
图片来源:
ChatGPT-4 DALL·E
原文信息:
Chen, J., Tang, G., Zhou, G., & Zhu, W. (2023). ChatGPT, Stock Market Predictability and Links to the Macroeconomy. Available at SSRN 4660148.
参考资料:
Loughran, T., & McDonald, B. (2011). When is a liability not a liability? Textual analysis, dictionaries, and 10-Ks. The Journal of Finance, 66(1), 35-65.
Veronesi, P. (1999). Stock market overreactions to bad news in good times: a rational expectations equilibrium model. The Review of Financial Studies, 12(5), 975-1007.
Garcia, D. (2013). Sentiment during recessions. The Journal of Finance, 68(3), 1267-1300.
01
导读
随着大数据时代降临,金融经济学领域逐渐采用自然语言处理(NLP)技术,特别是大型语言模型(LLMs),从复杂的财经文本中提取对股市重要的信息。相较于传统的文本处理方法,如词袋模型或基于字典的情感评分法,LLMs通过预训练模型和词嵌入技术,在捕捉文本语法和理解深层语义方面展现出明显优势。这标志着金融分析方法的一大进步,为投资者和研究人员提供更准确的市场洞察,提升了金融市场研究的深度和广度。
数据说明
02
本研究使用Factiva数据库提供的《华尔街日报》1996年1月至2022年12月的头版新闻数据集,包含标题新闻和商业金融快讯,共计84535篇文章。
表1 《华尔街日报》新闻摘要统计

表1为《华尔街日报》新闻数据集的描述性统计,基于ChatGPT-3.5模型的估计,新闻被分类为“坏消息”、“中性消息”和“好消息”,分别代表市场的下跌、不确定和上涨。全样本数据显示月均新闻量为260.91条,波动显著且新闻分布呈轻微左倾。其中,“坏消息”月均32.76篇,表现出一定的正偏度;“中性消息”以每月月均181.75篇占据主导;“好消息”月均46.40篇,整体呈现轻微的正偏度。以上信息揭示了新闻情绪的分布特征及其波动情况。
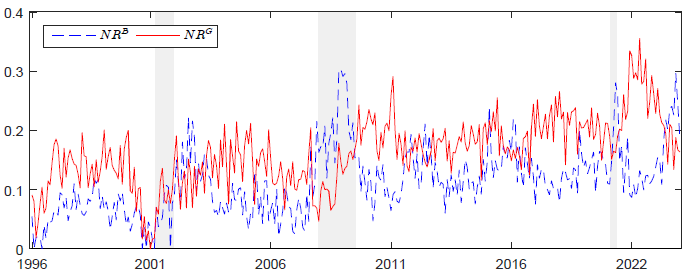
图1 新闻比率时间序列图
图1描述了1996年1月至2022年12月期间,《华尔街日报》好消息比率(![]() )与坏消息比率(
)与坏消息比率(![]() )的月度变化趋势。
)的月度变化趋势。![]() 与
与![]() 分别代表ChatGPT-3.5识别出的每月好消息、坏消息的比例,这两个指标反映了新闻情绪与股市涨跌的关联情况。图中的垂直灰色条形代表NBER确定的经济衰退期,提供了新闻情绪与经济周期间相互作用的视角。
分别代表ChatGPT-3.5识别出的每月好消息、坏消息的比例,这两个指标反映了新闻情绪与股市涨跌的关联情况。图中的垂直灰色条形代表NBER确定的经济衰退期,提供了新闻情绪与经济周期间相互作用的视角。
03
实证分析
本研究利用ChatGPT-3.5通过设计提示语处理新闻标题,以预测股市走势,并将其与更先进的ChatGPT-4进行比较,后者在语言处理任务上显示出更高的准确性和可靠性。文中采用“零次学习”和“少次学习”策略,通过实例增强模型的学习能力,并针对处理大量未分类新闻标题的挑战,通过模型微调来优化性能。研究还涉及对BERT和RoBERTa模型的微调,并比较它们预测股市的能力。此外,作者使用BERT、RoBERTa、ChatGPT-3.5和ChatGPT-4模型提取新闻标题的向量表示,并计算新闻间的相似性,采用注意力机制进一步增强了对文本语义的理解,超越传统的向量表示方法。单变量回归模型如下:
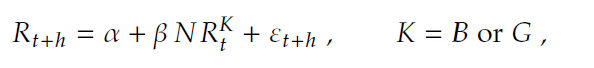
表2显示ChatGPT-3.5识别的新闻文本信息对股票市场的影响,结果表明ChatGPT-3.5识别的坏消息对股市有即时显著影响,而好消息则在1至6个月的预测期内与股市收益呈正相关,这表明好消息对市场的影响存在滞后。换言之,ChatGPT-3.5在辨识和预测市场动态方面表现出其独特的优势,尤其是在揭示潜在的好消息以及市场对此类消息反应的迟钝上。这些发现对于理解市场动态和投资者行为具有重要的学术价值和实际应用意义。
表2 ChatGPT-3.5的预测结果
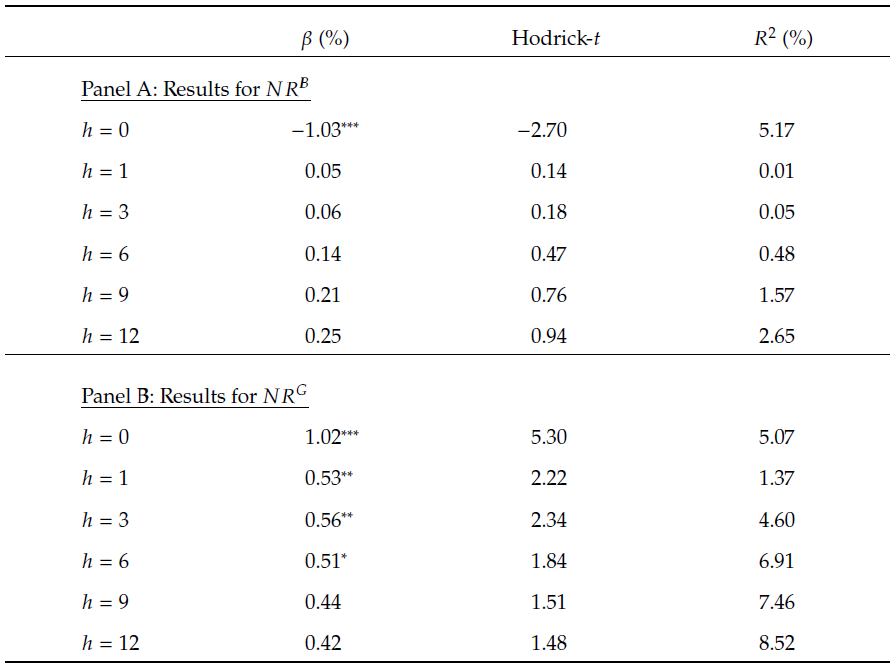
在表3中,利用BERT模型分析的数据结果表明,从文本信息中提取的坏消息比率和好消息比率对股市收益率的影响一般较小。尽管如此,基于好消息比率的同期回归分析显示出一定的影响力。在即时的市场反应中,好消息比率可能会对股市收益率产生一定的正向影响,而这种影响在长期预测中不那么显著。此结果指向了市场对即时信息反应的敏感性,而对长期预测信息的处理则更为复杂。
表3 与其他文本分析方法的比较
图2通过细致的词频分析探讨了ChatGPT-3.5、BERT以及Loughran and McDonald(2011)的词表法确定的好消息、坏消息和未知消息类别中词汇的分布。这一过程包括使用NLTK工具进行文本清洗、词干提取,然后计算和汇总词频,并剔除低频词以计算剩余词的相对频率。结果显示,ChatGPT-3.5能够准确捕捉与金融市场相关的词汇,例如“反弹”、“提高”、“促进”和“支撑”,这些词通常与金融或经济条件有利相关。与之相对,LM词典则倾向于挑选出一般性的积极词汇,如“领导”、“美好”、“改善”和“繁荣”,这些词尽管普遍正面,但与金融背景的关联较弱。相比之下,BERT模型在分类上出现一些误差,比如错误地将一些如“暴跌”和“最低点”等负面词汇归类为正面,存在与经济学直觉不符的分类现象。

图2 各种语言模型识别的词云
以上发现突出ChatGPT-3.5在处理和解释与金融市场相关的复杂文本数据方面的能力,相比传统的词典法或参数较小的语言模型如BERT,显示出明显的优势。
经济解释
04
前文揭示了市场反应的独特模式:如 ChatGPT 模型所确定的那样,对好消息的反应是渐进的,而对坏消息的反应则更为直接。在此基础上,作者进一步探讨了这一现象背后的经济学解释。
表4 预测宏观经济形势
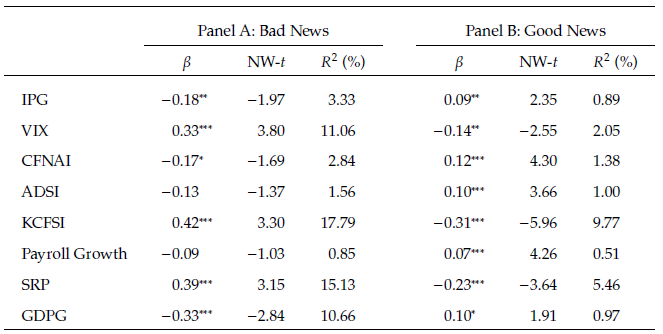
表4探讨了ChatGPT预测股市运动的经济机制,结果表明新闻比率与未来宏观经济状况之间存在显著的相关性。具体而言,好消息比率的提高预示着经济状况的改善,而坏消息比率的上升则指向未来经济状况的恶化。这一结果不仅证明了ChatGPT能够从新闻文本中提取宏观经济状况的相关信息,也表明这些信息能够影响整个股票市场的走势,进一步彰显了ChatGPT在捕捉经济动态方面的潜力。
表5 好消息比率与经济活动之间的交互作用
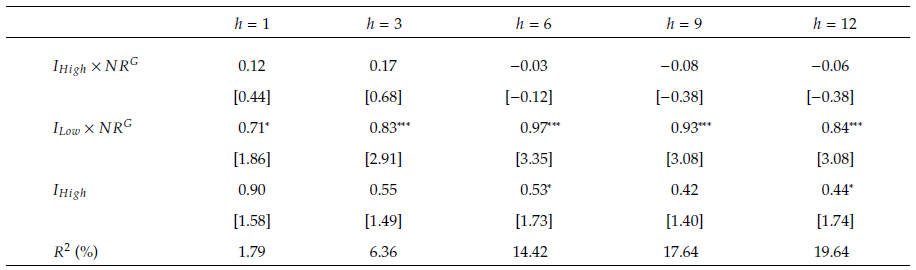
表5表明了经济活动水平与市场对新闻反应之间的关系。尽管在不同预测期限内,高经济活动指标(![]() )与好消息比率(
)与好消息比率(![]() )的交互项系数不显著,但低经济活动指标(
)的交互项系数不显著,但低经济活动指标(![]() )与
)与![]() 的交互项系数在0.71%至0.97%之间,并在90%或更高的置信水平上具有统计学意义。这一结果证实了Veronesi(1999)和García(2013)的研究发现,即在经济衰退期间,
的交互项系数在0.71%至0.97%之间,并在90%或更高的置信水平上具有统计学意义。这一结果证实了Veronesi(1999)和García(2013)的研究发现,即在经济衰退期间,![]() 对股市收益率的预测能力显著增强,这与他们关于经济衰退期间新闻内容预测能力增强的观察结果一致。
对股市收益率的预测能力显著增强,这与他们关于经济衰退期间新闻内容预测能力增强的观察结果一致。
表6 好消息比率与EPU之间的交互作用
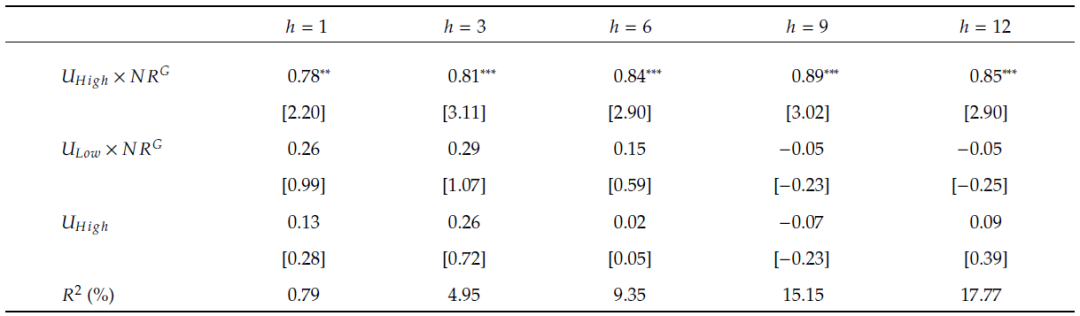
表6通过对正面新闻情感指标(![]() )在不同水平的经济政策不确定性(EPU)下的预测强度进行分析,揭示了
)在不同水平的经济政策不确定性(EPU)下的预测强度进行分析,揭示了![]() 在高EPU时期对股市收益率预测性的显著提升。具体来说,在高EPU时期,
在高EPU时期对股市收益率预测性的显著提升。具体来说,在高EPU时期,![]() 每增加一个标准差,股市收益率平均会增加0.78%至0.89%,这一增幅在统计上具有显著意义,且远高于低EPU时期的0.29%最高收益率增加。这些结果说明高EPU时期,投资者对正面新闻的反应不足,增强了
每增加一个标准差,股市收益率平均会增加0.78%至0.89%,这一增幅在统计上具有显著意义,且远高于低EPU时期的0.29%最高收益率增加。这些结果说明高EPU时期,投资者对正面新闻的反应不足,增强了![]() 的预测能力。
的预测能力。
表7 好消息比率与新闻相似性之间的交互作用
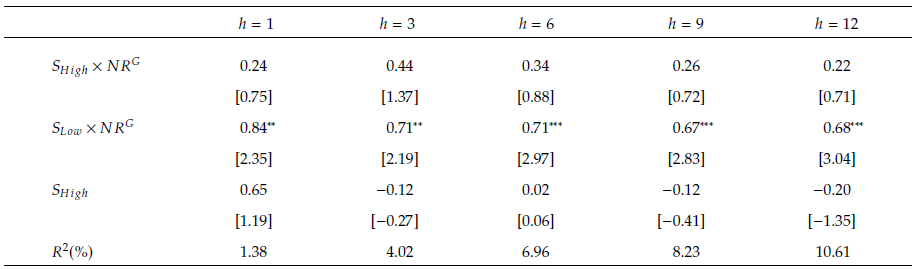
表7进一步强调了经济新闻的新颖性在预测股市收益中的重要作用。特别是,当经济新闻相比以往报告更加新颖时(标记为![]() ),与
),与![]() 相关的系数在0.67%至0.84%之间变化,并在统计上显著(t统计量在2.19至3.04之间)。以上结果表明新颖性高的新闻对市场的预测作用更为明显。这与文献中的观点相符,即市场对新信息的反应是渐进的,而非立即全面地吸收新信息,进一步表明新闻的新颖性是导致投资者对正面新闻反应不足的关键因素,这种反应不足导致新闻信息更加渐进地融入市场反应中。
相关的系数在0.67%至0.84%之间变化,并在统计上显著(t统计量在2.19至3.04之间)。以上结果表明新颖性高的新闻对市场的预测作用更为明显。这与文献中的观点相符,即市场对新信息的反应是渐进的,而非立即全面地吸收新信息,进一步表明新闻的新颖性是导致投资者对正面新闻反应不足的关键因素,这种反应不足导致新闻信息更加渐进地融入市场反应中。
05
结论
本研究应用ChatGPT对1996年至2022年间《华尔街日报》的标题和快讯进行分析,揭示了正面新闻的高识别率与随后六个月内市场回报率之间显著相关。此外,ChatGPT识别的新闻内容与宏观经济状况的相关性更加紧密。相较于BERT或RoBERTa等小型语言模型和传统文本分析方法,大语言模型在信息处理方面表现出更高的效率。尤其在经济衰退期、政策不确定性增加时,以及新闻新颖性提高时,大型语言模型在识别正面新闻方面的优势更为明显,而人类投资者在处理负面新闻方面则显示出更高的效率。以上表明投资者对不同类型新闻的反应存在差异,可能对金融市场产生深远影响。
Abstract
This paper examines whether ChatGPT can identify useful news content for the aggregate stock market and macroeconomy, using the news headlines and alerts on front pages of Wall Street Journal. We find that the information extracted by ChatGPT is highly related to macroeconomic conditions. Investors tend to underreact to the positive contents, especially during periods of economic downturns, high information uncertainty and high novelty of news, which leads to significant market predictability by ChatGPT. By contrast, the negative news is only associated with contemporaneous returns, and it cannot predict future market. Traditional methods of textual analysis, such as word lists or small large language models (LLMs) like BERT, can barely find any predictability in either positive news nor negative news. In short, ChatGPT appears the best of its kind and is capable of discerning economic-related news that drive the stock market.
推文作者:吕志冲,西南交通大学应用经济学硕士,研究方向为金融预测与文本分析,欢迎学术交流。
个人邮箱:。推文内容若存在错误与疏漏,欢迎邮箱批评指正!
声明:推文仅代表文章原作者观点,以及推文作者的评论观点,并不代表香樟经济学术圈公众号平台的观点。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号