基准率的12.0%和8.9%。最后一列(7)显示,在控制算法预测时,面部饱满程度仍然具有统计学意义。
6.2现实,大家是否认可这个结论?
为了回答这个问题,本文在一个公共辩护人办公室和一个法律援助社团进行了两个小规模问卷。首先提出了一个开放式问题:法官在审前决定拘留或释放被告的依据是什么?然后,向从业者展示了实际的犯罪嫌疑人照片,并请他们猜测哪个人更有可能被法官拘留。接着,向从业者提出了一个开放式问题,询问他们认为被告的外貌对法官拘留决策有什么影响(这个开放式问题的文本词云图如下所示)。

最终,我们发现,尽管从业者的预测比普通研究对象的预测更准确,但他们并没有意识到面部特征是一个很重要的潜在影响因素。这可能是因为这些特征在他们的日常经验和判断中并不明显。
这一发现对于理解法官决策过程中可能存在的无意识偏见或预设概念具有重要意义。它表明,尽管有经验的从业者能够准确预测法官的决策,但他们可能没有完全意识到所有影响这些决策的因素。特别是,算法揭示的关于外貌特征(如整洁和面部饱满)的新发现可能是在刑事司法实践中被忽略或未被充分考虑的。这也是为什么要使用数据驱动方法,因为它可以补充传统的经验和直觉的价值。
07
结论
作者通过纯数据挖掘的方法,让算法去挖掘,去生成,什么会导致法官的拘禁偏好。算法认为是面部的整洁程度和饱满程度。这一假设的提出,是过去文献的空白。想要运用本文这种做法,研究问题或者经济学现象要满足三个条件:
一、这种现象,在常识中被认为是可预测的。
二、收集的数据是图像、音频等高维数据。
三、已有的无监督算法支持去模拟该数据的数据分布,比如本文使用的GAN。
最后,值得强调的是,假设的生成不等同于假设的测试。创造性地产生新假设所需的是为了仔细测试给定假设。本文的出现,可能会激发经济学理论更多关于假设生成的理论和实证工作,这个主题的研究在过去并非经济学主流。
Abstract
While hypothesis testing is a highly formalized activity, hypothesis generation remains largely informal.
We propose a systematic procedure to generate novel hypotheses about human behavior, which uses the capacity of machine learning algorithms to notice patterns people might not. We illustrate the procedure with a concrete application: judge decisions about who to jail. We begin with a striking fact: The defendant’s face alone matters greatly for the judge’s jailing decision. In fact, an algorithm given only the pixels in the defendant’s mug shot accounts for up to half of the predictable variation. We develop a procedure that allows human subjects to interact with this black-box algorithm to produce hypotheses about what in the face influences judge decisions. The procedure generates hypotheses that are both interpretable and novel: They are not explained by demographics (e.g. race) or existing psychology research; nor are they already known (even if tacitly) to people or even experts. Though these results are specific, our procedure is general. It provides a way to produce novel, interpretable hypotheses from any high-dimensional dataset (e.g. cell phones, satellites, online behavior, news headlines, corporate filings, and high-frequency time series). A central tenet of our paper is that hypothesis generation is in and of itself a valuable activity, and hope this encourages future work in this largely “prescientific” stage of science.
推文作者:林泽腾,香港科技大学数据科学学域研究生,南方科技大学访问研究生。
研究方向:自然语言处理算法,大语言模型算法与计算社会科学。
联系方式:
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}