阅读:0
听报道
推文人 | 文惠
原文信息:Juan F. Escobar and Juuso Toikka, 2013. “Efficiency in Games with Markovian Private Information”, Econometrica, Vol. 81, No.5 (September, 2013), 1887-1934.
【摘要】本文通过设计一套基于强马尔可夫性的验谎机制,分析了重复贝叶斯博弈中完美贝叶斯均衡中的收益下限。
引言
曾几何时,友谊地久天长变成了“友谊的小船,说翻就翻”。配上漫画作者喃东尼根据这句网络语绘画的一组风趣幽默的漫画,一时激起多少人心中的共鸣。在教育部、国家语委在北京发布的《中国语言生活状况报告(2017)》中,“友谊的小船说翻就翻”入选2016年度十大网络用语。从小唱着“长亭外,古道边,芳草碧连天”长大的我们,不禁要问:维系一份长久的友谊真的越来越难了吗?还是这是现代人所面临的新的共同困惑?
近年来,如何在信息不对称的前提下保持长期合作关系开始成为博弈论中所关注的新话题。一系列研究长期关系的博弈论文献的基本共识是,保持长期关系的基础是保持沟通。然而,博弈参与人彼此间的沟通,或曰信号传递,并不一定是诚实的。今天推送的这篇文章通过设计一套基于强马尔可夫性的验谎机制,分析了重复贝叶斯博弈中完美贝叶斯均衡中的收益下限。
一个例子
作者开篇以两个进行重复价格竞争的企业为例,解释了这篇文章所着重研究的博弈情境。假设有两家企业,各自的边际生产成本为θ1ϵ{L, H}和θ2ϵ{M, V},并且边际生产成本的排序为LV,即比最高的边际成本还高。这个情境构成了一个双寡头垄断的情境。作者假定,在时期t,每家企业在观察到自己的成本之后,向对方企业发送一个报价且报价不超过购买者的保留价值。购买者从报价更低的企业购买产品。
在这个例子中,存在一个最优串谋方案:在每个时期,具有较低边际成本的企业以垄断价格r进行销售。作者证明得到,存在完美贝叶斯均衡且企业在均衡中的利润可与最优串谋方案中的利润无限接近。这个结果也是这篇文章的核心结论。而均衡的实现依赖于作者所设计的一套基于强马尔可夫性的验谎机制,作者称之为“可信报告机制”。
在上述例子中,“可信报告机制”的运作如下。假设时间期限T足够大并且是有限期。企业对未来的利润不打折扣。假设企业仅报告其成本,机制会自动为报告最低成本的企业设置价格r,为另一家企业设置价格r+1。假设两家企业边际成本的初始分布为两种状态的概率各为二分之一。如果两家企业均诚实报告各自的成本,那么当T足够大时,两家企业各自的利润近似为v1=(r-L)/2+(r-H)/4和v2=(r-M)/4。“可信报告机制”会在每期检验企业报告的真实性。如果企业没有通过检验,那么下一时期企业被取消报告资格,机制会通过模拟企业过去的成本记录随机产生一个报告。“可信报告机制”以很高的概率满足以下两个条件:
I. 无论另一家企业的报告策略为何,诚实报告的企业总是能够通过检验;
II. 无论另一家企业的报告策略为何,诚实报告企业的已报告的成本的分布与两家企业同时诚实报告的情境下的成本分布相同。
在这个机制中,每家企业的期望利润接近v1和v2,并且这种利润组合(v1, v2)是帕累托有效的。这也就意味着,在“可信报告机制”中,期望均衡利润可以与帕累托有效收益接近。由于每家企业的成本演化过程是彼此独立的马尔可夫过程,作者利用强马尔可夫性和独立性设计了满足上述条件的统计检验,也可以理解为“验谎机制”。这个“验谎机制“的设计正是这篇文章的核心贡献之一。为了使“可信报告机制”具有自我履约性,作者还配套设计了非均衡路径上的惩罚机制,称之为“胡萝卜与大棒”方案。
模型
作者建立的模型是一个有n个参与人、不完全信息的无限期重复博弈模型。这个无限期重复博弈的阶段博弈是一个有限期的不完全信息博弈:
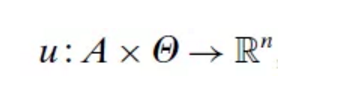
其中,A是n个参与人的行动集,Θ是n个参与人的类型集,u代表参与人的效用函数。作者假设每个参与人的类型θi是参与人的私人信息。在每个时期t,阶段博弈又分为四个子阶段:
t.1 每个参与人i各自观察到自己的类型θi;
t.2 参与人同时发出关于自己类型的公共信息mi;
t.3 一个公共随机装置产生一个在[0,1]上的随机数ω;
t.4 每个参与人在完美监测下采取行动ai.
每个参与人i的类型θi依据各自的马尔可夫链(λi, Pi)进行演化,其中λi是初始分布,Pi是转移矩阵。作者假设n个马尔可夫链是独立的,并且每个马尔可夫链都不可约。定义每个参与人i的静态纯策略最小最大值为
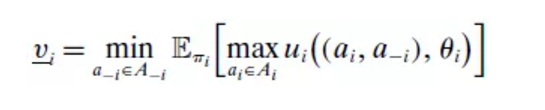
这是参与人i的对手选择任何行动a-i时,只要参与人i正确预见到a-i并对它作出最佳反应就能得到的收益下限,即参与人i的保留效用。其中,πi为马尔可夫链i的平稳分布。
作者在阶段博弈中的第4个子阶段t.4阶段引入了先前介绍的“可信报告机制”以及配套的惩罚机制。在该模型中,参与人通过“可信报告机制”中的“验谎机制”的检验需要满足两个条件:(1).参与人所报告的自我类型转变的边际分布收敛于真实分布(即符合强马尔可夫性);(2). 参与人所报告的自我类型的转变独立于其他参与人所报告的自我类型的转变(即符合独立性)。当参与人i未通过验谎检验时,博弈启动惩罚机制。在惩罚机制中,其他参与人首先对参与人i实施L期的最小最大化策略(minmax plyer i),即惩罚机制中的“大棒”阶段。之后,惩罚机制进入“胡萝卜”阶段,参与人继续照常各自发布报告,且可信报告机制继续运行。
主要结论
本文的一个主要结论是,当允许对每个参与人采取不同的惩罚措施,且参与人的折现因子大于一个固定值时,存在一个完美贝叶斯均衡,其中在均衡路径上参与人的期望连续收益的下限高于参与人i的静态纯策略最小最大值。这个结论给予我们的启发是,重复互动和有效的沟通也许可以克服自利行为和不对称信息的影响而带来长期合作的结果。“可信报告机制”的直观行为解释是:如果一个参与人对于他个人情况的报告历史看起来真实可信,那么就接受他的报告并根据他的报告采取相应行动。如果一个参与人的报告看起来不可信,那么在采取行动时就不采纳他的报告,作为对他的惩罚。等过一段时间,当曾经虚假报告的参与人积累起足够的信用时,他的报告还可以被重新采纳。
结语
这篇文章的主要贡献在于设计出了一套可以支持实现长期合作的可信报告机制,并且允许在该长期关系中参与人的类型进行基于马尔可夫过程的演化。如作者所总结,文章初步分析了这种博弈中完美贝叶斯均衡中的收益下限,但是对于完美贝叶斯均衡集的更充分刻画还有待展开。此外,本文研究的博弈假定参与人类型的演化遵循马尔科夫过程,即外生的。未来还可以进一步研究参与人类型的演化是内生时的情况。
Abstract
We study repeated Bayesian games with communication and observable actions in which the players’ privately known payoffs evolve according to an irreducible Markov chain whose transitions are independent across players. Our main result implies that, generically, any Pareto-efficient payoff vector above a stationary minmax value can be approximated arbitrarily closely in a perfect Bayesian equilibrium as the discount factor goes to 1. As an intermediate step, we construct an approximately efficient dynamic mechanism for long finite horizons without assuming transferable utility.
KEYWORDS: Repeated Bayesian games, efficiency, Markov chains

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}