阅读:0
听报道
推文人 | 冯显骏
推文信息:Weifeng Zhong, Julian TszKin Chan. Reading China: Predicting policy change with machine learning. AEI Economics Working Paper Series
为什么要读
改革开放以来,中国经济已持续了长达四十年的高速增长。与此同时,政府这一只“看得见的手”一直扮演着举足轻重的角色。自新中国成立以来,中央层面的经济规划以及产业政策就主导了中国经济的长期增长路径与增长模式。而经济政策的边际变动与中国经济的周期性波动之间的关系更是被学术界、金融界乃至实业界所密切关注。政策研究已经成为学术机构、政府部门、智库、金融机构以及实体企业中一项极为极为重要的工作。有关“供给侧改革”、“一带一路”等近年热点政策话题的研究可谓汗牛充栋。
然而,尽管政策对于中国经济具有如此重要的影响,我们仍缺乏一套能够定量刻画政策变动的指标体系。这也成为本文两位作者的研究动机。虽然计量经济学已经贡献了大量定量评估政策影响的方法,但当我们描述政策本身,尤其是分析政策在边际上的变动时,我们大多只能停留在文字描述以及定性分析的层面。而单纯的定性层面的讨论存在局限性。首先,在中国,多个领域、目标各异甚至相互矛盾的政策往往会在同一时期共存。此时,如果我们想要找出占据主导地位的政策,定性分析往往会导出众多结论,缺乏精确性。其次,政策的拐点对整个市场,尤其是金融资产的价格具有重要意义。准确地判断政策拐点,预测未来政策走势,是政策研究的核心目标。本文提出的量化政策变动的方法能够在判断政策拐点方面为定性分析提供有益补充。
本文试图利用前沿的机器学习方法构建出一套能够定量刻画中国自上世纪50年代至今政策变动的指数体系。简单概括,首先两位作者认为刊登在人民日报上的文章具有重要政策含义,而头版文章所指向的政策具有最高优先级别。找到头版文章区别于非头版文章的特征,我们就能预测一篇新文章有多大可能出现在头版。这正是机器学习的二分类问题。接下来,作者利用自然语言处理技术将历史上人民日报的所有文章转化为可处理的数据,然后这些数据来训练神经网络模型。最后作者拿训练得出的模型来预测新文章是否会出现在头版。预测准确性的变动幅度就是我们关心的政策变动幅度。将这一思路运用在滚动的时间窗口中,我们就得到了一个反映政策变动的时间序列指标。
本文的研究建立在三大领域的文献之上:政治传播学(政府会通过媒体传递政策信息,媒体会受到政治影响)、媒体经济学(媒体能够有效影响大众的偏好、信仰与行为)以及文本分析与机器学习(目前已有大量文献将文本分析与机器学习应用于政治学与经济学研究中)。这篇文章是将前沿方法应用于社会科学的一次有益尝试。
读什么
作者首先用相当可观的篇幅论证人民日报是中国政策的重要宣传阵地。人民日报不仅反映当前中央层面的政策方向,甚至经常能在政策转向前领先释放出政策信号。这是由人民日报的政治级别、人事任命以及编辑出版流程所决定的。作者举了一个中国人民耳熟能详的例子来说明其对政策的预示作用。1977年2月,人民日报发表了“两个凡是”这一臭名昭著的言论;而在1978年5月,“实践是检验真理的唯一标准”横空出世,领先改革开放政策这一重大政策转向数月之久。尽管一些学者指出改革开放以来,中国新闻媒体逐渐走上市场化道路,转为盈利导向的经营模式,但是大量证据显示人民日报仍凭借其独特的地位持续扮演着中国政策的风向标。
本文的数据为人民日报1946年创刊至今的全部原文,共包含190余万篇文章。每一篇文章构成数据集中的一个观测值。对于每篇文章,数据集中包含它们的正文与标题、刊登的日期以及文章所在的版面位置。头版文章占据全部文章数量的11.7%,这些文章代表着历史各个时期的优先政策。“是否刊登在头版”是“政策重要性”的代理变量。作者还构建了多个变量:文章是否在周末刊登、标题的长度、正文的长度、当天报纸刊登的文章数量、当天报纸刊登的头版文章数量。本文的数据呈现以下结构:
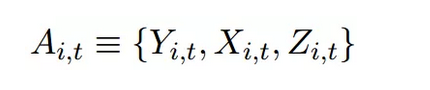
即,在t时期的第i篇文章(A)可以被它的全文内容(X)、是否在头版(Y)以及其他作者构建的特征(Z)所定义。
如何读
通俗地来讲,本文模型的逻辑十分简单。我们把机器学习模型比作一位记忆力惊人的读者,他正在按照时间先后阅读人民日报。假设现在他读完了一整年的报纸,并对哪些文章能够出现在头版,哪些文章不会出现在头版产生了深刻体会。然后,突然有一期全新的报纸摊开在他面前,他想检测一下自己的理论。于是他想办法打乱了每篇文章的版面顺序,然后阅读每篇文章并猜测这篇文章会不会出现在头版,最后将自己的猜测与这篇文章真实的版面对比。如果他猜的头版文章没有一篇真的出现在头版,就很大概率说明政策优先级已经发生了根本性的改变;如果他全部猜中了头版文章,则说明之前的政策还在延续之中,没有发生大的转变。
具体来看,本文首先将时间整个时间区间按照季度划分为小区间,然后将训练的窗口定义为20个小区间(即20个季度,5年):
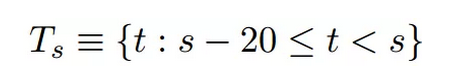
这一划分就像之前提到的热心读者站在时点s,读完了所有时间窗口Ts里的人民日报。
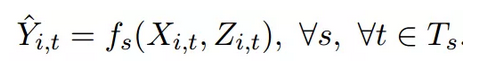
接下来,作者使用分层抽样在每个训练窗口选取80%的样本作为训练集与验证集,其余20%留作测试集。训练集用来训练模型,验证集用来防止过拟合问题,而测试集则是用来检测在特定训练窗口中模型拟合的好坏。在每一个训练窗口中,作者都试图寻找一个具有以下形式的分类模型:
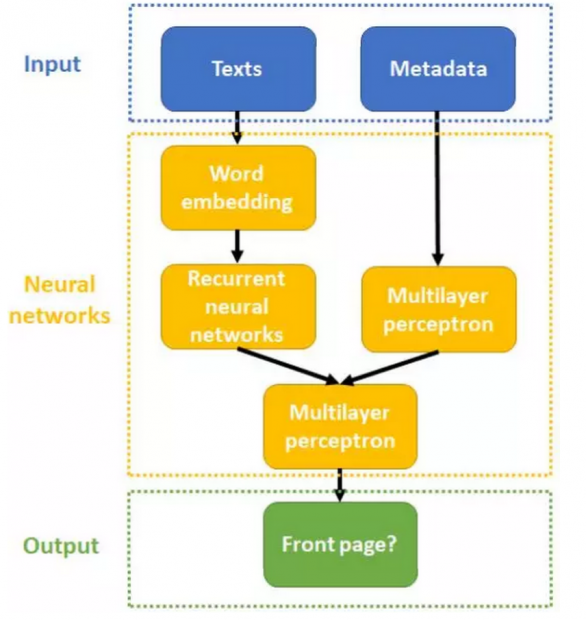
也就是利用文章的全文与作者构建的特征来预测文章是否会被刊登在头版。分类模型fs包含了词嵌入(Word Embedding)、循环神经网络(Recurrent Neural Networks)与多层感知器(Multilayer Perceptron Layers)三大模块。关于这三大模块的原理,原文也有简要介绍,感兴趣的读者可以参看原文或相关文献。
最后,作者根据每一个时间窗口模型拟合的优劣程度来构建出最终的政策变动指数(PCI)。模型优劣程度的衡量方法选取了二分类问题中常用的指标F1分数:
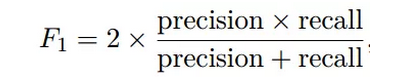
F1分数可以看作是模型准确率(precision)和召回率(recall)的一种加权平均,处于0和1之间。在此基础上,第s期的政策变动指数等于模型在s期的拟合优劣与在s期之前一个训练窗口期的拟合优劣之间的差异,即:
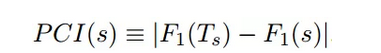
这一差异越大,说明在s期之前一个窗口期训练得到的模型,在窗口期和s期的预测表现的差距越大。这意味着s期内的人民日报的头版文章特征发生了显著改变,用s期之前的数据训练出的模型已不能很好地预测s期的头版文章。因此,人民日报可能在调整自己的政策宣传重点,中国的政策也可能在发生着重大转变。
作者用于构建政策变动指数的方法显著区别与传统的监督学习。按照传统的监督学习方法,作者应该首先为每篇文章手动标注上他的政策主题,再利用监督学习模型来预测新文章所归属的政策主题以及该主题的优先级。但这一方法有两大不足之处:手动标注需要耗费大量人力;手动标注会参杂进人对政策的主观判断。作者认为自己的方法很好地避开了这两个问题,具有很大的优势,可以被广泛用于类似主题的研究。但同时,作者也承认这一方法也受制于所使用的数据,仍然具有很多缺陷,比如人民日报可能对某些政策转变并不予以报道。
读出了什么
作者将本文最核心的结果——政策变动指数和新中国历史上的重大政策事件绘制在了一幅图里:
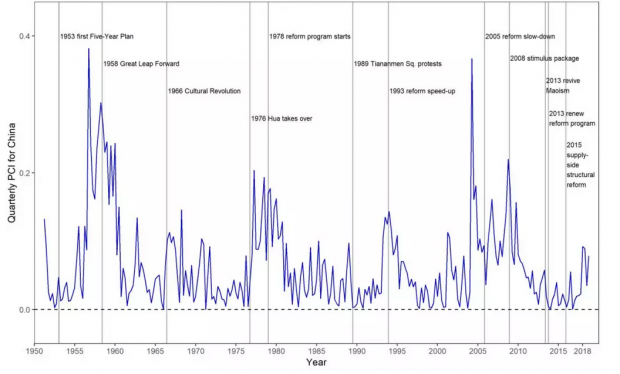
不难看出,这个指数在1958年大跃进、1978年改革开放、1993年改革开放进一步加速等重大政治事件前都快速上升,具有领先性。因此政策变动指数对短期内的政策变化具有一定的预测价值。但需要指出的是,在2008年四万亿以及最近的供给侧改革等政策事件前,政策变动指数并未出现明显变化,显示出了该指数的局限性。作者认为这主要是由于某些政策如四万亿具有被动性,是对外部冲击的反应,同时供给侧改革等政策反映的更多是对之前政策的延续。
最后,作者举了1993年改革加速、2004年改革减速、以及2012年新一届领导班子以来的中国政策变化三个案例来具体分析每一次政策变动过程中,哪些主题的热度在上升,哪些主题的热度在下降。通过这些主题的热度的相对变化,我们就能窥见每次政策变动的方向。
本文作者使用独特的人民日报全文数据,利用机器学习模型构建出反映中国政策变动的PCI指数。这一指数对中国短期政策变动具有预测意义。同时,作者构建指数的方法能够被广泛应用于类似课题,对未来的研究具有启发性。作者会在每个季度对PCI指数进行更新,感兴趣的读者可以去网站查看()
推文作者:冯显骏,北京大学汇丰商学院
Abstract
For the first time in the literature, we develop a quantitative indicator of the Chinese government’s policy priorities over a long period of time, which we call the Policy Change Index (PCI) for China. The PCI is a leading indicator of policy changes that covers the period from 1951 to the third quarter of 2018, and it can be updated in the future. It is designed with two building blocks: the full text of the People’s Daily — the official newspaper of the Communist Party of China — as input data and a set of machine learning techniques to detect changes in how this newspaper prioritizes policy issues. Due to the unique role of the People’s Daily in China’s propaganda system, detecting changes in this newspaper allows us to predict changes in China’s policies. The construction of the PCI does not require the understanding of the Chinese text, which suggests a wide range of applications in other settings, such as predicting changes in other (ex-)Communist regimes’ policies, measuring decentralization in central-local government relations, quantifying media bias in democratic countries, and predicting changes in lawmakers’ voting behavior and in judges’ ideological leaning.

话题:

0
推荐
财新博客版权声明:财新博客所发布文章及图片之版权属博主本人及/或相关权利人所有,未经博主及/或相关权利人单独授权,任何网站、平面媒体不得予以转载。财新网对相关媒体的网站信息内容转载授权并不包括财新博客的文章及图片。博客文章均为作者个人观点,不代表财新网的立场和观点。
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}