阅读:0
听报道
推文人 | 阳梦倩
原文信息:Bajari P , Nekipelov D , Ryan S P , et al. Machine Learning Methods for Demand Estimation [J]. American Economic Review, 2015, 105(5):481-485.
在计算机科学与统计领域,学者对消费者行为的建模十分感兴趣,这些研究利用了消费记录大数据的特点,并且建模结果被零售、健康护理公司和互联网行业广泛应用于商业决策。文章比较了这些模型与标准计量模型对需求的预测效果,希望找到一些实用的工具,帮助应用计量经济学在观测值和变量数量都较大时估计需求。
文章尝试比较计量模型和机器学习对商品需求量的预测效果,无论计量模型还是机器学习都可以采用需求预测函数:


bagging和随机森林 回归树是一个将特征空间划分为一系列的超空间的函数,并将各个超空间内的均值作为函数值。从某种意义上看,回归树就是一系列的固定效应。
进一步地,回归树还可以扩展为bagging和随机森林。bagging对数据进行B次有放回的抽样,然后用这B个子样本分别训练模型,得到B个回归树,最后将这B个回归树的预测结果均值作为最终的预测值。随机森林与bagging相似,只是在划分空间时加入了随机性,只有部分的解释变量(X 的子集)被考虑用来划分空间。
集合模型将上述八个模型进行组合,因变量与前相同,而自变量是上述8个模型对因变量的预测值,回归得到一个新的预测模型
文章使用便利店销售量数据对机器学习模型和线性计量模型进行实证比较。他们发现,机器学习模型在不低于线性计量模型的样本内拟合效果的情况下,普遍比线性计量模型有更好的样本外预测效果;而且,集合模型的样本外预测效果比其中任何模型都要好。
他们采用的是某连锁便利店长达6年的咸味零食销售数据,每条观测值记录的是商品j第t周在便利店m的情况,共有1510563条观测,包含3149个独立商品。qjmt 是咸味零食j第t周在便利店m的销售数量;如果qjmt=0,可能是因为没有售出或因不在库存中而观测不到。价格Pjmt被定义为商品j第 t周在便利店m的加权平均价格。除了价格和销售量,这个数据还包含了商品的属性(例如品牌、净含量、口味、开口方式、烹调方式、包装大小、脂肪含量和咸味程度)和促销变量(是否促销、展示方式和特征)。
因变量是周销售量的对数,而自变量是价格的对数、商品属性变量、促销变量、便利店固定效应和周固定效应。除了Logit模型不使用固定效应外,其他模型都使用相同的自变量。
为了估计和比较模型,文章将数据分成了三个集合:训练集、验证集和测试集。首先,用训练集估计模型;然后,用验证集估计集合模型中的各个模型所占的权重,缓解训练模型的过度拟合问题,例如,线性计量模型样本内的拟合效果往往比样本外好,在训练集上的拟合误差十分小,如果仍用训练集估计集合模型中的权重,估计结果会给予线性计量模型较大的权重,导致集合模型在测试集上的预测效果较差;最后,我们考察各个模型在测试集上的预测效果。其中,25%的数据作为测试集,15%的数据作为验证集,而剩下60%的数据作为训练集。
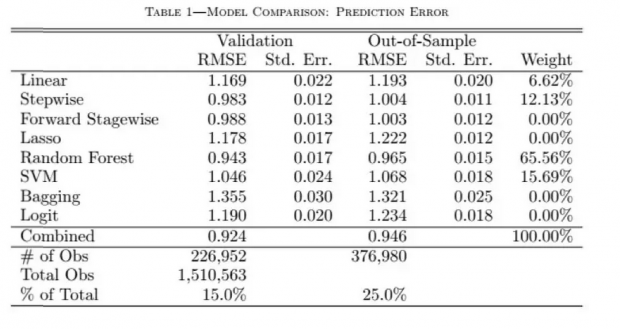
表格显示的是各个模型在验证集和测试集上的根均方误,以及各个模型在集合模型中所占的比例。从测试集(Validation)上的预测误差看,最好的两个模型是随机森林(Random forest)和支持向量机(SVM),而集合模型(Combined)则比其它任何模型都好。随机森林在集合模型的权重是最大的(65.56%),其次是逐步回归法(Stepwise)和支持向量机。值得注意的是,集合模型没有简单地只选择均方误差最小的模型,说明其他模型也包含着重要的信息有助于集合模型进行预测。
Abstract
In this paper, we review and apply several popular methods from the machine learning literature to the problem of demand estimation. Machine learning models bridge the gap between parametric models with user-selected covariates and completely non-parametric approaches. We demonstrate that these methods can produce superior predictive accuracy as compared to a standard linear regression or logit model. We also show that a linear combination of the underlying models can improve fit even further with very little additional work. While these methods are not yet commonly used in economics, we think that practitioners will find value in the flexibility, ease-of-use, and scalability of these methods to a wide variety of applied settings.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}